本文围绕基于骨骼点的细粒度人体动作识别展开,以花样滑冰数据集为研究对象,采用PaddleVideo的AGCN模型。通过划分训练集与验证集,调整mixup值为0.1,增加BN层加速收敛,并设置初始权重优化模型。经训练与测试,生成submission.csv用于评测,示例模型在A榜得62.89分,为细粒度动作识别提供思路。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

人体运动分析是近几年许多领域研究的热点问题。在学科的交叉研究上,人体运动分析涉及到计算机科学、运动人体科学、环境行为学和材料科学等。随着研究的深入以及计算机视觉、5G通信的飞速发展,人体运动分析技术已应用于自动驾驶、影视创作、安防异常事件监测和体育竞技分析、康复等实际场景人体运动分析已成为人工智能领域研究的前沿课题。目前的研究数据普遍缺少细粒度语义信息,导致现存的分割或识别任务缺少时空细粒度动作语义模型。此类研究在竞技体育、运动康复、日常健身等方面有非常重大的意义。相比于图片的细粒度研究,时空细粒度语义的人体动作具有动作的类内方差大、类间方差小这一特点,这将导致由细粒度语义产生的一系列问题,利用粗粒度语义的识别模型进行学习难得获得理想的结果。
基于实际需求以及图深度学习模型的发展,本比赛旨在构建基于骨骼点的细粒度人体动作识别方法。通过本赛题建立精度高、细粒度意义明确的动作识别模型,希望大家探索时空细粒度模型的新方法。
本项目在baseline的基础上进行调参,使用PaddleVideo建议的优化后的模型AGCN,划分出了验证集,修改了mixup的值,提高了精度,并且增加了BN层,大大加快了收敛速度,同时还设置了权重,下面进行详细的说明
本赛题数据集旨在通过花样滑冰研究人体的运动。在花样滑冰运动中,人体姿态和运动轨迹相较于其他运动呈现复杂性强、类别多的特点,有助于细粒度图深度学习新模型、新任务的研究。
在数据集中,所有的视频素材从2017 到2018 年的花样滑冰锦标赛中采集。源视频素材中视频的帧率被统一标准化至每秒30 帧,并且图像大小是1080 * 720 来保证数据集的相对一致性。之后我们通过2D姿态估计算法Open Pose对视频进行逐帧骨骼点提取,最后以.npy格式保存数据集。
训练数据集与测试数据集的目录结构如下所示:
train_data.npy train_label.npy test_A_data.npy test_B_data.npy # B榜测试集后续公开
其中train_label.npy通过np.load()读取后会得到一个一维张量,每一个元素为一个值在0-29之间的整形变量代表动作的标签;data.npy文件通过np.load()读取后,会得到一个形状为N×C×T×V×M的五维张量,每个维度的具体含义如下:
| 维度符号表示 | 维度值大小 | 维度含义 | 补充说明 |
|---|---|---|---|
| N | 样本数 | 代表N个样本 | 无 |
| C | 3 | 分别代表每个关节点的x,y坐标和置信度 | 每个x,y均被放缩至-1到1之间 |
| T | 1500 | 代表动作的持续时间长度,共有1500帧 | 有的动作的实际长度可能不足1500,例如可能只有500的有效帧数,我们在其后重复补充0直到1500帧,来保证T维度的统一性 |
| V | 25 | 代表25个关节点 | 具体关节点的含义可看下方的骨架示例图 |
| M | 1 | 代表1个运动员个数 | 无 |
骨架示例图:
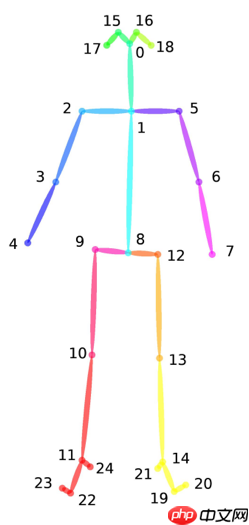
数据集可以从比赛链接处下载,报名成功后,即可获取数据集下载链接。数据集下载完成后,可以将数据集上传到aistudio项目中,上传后的数据集路径在/home/aistudio/data目录下。
如果是直接fork的本项目,在/home/aistudio/data 目录下已经包含了下载好的训练数据和测试数据。
运行下面代码划分好数据集和验证集在data目录下
#划分数据集和验证集# 划分训练集、验证集import numpy as npimport random
random.seed(2021)
Data_DIR = '/home/aistudio/data/data104925/'Train_data = np.load(Data_DIR + 'train_data.npy')
Train_label = np.load(Data_DIR +'train_label.npy')
Split = 0.8print(Train_data.shape, Train_label.shape)
train_data = []
train_label = []
val_data = []
val_label = []for i in range(Train_data.shape[0]): if random.random() < 0.9:
train_data.append(Train_data[i])
train_label.append(Train_label[i]) else:
val_data.append(Train_data[i])
val_label.append(Train_label[i])
train_data, train_label = np.array(train_data), np.array(train_label)
val_data, val_label = np.array(val_data), np.array(val_label)print(train_data.shape, val_data.shape)
np.save('/home/aistudio/data/train_data.npy', train_data)
np.save('/home/aistudio/data/train_label.npy', train_label)
np.save('/home/aistudio/data/val_data.npy', val_data)
np.save('/home/aistudio/data/val_label.npy', val_label)设置好之后配置在work/PaddleVideo/paddlevideo/modeling/heads/base.py中
count = [0 for i in range(30)]for i in range(train_label.shape[0]):
count[train_label[i]] += 1print(count)print((1 / 30 * train_label.shape[0] / np.array(count)).tolist())# 检查数据集所在路径!tree -L 3 /home/aistudio/data
ST-GCN是AAAI 2018中提出的经典的基于骨骼的行为识别模型,不仅为解决基于人体骨架关键点的人类动作识别问题提供了新颖的思路,在标准的动作识别数据集上也取得了较大的性能提升。算法整体框架如下图所示:
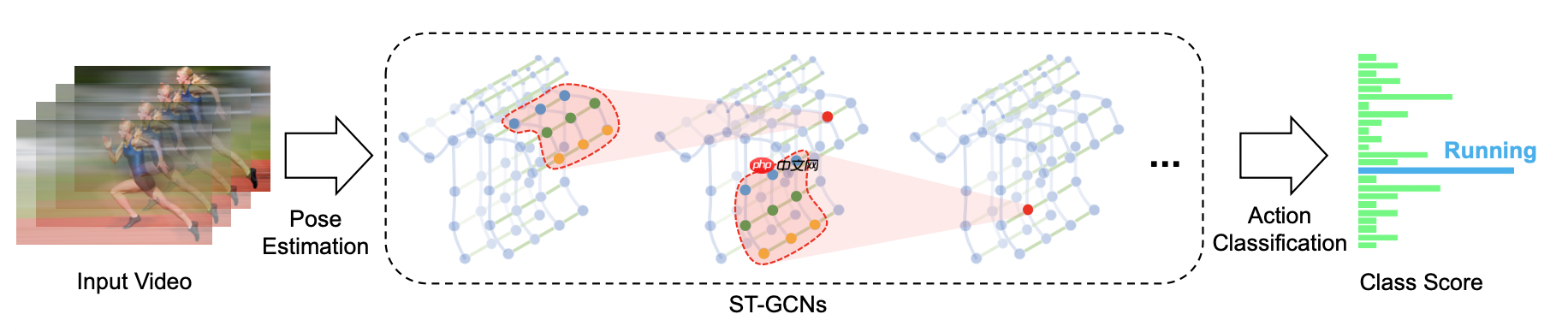
时空图卷积网络模型ST-GCN通过将图卷积网络(GCN)和时间卷积网络(TCN)结合起来,扩展到时空图模型,设计出了用于行为识别的骨骼点序列通用表示,该模型将人体骨骼表示为图,其中图的每个节点对应于人体的一个关节点。图中存在两种类型的边,即符合关节的自然连接的空间边(spatial edge)和在连续的时间步骤中连接相同关节的时间边(temporal edge)。在此基础上构建多层的时空图卷积,它允许信息沿着空间和时间两个维度进行整合。
ST-GCN的网络结构大致可以分为三个部分,首先,对网络输入一个五维矩阵(N,C,T,V;M).其中N为视频数据量;C为关节特征向量,包括(x,y,acc);T为视频中抽取的关键帧的数量;V表示关节的数量,在本项目中采用25个关节数量;M则是一个视频中的人数,然后再对输入数据进行Batch Normalization批量归一化,接着,通过设计ST-GCN单元,引入ATT注意力模型并交替使用GCN图卷积网络和TCN时间卷积网络,对时间和空间维度进行变换,在这一过程中对关节的特征维度进行升维,对关键帧维度进行降维,最后,通过调用平均池化层、全连接层,并后接SoftMax层输出,对特征进行分类。

图卷积网络(Graph Convolutional Network,GCN)借助图谱的理论来实现空间拓扑图上的卷积,提取出图的空间特征,具体来说,就是将人体骨骼点及其连接看作图,再使用图的邻接矩阵、度矩阵和拉普拉斯矩阵的特征值和特征向量来研究该图的性质。 在原论文中,作者提到他们使用了「Kipf, T. N., and Welling, M. 2017. Semi-supervised classification with graph convolutional networks. In ICLR 2017」中的GCN架构,其图卷积数学公式如下:
其中,fout为输出,A为邻接矩阵,I为单位矩阵,Aii= ∑j(Aij+Iij), W是需要学习的空间矩阵。 原文中,作者根据不同的动作划分为了三个子图(A1,A2,A3),分别表达向心运动、离心运动和静止的动作特征。
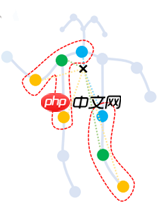
在实际的应用中,最简单的图卷积已经能达到很好的效果,所以实现中采用的是D−1A图卷积核。D为度矩阵。
ST-GCN单元通过GCN学习空间中相邻关节的局部特征,而时序卷积网络(Temporal convolutional network,TCN)则用于学习时间中关节变化的局部特征。卷积核先完成一个节点在其所有帧上的卷积,再移动到下一个节点,如此便得到了骨骼点图在叠加下的时序特征。对于TCN网络,项目中通过使用9×1的卷积核进行实现。为了保持总体的特征量不变,当关节点特征向量维度(C)成倍变化时,步长取2,其余情况步长取1。
%cd ~/work !git clone https://hub.fastgit.org/PaddlePaddle/PaddleVideo.git
# 进入到gitclone 的PaddleVideo目录下%cd ~/work/PaddleVideo/
# 检查源代码文件结构!tree /home/aistudio/work/ -L 2
!python3.7 -m pip install --upgrade pip !python3.7 -m pip install --upgrade -r requirements.txt
初始权重:
def label_smooth_loss(self, scores, labels, **kwargs):
labels = F.one_hot(labels, self.num_classes)
labels = F.label_smooth(labels, epsilon=self.ls_eps)
labels = paddle.squeeze(labels, axis=1)
weight = [0.7157407407407407, 0.7361904761904762, 0.6901785714285714, 4.294444444444444, 0.6550847457627118, 0.7027272727272728, 1.8853658536585365, 1.4865384615384616, 0.7504854368932039, 0.6606837606837607, 1.4314814814814814, 0.7224299065420561, 4.83125, 0.7027272727272728, 5.153333333333333, 1.7177777777777776, 0.991025641025641, 2.147222222222222, 0.6606837606837607, 1.1202898550724638, 2.7607142857142857, 0.8136842105263158, 0.7027272727272728, 0.7091743119266055, 2.4935483870967743, 3.092, 0.7091743119266055, 0.6606837606837607, 1.3803571428571428, 0.7157407407407407]#(需要大家手动修改)
loss = self.loss_func(scores, labels, soft_label=True,weight=paddle.to_tensor(np.array(weight)), **kwargs)
return lossPaddleVideo 通过yaml配置文件的方式选择不同的算法和训练参数等,这里我们使用configs/recognition/stgcn/stgcn_fsd.yaml配置文件完成ST-GCN模型算法训练。从该配置文件中,我们可以得到如下信息:
MODEL: #MODEL field
framework: "RecognizerGCN" #Mandatory, indicate the type of network, associate to the 'paddlevideo/modeling/framework/' .
backbone: #Mandatory, indicate the type of backbone, associate to the 'paddlevideo/modeling/backbones/' .
name: "AGCN" #Mandatory, The name of backbone.
head:
name: "STGCNHead" #Mandatory, indicate the type of head, associate to the 'paddlevideo/modeling/heads'
num_classes: 30 #Optional, the number of classes to be classified.
ls_eps: 0.1表示我们使用的是AGCN算法,framework为RecognizerGCN,backbone是时空图卷积网络AGCN,head使用对应的STGCNHead,损失函数是CrossEntropyLoss。
DATASET: #DATASET field
batch_size: 32 #Mandatory, bacth size
num_workers: 4 #Mandatory, the number of subprocess on each GPU.
test_batch_size: 1
test_num_workers: 0
train:
format: "SkeletonDataset" #Mandatory, indicate the type of dataset, associate to the 'paddlevidel/loader/dateset'
file_path: "/home/aistudio/data/train_data.npy" #Mandatory, train data index file path()
label_path: "/home/aistudio/data/train_label.npy"#(手动设置)
valid:
format: "SkeletonDataset" #Mandatory, indicate the type of dataset, associate to the 'paddlevidel/loader/dateset'
file_path: "/home/aistudio/data/val_data.npy" #Mandatory, train data index file path()
label_path: "/home/aistudio/data/val_label.npy"#(需要大家手动增加)
test:
format: "SkeletonDataset" #Mandatory, indicate the type of dataset, associate to the 'paddlevidel/loader/dateset'
file_path: "/home/aistudio/data/data104924/test_A_data.npy" #Mandatory, valid data index file path#(手动设置)
test_mode: True训练数据路径通过DATASET.train.file_path字段指定,训练标签路径通过DATASET.train.label_path字段指定,验证集数据通过DATASET.valid.file_path,验证集标签路径通过DATASET.valid.label_path字段指定,测试数据路径通过DATASET.test.file_path字段指定。这五个路径需要用户在配置文件configs/recognition/stgcn/stgcn_fsd.yaml中手动配置好。本项目中路径示例如上所示。
PIPELINE: #PIPELINE field
train: #Mandotary, indicate the pipeline to deal with the training data, associate to the 'paddlevideo/loader/pipelines/'
sample:
name: "AutoPadding"
window_size: 300
transform: #Mandotary, image transfrom operator
- SkeletonNorm:
valid: #Mandotary, indicate the pipeline to deal with the training data, associate to the 'paddlevideo/loader/pipelines/'
sample:
name: "AutoPadding"
window_size: 300
transform: #Mandotary, image transfrom operator
- SkeletonNorm: #(需要大家手动增加)
test: #Mandatory, indicate the pipeline to deal with the validing data. associate to the 'paddlevideo/loader/pipelines/'
sample:
name: "AutoPadding"
window_size: 300
transform: #Mandotary, image transfrom operator
- SkeletonNorm:数据处理主要包括两步操作,分别为SampleFrame和SkeletonNorm。
OPTIMIZER: #OPTIMIZER field name: 'Momentum' momentum: 0.9 learning_rate: iter_step: True name: 'CustomWarmupCosineDecay' max_epoch: 150 warmup_epochs: 10 warmup_start_lr: 0.01 cosine_base_lr: 0.05 weight_decay: name: 'L2' value: 1e-4MIX: name: "Mixup" alpha: 0.1 #(需要大家手动更改)PRECISEBN: preciseBN_interval: 5 # epoch interval to do preciseBN, default 1. num_iters_preciseBN: 200 # how many batches used to do preciseBN, default 200.#(需要大家手动增加)
本项目根据直播中的内容,参照了ppstm,增加了BN层,加快了收敛速度,mixup的默认值是0.2,调成0.1效果最好, 网络训练使用的优化器为Momentum,学习率更新策略为CosineAnnealingDecay。
关于yaml的更多细节,可以参考PaddleVideo
%%writefile agcn_fsd_finally.yaml
MODEL: #MODEL field
framework: "RecognizerGCN" #Mandatory, indicate the type of network, associate to the 'paddlevideo/modeling/framework/' .
backbone: #Mandatory, indicate the type of backbone, associate to the 'paddlevideo/modeling/backbones/' .
name: "AGCN" #Mandatory, The name of backbone.
head:
name: "STGCNHead" #Mandatory, indicate the type of head, associate to the 'paddlevideo/modeling/heads'
num_classes: 30 #Optional, the number of classes to be classified.
ls_eps: 0.1DATASET: #DATASET field
batch_size: 32 #Mandatory, bacth size
num_workers: 4 #Mandatory, the number of subprocess on each GPU.
test_batch_size: 1
test_num_workers: 0
train: format: "SkeletonDataset" #Mandatory, indicate the type of dataset, associate to the 'paddlevidel/loader/dateset'
file_path: "/home/aistudio/data/train_data.npy" #Mandatory, train data index file path
label_path: "/home/aistudio/data/train_label.npy"
valid: format: "SkeletonDataset" #Mandatory, indicate the type of dataset, associate to the 'paddlevidel/loader/dateset'
file_path: "/home/aistudio/data/val_data.npy" #Mandatory, train data index file path
label_path: "/home/aistudio/data/val_label.npy"
test: format: "SkeletonDataset" #Mandatory, indicate the type of dataset, associate to the 'paddlevidel/loader/dateset'
file_path: "/home/aistudio/data/data104924/test_A_data.npy" #Mandatory, valid data index file path
test_mode: TruePIPELINE: #PIPELINE field
train: #Mandotary, indicate the pipeline to deal with the training data, associate to the 'paddlevideo/loader/pipelines/'
sample:
name: "AutoPadding"
window_size: 300
transform: #Mandotary, image transfrom operator
- SkeletonNorm:
valid: #Mandotary, indicate the pipeline to deal with the training data, associate to the 'paddlevideo/loader/pipelines/'
sample:
name: "AutoPadding"
window_size: 300
transform: #Mandotary, image transfrom operator
- SkeletonNorm:
test: #Mandatory, indicate the pipeline to deal with the validing data. associate to the 'paddlevideo/loader/pipelines/'
sample:
name: "AutoPadding"
window_size: 300
transform: #Mandotary, image transfrom operator
- SkeletonNorm:
OPTIMIZER: #OPTIMIZER field
name: 'Momentum'
momentum: 0.9
learning_rate:
iter_step: True
name: 'CustomWarmupCosineDecay'
max_epoch: 150
warmup_epochs: 10
warmup_start_lr: 0.01
cosine_base_lr: 0.05
weight_decay:
name: 'L2'
value: 1e-4MIX:
name: "Mixup"
alpha: 0.1# PRECISEBN:# preciseBN_interval: 5 # epoch interval to do preciseBN, default 1.# num_iters_preciseBN: 200 # how many batches used to do preciseBN, default 200.METRIC:
name: 'SkeletonMetric'
out_file: 'submission.csv'INFERENCE:
name: 'STGCN_Inference_helper'
num_channels: 2
window_size: 300
vertex_nums: 25
person_nums: 1model_name: "AGCN"log_interval: 10 #Optional, the interal of logger, default:10epochs: 150 #Mandatory, total epochWriting agcn_fsd_finally.yaml
ST-GCN模型的使用文档可参考ST-GCN基于骨骼的行为识别模型。
!python3.7 main.py -c configs/recognition/agcn/agcn_fsd.yaml --valid
你将会看到类似如下的训练日志
[10/21 11:07:59] epoch:[ 1/150] train step:0 loss: 3.40092 lr: 0.010000 top1: 0.00000 top5: 0.18750 batch_cost: 1.45506 sec, reader_cost: 1.11670 sec, ips: 21.99219 instance/sec. [10/21 11:08:02] epoch:[ 1/150] train step:10 loss: 3.33815 lr: 0.010481 top1: 0.09375 top5: 0.31250 batch_cost: 0.27829 sec, reader_cost: 0.00028 sec, ips: 114.98913 instance/sec. [10/21 11:08:05] epoch:[ 1/150] train step:20 loss: 3.40411 lr: 0.010962 top1: 0.06250 top5: 0.25000 batch_cost: 0.27801 sec, reader_cost: 0.00070 sec, ips: 115.10392 instance/sec. [10/21 11:08:08] epoch:[ 1/150] train step:30 loss: 3.50433 lr: 0.011443 top1: 0.03125 top5: 0.24827 batch_cost: 0.27865 sec, reader_cost: 0.00069 sec, ips: 114.84096 instance/sec. [10/21 11:08:10] epoch:[ 1/150] train step:40 loss: 3.33809 lr: 0.011925 top1: 0.02898 top5: 0.24091 batch_cost: 0.27804 sec, reader_cost: 0.00070 sec, ips: 115.09039 instance/sec. [10/21 11:08:13] epoch:[ 1/150] train step:50 loss: 3.19748 lr: 0.012406 top1: 0.12128 top5: 0.48510 batch_cost: 0.27738 sec, reader_cost: 0.00023 sec, ips: 115.36322 instance/sec. [10/21 11:08:16] epoch:[ 1/150] train step:60 loss: 3.14063 lr: 0.012887 top1: 0.09375 top5: 0.37500 batch_cost: 0.27884 sec, reader_cost: 0.00047 sec, ips: 114.76230 instance/sec. [10/21 11:08:19] epoch:[ 1/150] train step:70 loss: 3.53940 lr: 0.013368 top1: 0.15625 top5: 0.37500 batch_cost: 0.27831 sec, reader_cost: 0.00026 sec, ips: 114.97869 instance/sec. [10/21 11:08:22] epoch:[ 1/150] train step:80 loss: 3.42437 lr: 0.013849 top1: 0.03125 top5: 0.34375 batch_cost: 0.27682 sec, reader_cost: 0.00020 sec, ips: 115.60050 instance/sec. [10/21 11:08:22] END epoch:1 train loss_avg: 3.32960 top1_avg: 0.04772 top5_avg: 0.31779 avg_batch_cost: 0.27725 sec, avg_reader_cost: 0.00054 sec, batch_cost_sum: 23.98186 sec, avg_ips: 109.41603 instance/sec.
请使用GPU版本的配置环境运行本模块
!python3.7 main.py -c agcn_fsd_finally.yaml --valid
模型训练完成后,可使用测试脚本进行评估, 由于设置了验证集,会将最好的模型保存成AGCN__best.pdparams,测试时直接调用就好
!python3.7 main.py --test -c configs/recognition/agcn/agcn_fsd.yaml -w output/AGCN/AGCN_best.pdparams
通过-c参数指定配置文件,通过-w指定权重存放路径进行模型测试。
评估结果保存在submission.csv文件中,可在评测官网提交查看得分。
!python3.7 main.py --test -c agcn_fsd_finally.yaml -w output/AGCN/AGCN_best.pdparams
# 本代码使用训练好的模型进行测试,示例如下:# 下载训练好的模型(这里希望大家不要用,本人就曾经试过一次,结果被官网判成违规)!wget https://videotag.bj.bcebos.com/PaddleVideo-release2.2/AGCN_fsd.pdparams
# 通过-w参数指定模型权重进行测试!python3.7 main.py --test -c agcn_fsd_finally.yaml -w AGCN_fsd.pdparams.1
测试脚本运行完成后,可以在当前目录中得到submission.csv文件,将该文件提交至评测官网,即可以查看在A榜得分。示例给出的模型文件,在A榜的得分为62.89。
以上就是【Paddle打比赛】花样滑冰选手骨骼点动作识别(验证集方案)-62.89分的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 278
278























