本文介绍逻辑回归,这是一种分类算法。它通过Sigmoid函数将线性回归结果映射到[0,1],以概率形式分类。损失函数为对数似然函数,用随机梯度下降或牛顿法优化。其优势在于输出概率、可解释性强等,应用于CTR预估等场景。还展示了自定义函数及调用sklearn的实现代码与结果。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

import numpy as npimport matplotlib.pyplot as plt
x = np.arange(-5.0 , 5.0 , 0.02)
y = 1 / (1 + np.exp(-x))
plt.xlabel('x')
plt.ylabel('y = Sigmoid(x)')
plt.title('Sigmoid')
plt.plot(x , y)
plt.show()<Figure size 432x288 with 1 Axes>
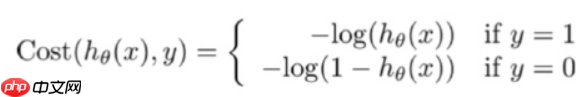
from math import expimport numpy as npimport pandas as pdimport matplotlib.pyplot as plt %matplotlib inlinefrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_split
# datadef create_data():
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['label'] = iris.target
df.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label']
data = np.array(df.iloc[:100, [0,1,-1]]) # print(data)
return data[:,:2], data[:,-1]X, y = create_data() X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
import math
class LogisticReressionClassifier:
def __init__(self, max_iter=200, learning_rate=0.02):
self.max_iter = max_iter
self.learning_rate = learning_rate
# sigmoid激活函数
def sigmoid(self, x):
return 1 / (1 + exp(-x)) def data_matrix(self, X):
data_mat = [] for d in X:
data_mat.append([1.0, *d]) return data_mat def fit(self, X, y):
# label = np.mat(y)
data_mat = self.data_matrix(X) # m*n
self.weights = np.zeros((len(data_mat[0]),1), dtype=np.float32) for iter_ in range(self.max_iter): for i in range(len(X)):
result = self.sigmoid(np.dot(data_mat[i], self.weights))
error = y[i] - result
self.weights += self.learning_rate * error * np.transpose([data_mat[i]]) print('LogisticRegression Model(learning_rate={},max_iter={})'.format(self.learning_rate, self.max_iter)) # def f(self, x):
# return -(self.weights[0] + self.weights[1] * x) / self.weights[2]
def score(self, X_test, y_test):
right = 0
X_test = self.data_matrix(X_test) for x, y in zip(X_test, y_test):
result = np.dot(x, self.weights) if (result > 0 and y == 1) or (result < 0 and y == 0):
right += 1
return right / len(X_test)lr_clf = LogisticReressionClassifier() lr_clf.fit(X_train, y_train)
LogisticRegression Model(learning_rate=0.02,max_iter=200)
lr_clf.score(X_test, y_test)
0.9666666666666667
x_ponits = np.arange(4, 8) y_ = -(lr_clf.weights[1]*x_ponits + lr_clf.weights[0])/lr_clf.weights[2] plt.plot(x_ponits, y_)#lr_clf.show_graph()plt.scatter(X[:50,0],X[:50,1], label='0') plt.scatter(X[50:,0],X[50:,1], label='1') plt.legend()
<matplotlib.legend.Legend at 0x7f232f7e6590>
<Figure size 432x288 with 1 Axes>
- sklearn.linear_model.LogisticRegression参数
solver参数决定了我们对逻辑回归损失函数的优化方法,有四种算法可以选择,分别是:
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression(max_iter=200)
clf.fit(X_train, y_train)
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, l1_ratio=None, max_iter=200,
multi_class='auto', n_jobs=None, penalty='l2',
random_state=None, solver='lbfgs', tol=0.0001, verbose=0,
warm_start=False)clf.score(X_test, y_test)
1.0
print(clf.coef_, clf.intercept_)
[[ 2.69741404 -2.61019199]] [-6.44843344]
x_ponits = np.arange(4, 8)
y_ = -(clf.coef_[0][0]*x_ponits + clf.intercept_)/clf.coef_[0][1]
plt.plot(x_ponits, y_)
plt.plot(X[:50, 0], X[:50, 1], 'bo', color='blue', label='0')
plt.plot(X[50:, 0], X[50:, 1], 'bo', color='orange', label='1')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend()<matplotlib.legend.Legend at 0x7f1d10e65dd0>
<Figure size 432x288 with 1 Axes>
以上就是“机器学习”系列之Logistic Regression (逻辑回归)的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 278
278























