本文介绍基于ResNet50网络判断中药炮制饮片质量的研究。使用成都中医药大学提供的蒲黄、山楂、王不留行3个品种,各含生品、不及、适中、太过4种状态的共6097张图片数据集,经预处理后划分训练集和测试集。构建含预训练ResNet50和全连接层的模型,用Adam优化器等训练,最终准确率达97.3%,实现炮制经验智能化传承。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

中药炮制是根据中医药理论,依照临床辨证施治用药的需要和药物自身性质,以及调剂、制剂的不同要求,将中药材制备成中药饮片所采取的一项制药技术。平时我们老百姓能接触到的中药,主要指自己回家煎煮或者请医院代煎煮的中药,都是中药饮片,也就是中药炮制这个技术的结果。而中药炮制饮片,大部分涉及到水火的处理,一定需要讲究“程度适中”,炮制火候不够达不到最好药效,炮制火候过度也会丧失药效。
过去的炮制饮片程度的判断,都是采用的老药工经验判断,但随着老药工人数越来越少,这种经验判断可能存在“失传”的风险。而随着人工智能的发展,使用深度神经网络模型对饮片状态进行判断能达到很好的效果,可以很好的实现经验的“智能化”和经验的传承。本产品基于PaddlePaddle3.0通过使用ResNet50网络进行中药分拣,对饮片状态进行自动判断,实现经验的“智能化”和经验的传承。
我们使用“中药炮制饮片”数据集,该数据集由成都中医药大学提供,共包含中药炮制饮片的 3 个品种,分别为:蒲黄、山楂、王不留行,每个品种又有着4种炮制状态:生品、不及适中、太过,每类包含 500 张图片共12类5000张图片,图片格式为 jpg。 下面是数据集中的一些样例图片:

!unzip data/data298711/images.zip -d work/images
import paddlefrom paddle.io import Datasetimport matplotlib.pyplot as pltimport PIL.Image as Image path='/home/aistudio/work/images/ph_bj/IMG_1762.JPG'img = Image.open(path) plt.imshow(img) #根据数组绘制图像plt.show() #显示图像print(img.size)
<Figure size 640x480 with 1 Axes>
(1000, 1000)
本部分地建立了图像文件路径与其对应标签索引之间的映射关系,并将数据集打乱以消除顺序相关性,为后续的训练准备了去序列化的样本数据;
同时通过打印输出,确认了样本数据的有效性和数量;
由于平台字体问题,无法正确显示中文,这里给出英文标签对应的类别:
#以下代码用于建立样本数据读取路径与样本标签之间的关系import osimport random
data_list = [] #用个列表保存每个样本的读取路径、标签#获取work目录下的所有子目录名称,保存进一个列表之中class_list = os.listdir("/home/aistudio/work/images")
class_label_list=['ph_bj','ph_sp','ph_sz','ph_tg','sz_bj','sz_sp','sz_sz','sz_tg','wblx_bj','wblx_sp','wblx_sz','wblx_tg']for each in class_list: for f in os.listdir("/home/aistudio/work/images/"+each):
label=each
label_index=class_label_list.index(label) # print(label,label_index)
data_list.append(["/home/aistudio/work/images/"+each+'/'+f,label_index])#按文件顺序读取,可能造成很多属种图片存在序列相关,用random.shuffle方法把样本顺序彻底打乱。random.shuffle(data_list)#打印前十个,可以看出data_list列表中的每个元素是[样本读取路径, 样本标签]。print(data_list[0:10])#打印样本数量,一共有2340个样本。print("样本数量是:{}".format(len(data_list)))[['/home/aistudio/work/images/ph_bj/IMG_20221212_203008.jpg', 0], ['/home/aistudio/work/images/ph_sp/IMG_20221212_194947.JPG', 1], ['/home/aistudio/work/images/ph_sz/IMG_3606.JPG', 2], ['/home/aistudio/work/images/sz_tg/IMG_5979.JPG', 7], ['/home/aistudio/work/images/wblx_sp/IMG_20230220_151228.jpg', 9], ['/home/aistudio/work/images/wblx_tg/IMG_20230220_112000.jpg', 11], ['/home/aistudio/work/images/sz_sp/IMG_5390.JPG', 5], ['/home/aistudio/work/images/wblx_sp/IMG_20230220_103938_3.JPG', 9], ['/home/aistudio/work/images/sz_sz/IMG_3225.JPG', 6], ['/home/aistudio/work/images/ph_tg/IMG_3983.JPG', 3]] 样本数量是:6097
本部分操作通过计算每个类别的样本数量并使用matplotlib库绘制条形图,直观展示了数据集中各类别的分布情况;
首先统计了每个标签的频次,然后创建了一个条形图,其中横轴表示标签,纵轴表示对应的样本数量;
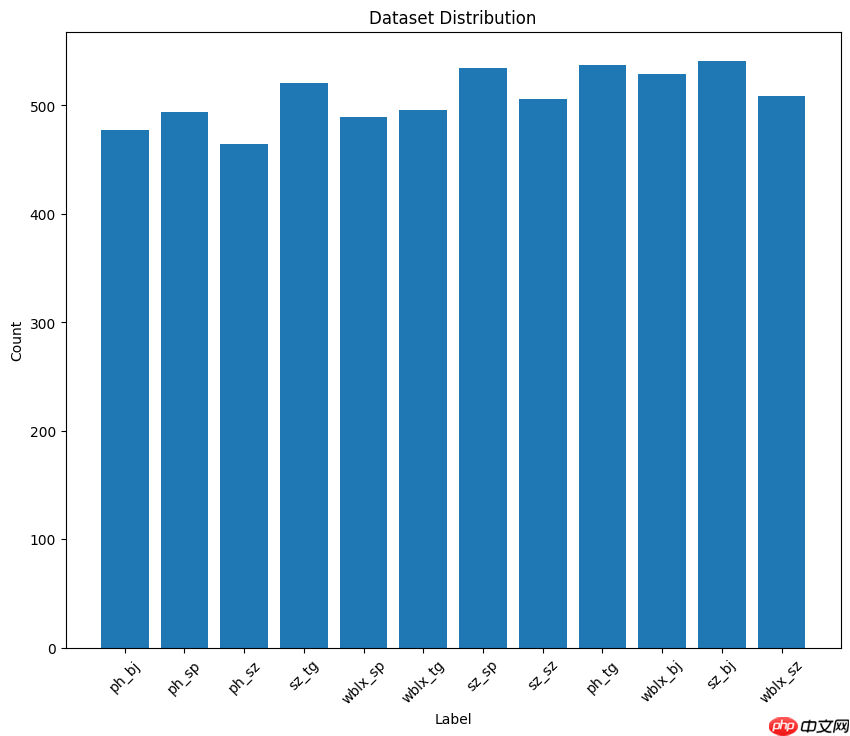
import matplotlib.pyplot as plt# 计算每个标签的样本数量label_counts = {}for _, label_index in data_list: if label_index in label_counts:
label_counts[label_index] += 1
else:
label_counts[label_index] = 1# 将标签索引转换回标签名称label_names = class_label_list
label_counts = {label_names[key]: value for key, value in label_counts.items()}# 创建条形图plt.figure(figsize=(10, 8))
plt.bar(label_counts.keys(), label_counts.values(), tick_label=label_counts.keys())
plt.xlabel('Label')
plt.ylabel('Count')
plt.title('Dataset Distribution')
plt.xticks(rotation=45)
plt.show()本部分代码先是定义了一个数据预处理函数和一个自定义的数据读取器类,用于构造数据读取器和进行数据预处理;
通过Reader类,将数据集划分为训练集和测试集,并实现了数据的加载、预处理和标签转换,输出处理后的图像和标签供模型训练和评估使用;
同时,打印了训练集和测试集的大小以及一个样本的图像形状和标签,验证了数据读取器的正确性;
#以下代码用于构造读取器与数据预处理#首先需要导入相关的模块import paddlefrom paddle.vision.transforms import Compose, ColorJitter, Resize,Transpose, Normalizeimport cv2import numpy as npfrom PIL import Imagefrom paddle.io import Dataset# 自定义的数据预处理函数,输入原始图像,输出处理后的图像,可以借用paddle.vision.transforms的数据处理功能def preprocess(img):
transform = Compose([
Resize(size=(224, 224)), # 把数据长宽像素调成224*224
Normalize(mean=[127.5, 127.5, 127.5], std=[127.5, 127.5, 127.5], data_format='HWC'), # 标准化
Transpose(), # 原始数据形状维度是HWC格式,经过Transpose,转换为CHW格式
])
img = transform(img).astype("float32") return img# 自定义数据读取器class Reader(Dataset):
def __init__(self, data, is_val=False):
super().__init__() # 在初始化阶段,把数据集划分训练集和测试集。
# 由于在读取前样本已经被打乱顺序,取20%的样本作为测试集,80%的样本作为训练集。
self.samples = data[-int(len(data)*0.2):] if is_val else data[:-int(len(data)*0.2)] def __getitem__(self, idx):
#处理图像
img_path = self.samples[idx][0] #得到某样本的路径
img = Image.open(img_path) if img.mode != 'RGB':
img = img.convert('RGB')
img = preprocess(img) #数据预处理--这里仅包括简单数据预处理,没有用到数据增强
#处理标签
label = self.samples[idx][1] #得到某样本的标签
label = np.array([label],dtype='int64') #把标签数据类型转成int64
return img, label def __len__(self):
#返回每个Epoch中图片数量
return len(self.samples)#生成训练数据集实例train_dataset = Reader(data_list, is_val=False)#生成测试数据集实例eval_dataset = Reader(data_list, is_val=True)#打印一个训练样本print(len(train_dataset)) # 1872#打印一个测试样本print(len(eval_dataset)) # 234print(train_dataset[1136][0].shape)print(train_dataset[1136][1])print(type(train_dataset[1136][1]))4878 1219 (3, 224, 224) [11] <class 'numpy.ndarray'>
ResNet50网络是2015年由微软实验室的何恺明提出,获得ILSVRC2015图像分类竞赛第一名。在ResNet网络提出之前,传统的卷积神经网络都是将一系列的卷积层和池化层堆叠得到的,但当网络堆叠到一定深度时,就会出现退化问题。下图是在CIFAR-10数据集上使用56层网络与20层网络训练误差和测试误差图,由图中数据可以看出,56层网络比20层网络训练误差和测试误差更大,随着网络的加深,其误差并没有如预想的一样减小。
ResNet网络提出了残差网络结构(Residual Network)来减轻退化问题,使用ResNet网络可以实现搭建较深的网络结构(突破1000层)。论文中使用ResNet网络在CIFAR-10数据集上的训练误差与测试误差图如下图所示,图中虚线表示训练误差,实线表示测试误差。由图中数据可以看出,ResNet网络层数越深,其训练误差和测试误差越小。
残差结构是ResNet网络中最重要的结构,其结构图如下图所示,残差网络由两个分支构成:一个主分支,一个shortcuts(图中弧线表示)。主分支通过堆叠一系列的卷积操作得到,shortcuts从输入直接到输出,主分支的输出与shortcuts的输出相加后通过Relu激活函数后即为残差网络最后的输出。
残差网络结构主要由两种,一种是Building Block,适用于较浅的ResNet网络,如ResNet18和ResNet34;另一种是Bottleneck,适用于层数较深的ResNet网络,如ResNet50、ResNet101和ResNet152。
Building Block结构图如下图所示,主分支有两层卷积网络结构:
主分支第一层网络以输入channel为64为例,首先通过一个3×3的卷积层,然后通过Batch Normalization层,最后通过Relu激活函数层,输出channel为64;
主分支第二层网络的输入channel为64,首先通过一个3×3的卷积层,然后通过Batch Normalization层,输出channel为64。
最后将主分支输出的特征矩阵与shortcuts输出的特征矩阵相加,通过Relu激活函数即为Building Block最后的输出。
定义一个基于ResNet50的自定义神经网络模型,其中利用了预训练的ResNet50作为特征提取器;
由于本任务为12分类,因此添加了一个全连接层以适应12个类别的分类任务;
模型的前向传播方法定义了数据如何通过这些层,实现了从输入到输出的计算过程;

#定义模型class MyNet(paddle.nn.Layer):
def __init__(self):
super(MyNet,self).__init__()
self.layer=paddle.vision.models.resnet50(pretrained=True)
self.fc = paddle.nn.Linear(1000, 12) #网络的前向计算过程
def forward(self,x):
x=self.layer(x)
x=self.fc(x) return x1、定义模型输入规格,实例化自定义的MyNet模型,并使用PaddlePaddle的高级API paddle.Model 进行了封装;
2、配置Adam优化器和交叉熵损失函数,设置准确率作为评估指标,并在GPU上进行了模型的训练和评估;
3、设置日志打印频率和模型保存频率,指定模型保存目录;
通过观察训练过程,准确度高达97.3%!
step 77/77 - loss: 0.7499 - acc: 0.9440 - 759ms/step Eval begin... step 20/20 - loss: 3.6955e-06 - acc: 0.9737 - 712ms/step Eval samples: 1219 Epoch 15/15
# 定义输入input_define = paddle.static.InputSpec(shape=[-1,3,224,224], dtype="float32", name="img")
label_define = paddle.static.InputSpec(shape=[-1,1], dtype="int64",name="label")# 实例化网络对象并定义优化器等训练逻辑model = MyNet()
model = paddle.Model(model,inputs=input_define,labels=label_define) # 用Paddle.Model()对模型进行封装optimizer = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())# 上述优化器中的学习率(learning_rate)参数很重要。要是训练过程中得到的准确率呈震荡状态,忽大忽小,可以试试进一步把学习率调低。place = paddle.CUDAPlace(0) # 使用第一个GPU设备model.prepare(optimizer=optimizer, # 指定优化器
loss=paddle.nn.CrossEntropyLoss(), # 指定损失函数
metrics=paddle.metric.Accuracy()) # 指定评估方法model.fit(train_data=train_dataset, # 训练数据集
eval_data=eval_dataset, # 测试数据集
batch_size=64, # 一个批次的样本数量
epochs=15, # 迭代轮次
save_dir="/home/aistudio/model/", # 把模型参数、优化器参数保存至自定义的文件夹
save_freq=2, # 设定每隔多少个epoch保存模型参数及优化器参数
log_freq=100, # 打印日志的频率)1、定义一个用于推理的数据集类InferDataset,接受单个图像路径并进行预处理;
2、这个类继承自PaddlePaddle的Dataset类,提供了单张图像的读取和预处理功能,方便模型对单个图像进行预测;
class InferDataset(Dataset):
def __init__(self, img_path=None):
"""
数据读取Reader(推理)
:param img_path: 推理单张图片
"""
super().__init__() if img_path:
self.img_paths = [img_path] else: raise Exception("请指定需要预测对应图片路径") def __getitem__(self, index):
# 获取图像路径
img_path = self.img_paths[index] # 使用Pillow来读取图像数据并转成Numpy格式
img = Image.open(img_path) if img.mode != 'RGB':
img = img.convert('RGB')
img = preprocess(img) #数据预处理--这里仅包括简单数据预处理,没有用到数据增强
return img def __len__(self):
return len(self.img_paths)import matplotlib.pyplot as pltfrom PIL import Image#实例化推理模型input_define = paddle.static.InputSpec(shape=[-1,3,224,224], dtype="float32", name="img")
model = paddle.Model(MyNet(),inputs=input_define)#读取刚刚训练好的参数model.load('/home/aistudio/model/final')#准备模型model.prepare()#利用训练好的模型进行预测infer_path='/home/aistudio/work/images/wblx_sp/IMG_20230220_103938_15.JPG'infer_data = InferDataset(infer_path)
result = model.predict(test_data=infer_data)[0] #关键代码,实现预测功能result = paddle.to_tensor(result)
result = np.argmax(result.numpy()) #获得最大值所在的序号class_label_list=['ph_bj','ph_sp','ph_sz','ph_tg','sz_bj','sz_sp','sz_sz','sz_tg','wblx_bj','wblx_sp','wblx_sz','wblx_tg']
label_description_dict = { 'ph_sp': '蒲黄-生品', 'ph_bj': '蒲黄-不及', 'ph_sz': '蒲黄-适中', 'ph_tg': '蒲黄-太过', 'sz_sp': '山楂-生品', 'sz_bj': '山楂-不及', 'sz_sz': '山楂-适中', 'sz_tg': '山楂-太过', 'wblx_sp': '王不留行-生品', 'wblx_bj': '王不留行-不及', 'wblx_sz': '王不留行-适中', 'wblx_tg': '王不留行-太过'}print('识别结果为:'+label_description_dict[class_label_list[result]])# 使用Pillow库读取图像img = Image.open(infer_path)# 显示图像plt.figure(figsize=(8, 6))
plt.imshow(img)
plt.axis('off') # 不显示坐标轴plt.show()Predict begin... step 1/1 [==============================] - 33ms/step Predict samples: 1 识别结果为:王不留行-生品
<Figure size 800x600 with 1 Axes>
以上就是【药智甄选】PaddlePaddle3.0助力实现ResNet50中药分拣的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 720
720





















