PP-YOLOE是基于PP-YOLOv2的单阶段Anchor-free模型,含s/m/l/x系列,以CSPResNet为Backbone。CSPResNet融合CSPNet与ResNet,CSPNet通过特殊结构减少计算量并保持精度,解决传统残差网络梯度重复问题。文中还详解了CSPResNet各组成部分结构与代码,并提及BML平台使用体验。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

PP-YOLOE是基于PP-YOLOv2的卓越的单阶段Anchor-free模型,超越了多种流行的yolo模型。PP-YOLOE有一系列的模型,即s/m/l/x,可以通过width multiplier和depth multiplier配置。PP-YOLOE避免使用诸如deformable convolution或者matrix nms之类的特殊算子,以使其能轻松地部署在多种多样的硬件上。
PP-YOLOE 与其他网络比较
在coco评价上 PPYOLOE成功超越ppyolov2 甚至还压了同样采用anchor-free算法的YOLO-X一头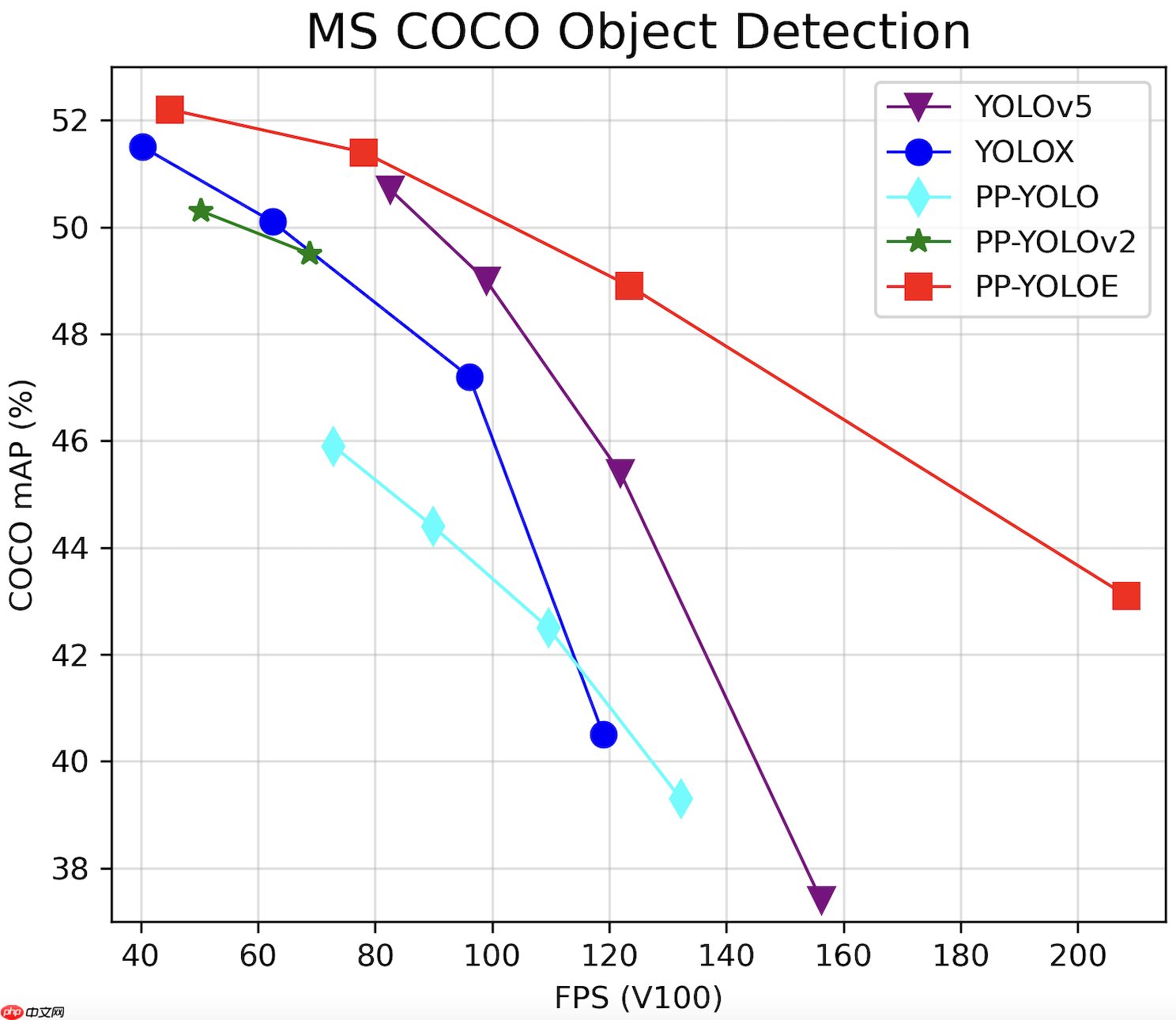
而作为提取图像特征的Backbone,PPYOLOE把将SCP结构加入到了ResNet中,形成了CSPResNEt
????什么你说你不懂什么是Backbone?没问题!!!
引用知乎大神 连诗路 Backbone 翻译为主干网络的意思,既然说是主干网络,就代表其是网络的一部分,那么是哪部分呢?翻译的很好,主干部分,哈哈哈哈,文字游戏了哈。这个主干网络大多时候指的是提取特征的网络,其作用就是提取图片中的信息,共后面的网络使用。这些网络经常使用的是resnet VGG等,而不是我们自己设计的网络,因为这些网络已经证明了在分类等问题上的特征提取能力是很强的。在用这些网络作为backbone的时候,都是直接加载官方已经训练好的模型参数,后面接着我们自己的网络。让网络的这两个部分同时进行训练,因为加载的backbone模型已经具有提取特征的能力了,在我们的训练过程中,会对他进行微调,使得其更适合于我们自己的任务。
| 作者 | 连诗路 |
|---|---|
| 链接 | 知乎 |
那么什么是Backbone介绍完了,那么我们就来正式介绍一下CSPResNet !!
CSPNet全称是Cross Stage Partial Network,主要从一个比较特殊的角度切入,能够在降低20%计算量的情况下保持甚至提高CNN的能力。
这里我们采用一问一答的形式来进行描述
Cross Stage Partial Network的设计目的?
从网络结构设计的角度来解决以往工作在推理过程中需要很大计算量的问题
为什么传统的残差网络计算量高
作者认为推理计算过高的问题是由于网络优化中的梯度信息重复导致。
如何解决这一问题
CSPNet通过将梯度的变化从头到尾地集成到特征图中,在减少了计算量的同时可以保证准确率。
效果如何
直接看图
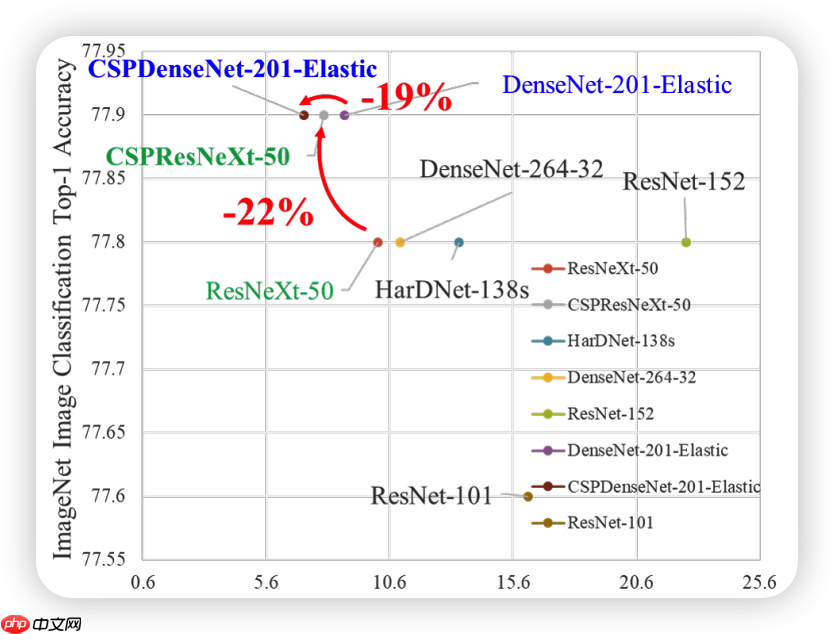
可以看到在分类任务中计算量大量下降的同时,精度能够基本保持不变或略有提升
但是在目标检测中 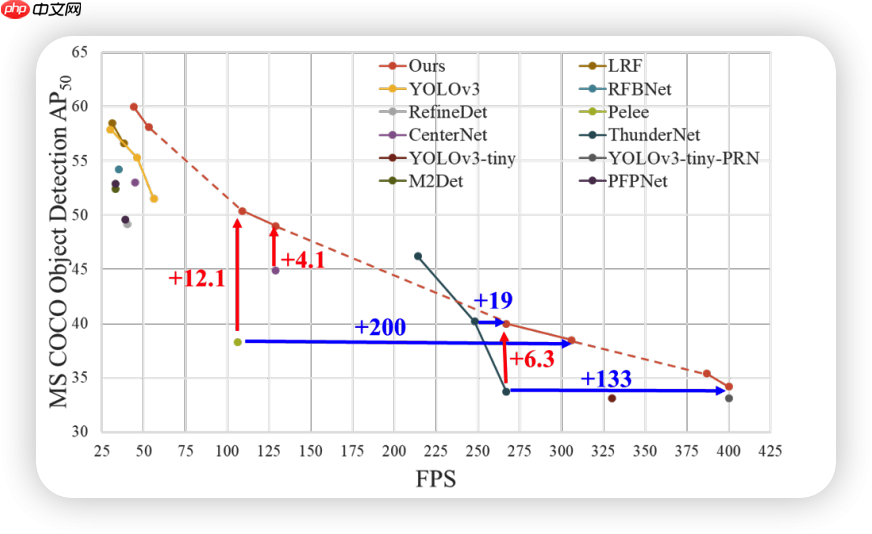
在相同FPS的情况下检测精度大幅上升,只能说,杀疯了!!!! 我们一般称这种网络为
CSP解决了什么问题呢?
怎么实现

抖猫高清去水印微信小程序,源码为短视频去水印微信小程序全套源码,包含微信小程序端源码,服务端后台源码,支持某音、某手、某书、某站短视频平台去水印,提供全套的源码,实现功能包括:1、小程序登录授权、获取微信头像、获取微信用户2、首页包括:流量主已经对接、去水印连接解析、去水印操作指导、常见问题指引3、常用工具箱:包括视频镜头分割(可自定义时长分割)、智能分割(根据镜头自动分割)、视频混剪、模糊图片高
 0
0

在论文中作者一共提出了四种结构分别是DenseNet 、CSPDenseNet 、Fusion First 、Fusion Last
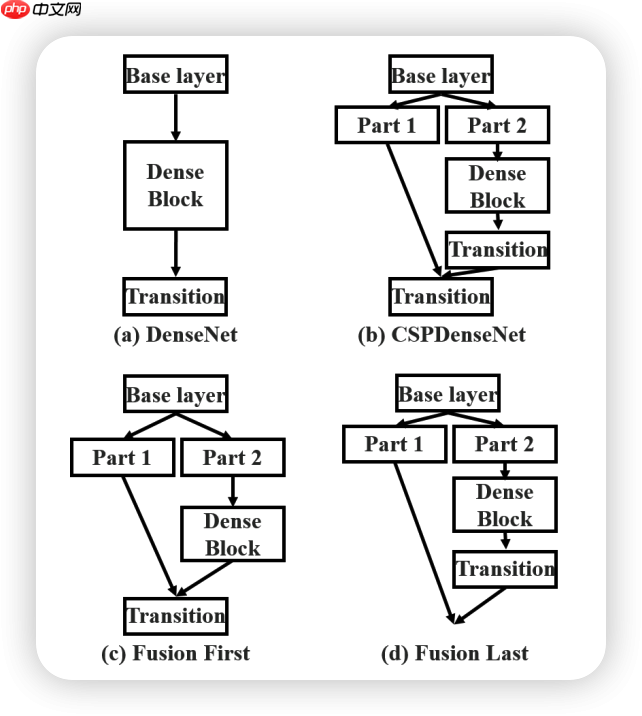
第一个就是普通的网络
Fusion First的方式是对两个分支的feature map先进行concatenation操作,这样梯度信息可以被重用。
Fusion Last的方式是对Dense Block所在分支先进性transition操作,然后再进行concatenation, 梯度信息将被截断,因此不会重复使用梯度信息 。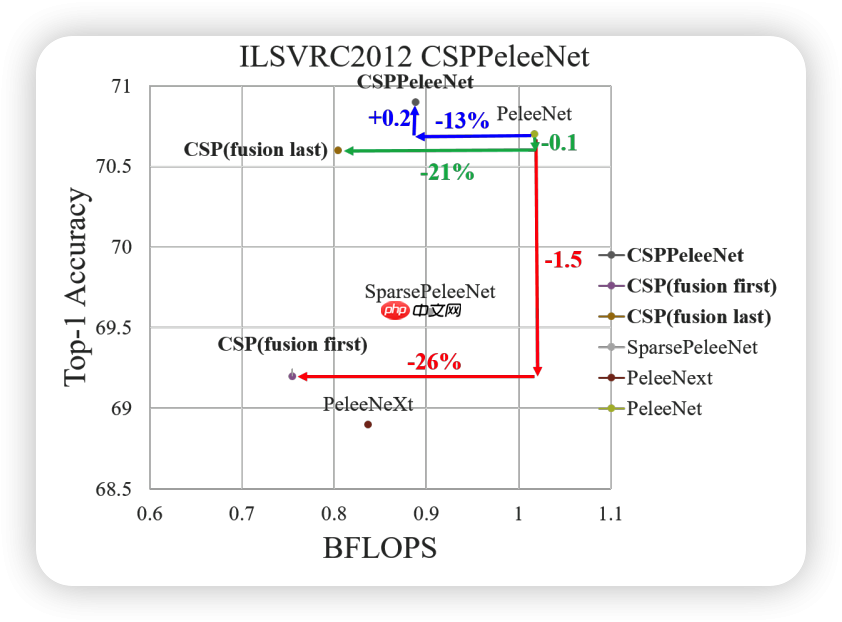
经过图像对比可知,Fusion Frist 与Fusion Last都能起到减少计算量的工作,但是对于精度的提升帮助就比较鸡肋了
但是同时使用Fusion First和Fusion Last的CSP所采用的融合方式可以在降低计算代价的同时,提升准确率。
ResNet太过经典了这里就不做过多介绍了 有兴趣可以去网上自行搜索
同时--光速吟唱 有兴趣可以看一下我写的ResNet+FPN详解
就像ResNet与DarkNet有一个最基础的部分,CSPResNet也有最基础的测部分,而这个最基础的部分就是ConvBNLayer
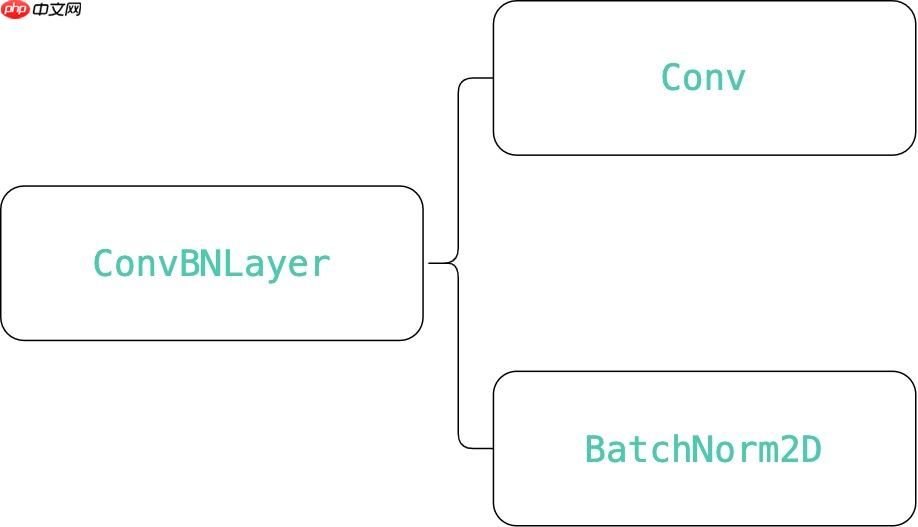
可以看到ConvBNLayer就是又一个Conv2D与一个BatchNrom2D组成,最后再加上一个激活函数
class ConvBNLayer(nn.Layer):
def __init__(self,
ch_in,
ch_out, filter_size=3, stride=1, groups=1, padding=0, act=None):
super(ConvBNLayer, self).__init__()
self.conv = nn.Conv2D( in_channels=ch_in, out_channels=ch_out, kernel_size=filter_size, stride=stride, padding=padding, groups=groups, bias_attr=False)
self.bn = nn.BatchNorm2D(
ch_out, weight_attr=ParamAttr(regularizer=L2Decay(0.0)), bias_attr=ParamAttr(regularizer=L2Decay(0.0)))
self.act = get_act_fn(act) if act is None or isinstance(act, (
str, dict)) else act
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.act(x)
return x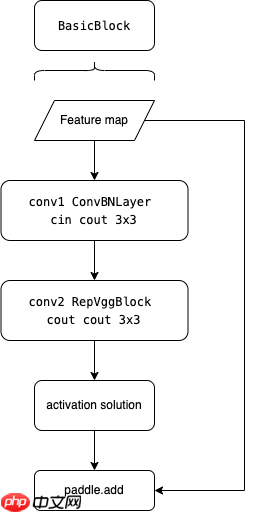
可以发现BasicBlock就是使用一个ConvNBLayer加一个RepVggBlock ,既然这里提到了REPVGGBlock那就简单提一下
RepVGG是一个简单但功能强大的卷积神经网络架构,它具有类似 VGG 的推理时间,仅由一堆 3 × 3 卷积和 ReLU 组成,而训练时间模型具有多分支拓扑。 这种训练期间和推理期间架构的解耦是通过结构重新参数化技术实现的。在 ImageNet 上,RepVGG 达到了超过 80% 的 top-1 准确率,这是plain结构模型的第一次。 在 NVIDIA 1080Ti GPU 上,RepVGG 模型的运行速度比 ResNet-50 快 83% 或比 ResNet-101 快 101%,具有更高的准确度,并且与 EfficientNet 和 RegNet 等最先进的模型相比显示出有利的准确度-速度权衡。
RepVGGBlock由Conv3x3+bn、Conv1x1+bn、identity分支构成,以上三个分支输出add-wise后(不改变通道数)再使用ReLu
而CSPResNet中的RepVGGBlock则是Conv3x3+bn、Conv1x1+bn分支构成,并将两者分支输出相加之后再经过激活函数
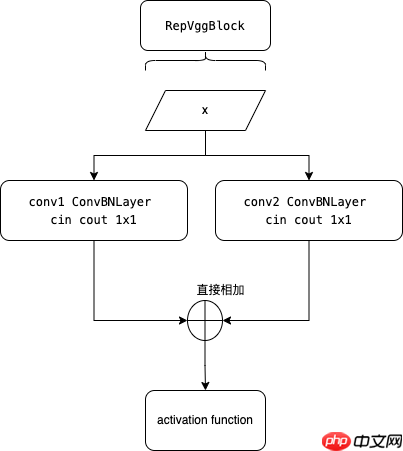
class RepVggBlock(nn.Layer):
def __init__(self, ch_in, ch_out, act='relu'):
super(RepVggBlock, self).__init__()
self.ch_in = ch_in
self.ch_out = ch_out
self.conv1 = ConvBNLayer(
ch_in, ch_out, 3, stride=1, padding=1, act=None)
self.conv2 = ConvBNLayer(
ch_in, ch_out, 1, stride=1, padding=0, act=None)
self.act = get_act_fn(act) if act is None or isinstance(act, ( str, dict)) else act def forward(self, x):
if hasattr(self, 'conv'):
y = self.conv(x) else:
y = self.conv1(x) + self.conv2(x)
y = self.act(y) return y其实CSPResNet中的RepVGGBlock并不只这些,但是由于剩下的是为了做重参数化的,只会在模型导出的时候调用,因此并不展示。
Basicblock就是一个含有残差网络的由ConvBNLayer和REPVggBlock叠加而成的网络
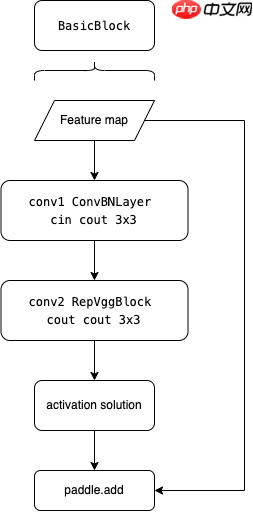
class BasicBlock(nn.Layer):
def __init__(self, ch_in, ch_out, act='relu', shortcut=True):
super(BasicBlock, self).__init__()
assert ch_in == ch_out
self.conv1 = ConvBNLayer(ch_in, ch_out, 3, stride=1, padding=1, act=act)
self.conv2 = RepVggBlock(ch_out, ch_out, act=act)
self.shortcut = shortcut
def forward(self, x):
y = self.conv1(x)
y = self.conv2(y) if self.shortcut:
return paddle.add(x, y) else:
return y终于到了正题了,CSPResStage就是将传统的可重复残差网络更改为CSP形式的网络
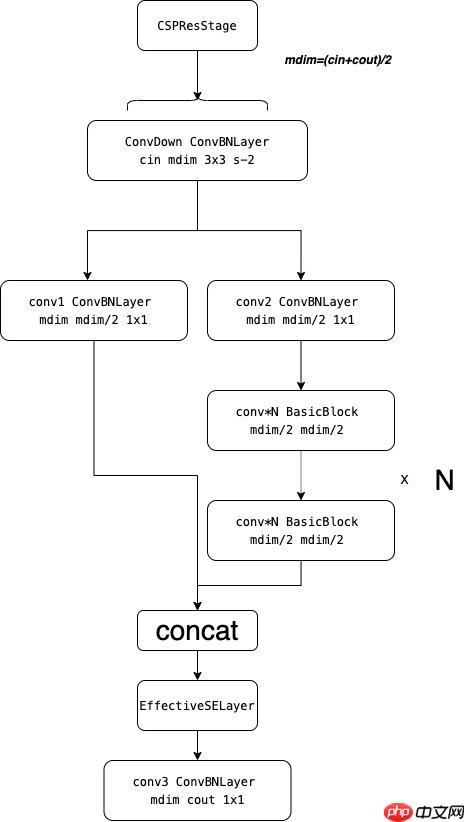
首先会先计算mdim ,mdim = (cin+cout)/2 ,如果进行了下采样那么则会使用一个ConvBNLayer将通道数从ci更改为mdim同时下采样两倍,之后分出两个分支,将通道数/2,然后其中一支就是放入到传统的可重复残差网络模块训练,然后将两个分支再深度维度进行concat操作,然后使用EffectiveSELayer模块,最后加入一个ConvBNLayer将通道数从dmin改为cout
class CSPResStage(nn.Layer):
def __init__(self,
block_fn,
ch_in,
ch_out,
n,
stride,
act='relu',
attn='eca'):
super(CSPResStage, self).__init__()
ch_mid = (ch_in + ch_out) // 2
if stride == 2:
self.conv_down = ConvBNLayer(
ch_in, ch_mid, 3, stride=2, padding=1, act=act) else:
self.conv_down = None
self.conv1 = ConvBNLayer(ch_mid, ch_mid // 2, 1, act=act)
self.conv2 = ConvBNLayer(ch_mid, ch_mid // 2, 1, act=act)
self.blocks = nn.Sequential(* [
block_fn(
ch_mid // 2, ch_mid // 2, act=act, shortcut=True) for i in range(n)
]) if attn:
self.attn = EffectiveSELayer(ch_mid, act='hardsigmoid') else:
self.attn = None
self.conv3 = ConvBNLayer(ch_mid, ch_out, 1, act=act) def forward(self, x):
if self.conv_down is not None:
x = self.conv_down(x)
y1 = self.conv1(x)
y2 = self.blocks(self.conv2(x))
y = paddle.concat([y1, y2], axis=1) if self.attn is not None:
y = self.attn(y)
y = self.conv3(y) return y# 完整代码
!git clone -b develop https://gitee.com/paddlepaddle/PaddleDetection.git
%cd PaddleDetection/ !python setup.py install !pip install -r requirements.txt
# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.## Licensed under the Apache License, Version 2.0 (the "License");# you may not use this file except in compliance with the License.# You may obtain a copy of the License at## http://www.apache.org/licenses/LICENSE-2.0## Unless required by applicable law or agreed to in writing, software# distributed under the License is distributed on an "AS IS" BASIS,# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.# See the License for the specific language governing permissions and# limitations under the License.from __future__ import absolute_importfrom __future__ import divisionfrom __future__ import print_functionimport paddleimport paddle.nn as nnimport paddle.nn.functional as Ffrom paddle import ParamAttrfrom paddle.regularizer import L2Decay# from ppdet.modeling.ops import get_act_fn# from ppdet.core.workspace import register, serializablefrom ppdet.modeling.ops import get_act_fnfrom ppdet.core.workspace import register, serializablefrom ppdet.modeling.shape_spec import ShapeSpec
__all__ = ['CSPResNet', 'BasicBlock', 'EffectiveSELayer', 'ConvBNLayer']class ConvBNLayer(nn.Layer):
def __init__(self,
ch_in,
ch_out,
filter_size=3,
stride=1,
groups=1,
padding=0,
act=None):
super(ConvBNLayer, self).__init__()
self.conv = nn.Conv2D(
in_channels=ch_in,
out_channels=ch_out,
kernel_size=filter_size,
stride=stride,
padding=padding,
groups=groups,
bias_attr=False)
self.bn = nn.BatchNorm2D(
ch_out,
weight_attr=ParamAttr(regularizer=L2Decay(0.0)),
bias_attr=ParamAttr(regularizer=L2Decay(0.0)))
self.act = get_act_fn(act) if act is None or isinstance(act, ( str, dict)) else act def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.act(x) return xclass RepVggBlock(nn.Layer):
def __init__(self, ch_in, ch_out, act='relu'):
super(RepVggBlock, self).__init__()
self.ch_in = ch_in
self.ch_out = ch_out
self.conv1 = ConvBNLayer(
ch_in, ch_out, 3, stride=1, padding=1, act=None)
self.conv2 = ConvBNLayer(
ch_in, ch_out, 1, stride=1, padding=0, act=None)
self.act = get_act_fn(act) if act is None or isinstance(act, ( str, dict)) else act def forward(self, x):
if hasattr(self, 'conv'):
y = self.conv(x) else:
y = self.conv1(x) + self.conv2(x)
y = self.act(y) return y def convert_to_deploy(self):
if not hasattr(self, 'conv'):
self.conv = nn.Conv2D(
in_channels=self.ch_in,
out_channels=self.ch_out,
kernel_size=3,
stride=1,
padding=1,
groups=1)
kernel, bias = self.get_equivalent_kernel_bias()
self.conv.weight.set_value(kernel)
self.conv.bias.set_value(bias) def get_equivalent_kernel_bias(self):
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.conv1)
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.conv2) return kernel3x3 + self._pad_1x1_to_3x3_tensor(
kernel1x1), bias3x3 + bias1x1 def _pad_1x1_to_3x3_tensor(self, kernel1x1):
if kernel1x1 is None: return 0
else: return nn.functional.pad(kernel1x1, [1, 1, 1, 1]) def _fuse_bn_tensor(self, branch):
if branch is None: return 0, 0
kernel = branch.conv.weight
running_mean = branch.bn._mean
running_var = branch.bn._variance
gamma = branch.bn.weight
beta = branch.bn.bias
eps = branch.bn._epsilon
std = (running_var + eps).sqrt()
t = (gamma / std).reshape((-1, 1, 1, 1)) return kernel * t, beta - running_mean * gamma / stdclass BasicBlock(nn.Layer):
def __init__(self, ch_in, ch_out, act='relu', shortcut=True):
super(BasicBlock, self).__init__() assert ch_in == ch_out
self.conv1 = ConvBNLayer(ch_in, ch_out, 3, stride=1, padding=1, act=act)
self.conv2 = RepVggBlock(ch_out, ch_out, act=act)
self.shortcut = shortcut def forward(self, x):
y = self.conv1(x)
y = self.conv2(y) if self.shortcut: return paddle.add(x, y) else: return yclass EffectiveSELayer(nn.Layer):
""" Effective Squeeze-Excitation
From `CenterMask : Real-Time Anchor-Free Instance Segmentation` - https://arxiv.org/abs/1911.06667
"""
def __init__(self, channels, act='hardsigmoid'):
super(EffectiveSELayer, self).__init__()
self.fc = nn.Conv2D(channels, channels, kernel_size=1, padding=0)
self.act = get_act_fn(act) if act is None or isinstance(act, ( str, dict)) else act def forward(self, x):
x_se = x.mean((2, 3), keepdim=True)
x_se = self.fc(x_se) return x * self.act(x_se)class CSPResStage(nn.Layer):
def __init__(self,
block_fn,
ch_in,
ch_out,
n,
stride,
act='relu',
attn='eca'):
super(CSPResStage, self).__init__()
ch_mid = (ch_in + ch_out) // 2
if stride == 2:
self.conv_down = ConvBNLayer(
ch_in, ch_mid, 3, stride=2, padding=1, act=act) else:
self.conv_down = None
self.conv1 = ConvBNLayer(ch_mid, ch_mid // 2, 1, act=act)
self.conv2 = ConvBNLayer(ch_mid, ch_mid // 2, 1, act=act)
self.blocks = nn.Sequential(* [
block_fn(
ch_mid // 2, ch_mid // 2, act=act, shortcut=True) for i in range(n)
]) if attn:
self.attn = EffectiveSELayer(ch_mid, act='hardsigmoid') else:
self.attn = None
self.conv3 = ConvBNLayer(ch_mid, ch_out, 1, act=act) def forward(self, x):
if self.conv_down is not None:
x = self.conv_down(x)
y1 = self.conv1(x)
y2 = self.blocks(self.conv2(x))
y = paddle.concat([y1, y2], axis=1) if self.attn is not None:
y = self.attn(y)
y = self.conv3(y) return y# @register# @serializableclass CSPResNet(nn.Layer):
__shared__ = ['width_mult', 'depth_mult', 'trt'] def __init__(self,
layers=[3, 6, 6, 3],
channels=[64, 128, 256, 512, 1024],
act='swish',
return_idx=[0, 1, 2, 3, 4],
depth_wise=False,
use_large_stem=False,
width_mult=1.0,
depth_mult=1.0,
trt=False):
super(CSPResNet, self).__init__()
channels = [max(round(c * width_mult), 1) for c in channels]
layers = [max(round(l * depth_mult), 1) for l in layers]
act = get_act_fn(
act, trt=trt) if act is None or isinstance(act,
(str, dict)) else act if use_large_stem:
self.stem = nn.Sequential(
('conv1', ConvBNLayer( 3, channels[0] // 2, 3, stride=2, padding=1, act=act)),
('conv2', ConvBNLayer(
channels[0] // 2,
channels[0] // 2, 3,
stride=1,
padding=1,
act=act)), ('conv3', ConvBNLayer(
channels[0] // 2,
channels[0], 3,
stride=1,
padding=1,
act=act))) else:
self.stem = nn.Sequential(
('conv1', ConvBNLayer( 3, channels[0] // 2, 3, stride=2, padding=1, act=act)),
('conv2', ConvBNLayer(
channels[0] // 2,
channels[0], 3,
stride=1,
padding=1,
act=act)))
n = len(channels) - 1
self.stages = nn.Sequential(* [(str(i), CSPResStage(
BasicBlock, channels[i], channels[i + 1], layers[i], 2, act=act)) for i in range(n)])
self._out_channels = channels[1:]
self._out_strides = [4, 8, 16, 32]
self.return_idx = return_idx def forward(self, inputs):
#x = inputs['image']
x = inputs
x = self.stem(x)
outs = [] for idx, stage in enumerate(self.stages):
x = stage(x) if idx in self.return_idx:
outs.append(x) return x @property
def out_shape(self):
return [
ShapeSpec(
channels=self._out_channels[i], stride=self._out_strides[i]) for i in self.return_idx
]if __name__=='__main__':
model = CSPResNet()
paddle.summary(model,(1,3,640,640))这次我不想聊别的只想说一下关于新版BML的问题,当新版BML没上线的时候,我是抱着满心期待的,尤其是当BML发布之后真的给我惊艳到了,耐看的配色,丰富的UI设计,尤其是一开始我看到那个资源监控室动态的这个真的是最惊艳到我的地方,我当时就想着能不能在本地也下一个BML,但是后来随着深入使用发现了越来越多的问题,当然新平台刚上线嘛肯定有问题慢慢解决就好了,但是现在应该快一年了吧,结果还是一堆bug,我知道维护新平台很累,bug很多,很难修,但是 一年过去了 我想问一下研发的同学有好多bug从去年就开始提为什么到了今年了还是出现,这个是不是有点太。。。如果是资金的问题,可以开放会员制,我举双手赞成,毕竟平台不是慈善家,我今天把这个事情提出来并不是要去埋怨哪个人或者什么,我只是真的想好好的说一下问题,麻烦能不能去沉下心来一段时间好好优化一下BML,BML很漂亮,但是它不是工艺品,它是需要被拿来用的。
| 姓名 | 李慧涛 |
|---|---|
| 昵称 | 老萌新 |
| 学校 | 北京石油化工学院 |
| 年级 | 大二 |
| 木有女朋友 | 是条单身狗 |
以上就是PPYOLOE解析1 Backbone的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号





 280
280























