文本情感分析旨在识别和提取文本中的倾向、立场、评价、观点等主观信息,主要包括两类任务:情感倾向分类(简称情感分类)和观点抽取;情感分析具有很高的学术价值,在消费决策、舆情分析、个性化推荐等领域均有重要应用,有很高的商业价值,情感分类是用于识别主观文本中的情感倾向的技术。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜


售后评价情感分类是一种通过分析消费者在购买产品后留下的评价文本,以识别和分类消费者情感倾向的技术,对于企业来说至关重要,因为它能从客户反馈中提取出有价值信息,通过分析消费者的产品评价文本,识别其情感倾向,帮助企业提升产品和服务质量,优化客户体验;
本项目基于PaddlePaddle 3.0实现售后评价情感分类,助力产品销售,本项目情感倾向包括积极、消极为二类,可根据实际数据,以实现任何场景的多分类模型;
PaddlePaddle 3.0具有动静统一自动并行、神经网络编译器自动优化、大模型训推一体和多硬件适配等关键特性,为本项目实现提供了强大的技术支持,使得售后评价情感分类模型的构建和训练变得更加高效和便捷;
本部分导入整个模型训练过程所需要的函数库,做好事先的导入,方便后续快速调用;
import jiebaimport jieba.posseg as pseg #去除无关词性的词import csvfrom sklearn.preprocessing import LabelEncoder #标签规格化处理import pandas as pdimport reimport stringimport paddlefrom paddle.nn import Conv2D, Linear, Embeddingfrom paddle import to_tensorimport paddle.nn.functional as Fimport os, zipfileimport io, random, jsonimport numpy as npimport matplotlib.pyplot as plt
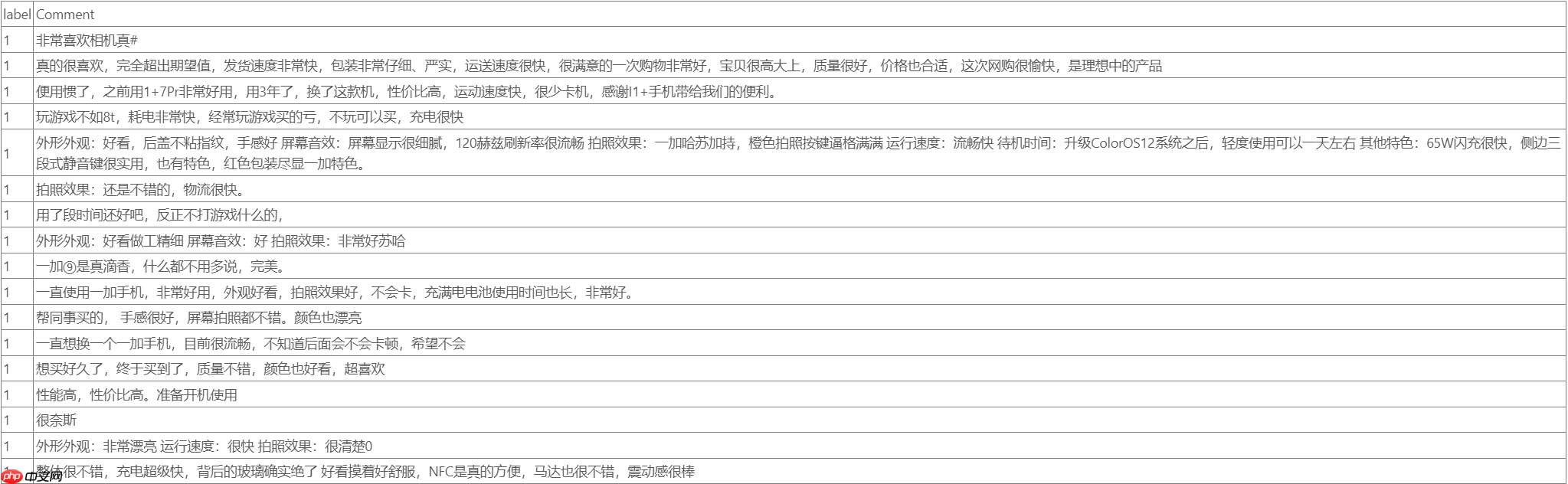
本项目所采用数据集为京东某商品评论数据集,本任务所作为情感上的二分类,要想替换为多分类,数据集仍整理成该种形式即可;
部分数据集呈现如下图所示,前面为对应的类型,后面为所对应的文字;
数据预处理流程主要包含两个关键步骤:标签编码和评论提取。
1、使用pandas库从CSV文件读取数据集,通过自定义的encodeLabel函数,利用LabelEncoder将标签列的文本标签转换为数值标签,便于模型处理;
2、定义getComment函数来收集数据集中的所有评论;
这两个函数分别通过遍历数据集中的相应列来实现目的,并最终打印出编码后的第一个标签和第一个评论。
1
非常喜欢相机真## 读入数据集# 使用pandas的read_csv函数从CSV文件中加载数据data = pd.read_csv('work/alldata.csv')# 数据的预处理# 定义一个函数,用于将数据集中的标签列进行编码def encodeLabel(data):
# 初始化一个空列表来存储标签
listLabel = [] # 遍历数据集中的每个标签
for label in data['label']: # 将标签添加到列表中
listLabel.append(label) # 创建LabelEncoder对象
le = LabelEncoder() # 使用LabelEncoder对标签进行编码转换
resultLabel = le.fit_transform(listLabel) # 返回编码后的标签
return resultLabel# 调用encodeLabel函数,对数据集中的标签进行编码Label = encodeLabel(data)# 打印编码后的第一个标签print(Label[0])# 定义一个函数,用于获取数据集中所有评论def getComment(data):
# 初始化一个空列表来存储评论
listComment = [] # 遍历数据集中的每个评论
for comment in data['Comment']: # 将评论添加到列表中
listComment.append(comment) # 返回包含所有评论的列表
return listComment# 调用getComment函数,获取数据集中的所有评论Comment = getComment(data)
# 打印第一个评论print(Comment[0])1 非常喜欢相机真#
本部分对先是对数据进行预处理,包括加载停用词、去除停用词、分词、词性标注以及将处理后的数据保存到文件中等操作;
在进行数据字典的生成,在进行花费,得到模型训练所需要的数据集的规范形式;
1、定义处理文本数据,包括加载停用词、去除停用词、分词和词性标注函数来
2、将处理后的数据与标签合并,并保存到文件中;
3、用jieba库进行中文分词,re库进行正则表达式匹配,以及string库来处理字符串;
4、将处理后的数据写入到一个文本文件中,每个样本由标签和分词结果组成,用*号隔开;
# 定义加载停用词表的函数def stopwordslist():
# 读取停用词文件,去除每行的空白字符,并返回停用词列表
stopwords = [line.strip() for line in open('work/stopwords.txt', encoding='utf-8').readlines()] return stopwords# 定义去除停用词的函数def deleteStop(sentence):
# 调用stopwordslist函数获取停用词列表
stopwords = stopwordslist() # 初始化一个空字符串用于存储处理后的文本
outstr = ""
# 遍历句子中的每个字符
for i in sentence: # 如果字符不是停用词且不是换行符,则添加到结果字符串
if i not in stopwords and i != '\n':
outstr += i # 返回去除停用词后的字符串
return outstr# 定义中文分词和词性标注的函数def wordCut(Comment):
# 初始化一个空列表用于存储每个评论的分词结果
Mat = [] # 导入正则表达式和jieba分词库
import re import jieba import jieba.posseg as pseg import string # 遍历评论列表
for rec in Comment: # 初始化一个空列表用于存储当前评论的分词结果
seten = [] # 移除评论中的标点符号
rec = re.sub('[%s]' % re.escape(string.punctuation), '', rec) # 如果处理后的评论为空,则跳过
if rec.strip() == '':
rec = ''
# 使用正则表达式只保留中文字符
rule = re.compile(u"[^\u4E00-\u9FA5]")
rec = rule.sub('', rec) # 使用jieba进行分词
phrase = jieba.lcut(rec) # 调用deleteStop函数去除分词结果中的停用词
stc = deleteStop(phrase) # 使用jieba.posseg进行词性标注
seg_list = pseg.cut(stc) # 遍历词性标注的结果,去除人名、地名等无关词
for word, flag in seg_list: if flag not in ['nr', 'ns', 'nt', 'nz', 'm', 'f', 'ul', 't', 'r', 'l']:
seten.append(word) # 将当前评论的分词结果添加到Mat列表
Mat.append(seten) # 返回包含所有评论分词结果的列表
return Mat# 调用wordCut函数并传入Comment列表,获取分词结果wordCut = wordCut(Comment)# 将标签和分词结果合并为一个列表,每个元素是一个包含标签和分词列表的元组all_data = list(zip(Label, wordCut))# 打开文件用于写入处理后的数据f = open('work/all_data.txt', 'w', encoding='utf-8')# 遍历all_data中的每个元组for i, j in all_data: # 如果分词结果不为空,则写入文件
if j != []: # 使用*号将标签和分词结果隔开,并写入一行
f.write(str(i) + '*' + ' '.join(j))
f.write('\n')# 关闭文件f.close()本部分是为生成一个数据字典,将文本数据中的每个唯一词汇映射到一个唯一的索引,主要包括下面三部分操作
# 定义创建数据字典的函数def create_dict(olist, dict_path):
# 打开指定路径的文件,准备写入数据字典
with open(dict_path, 'w') as f: # 定位到文件的开始位置并清空文件内容
f.seek(0)
f.truncate() # 初始化一个空集合,用于存储不重复的词汇
dict_set = set() # 遍历olist中的每行数据,即每个样本的分词结果
for line in olist: # 将当前行中的每个词汇添加到集合中,自动去重
for s in line:
dict_set.add(s) # 初始化一个空列表,用于存储字典项(词汇和对应的索引)
dict_list = [] # 初始化索引计数器
i = 0
# 遍历集合中的每个词汇
for s in dict_set: # 将词汇和对应的索引作为元组添加到列表中
dict_list.append([s, i]) # 递增索引计数器
i += 1
# 将列表转换成字典,一个词对应一个数字
dict_txt = dict(dict_list) # 添加未知字符的索引
end_dict = {"<unk>": i} # 更新字典,将未知字符的索引添加到字典中
dict_txt.update(end_dict) # 递增索引计数器为填充字符准备索引
i += 1
# 添加填充字符的索引
end_dict = {"<pad>": i} # 更新字典,将填充字符的索引添加到字典中
dict_txt.update(end_dict) # 将最终的字典写入到本地文件中
with open(dict_path, 'w', encoding='utf-8') as f: # 将字典转换为字符串并写入文件
f.write(str(dict_txt))
# 打印完成信息
print("数据字典生成完成!")# 定义加载字典的函数def load_vocab(file_path):
# 打开字典文件并读取内容
fr = open(file_path, 'r', encoding='utf8') # 使用eval函数将读取的字符串转换为字典
vocab = eval(fr.read()) # 关闭文件
fr.close() # 返回字典
return vocab# 定义将单词序列化为数字序列的函数def f_write_txt(words, dict_txt, label):
# 初始化标签字符串
labs = ""
# 遍历单词列表
for s in words: # 将单词转换为对应的数字索引
lab = str(dict_txt[s]) # 将数字索引添加到标签字符串
labs = labs + lab + ','
# 去掉最后一个逗号
labs = labs[:-1] # 将标签添加到标签字符串并换行
labs = labs + '\t' + label + '\n'
# 返回序列化后的标签和单词序列
return labs# 定义创建数据列表并划分训练集和测试集的函数def create_data_list(data_path, train_path, test_path, dict_path):
# 加载字典
dict_txt = load_vocab(dict_path) # 打开数据文件并读取所有行
with open(data_path, 'r', encoding='utf-8') as f_data:
lines = f_data.readlines() # 初始化最大序列长度计数器
i = 0
maxlen = 0
# 打开训练集和测试集文件准备写入
with open(test_path, 'a', encoding='utf-8') as f_test, open(train_path, 'a', encoding='utf-8') as f_train: # 遍历数据文件的每一行
for line in lines: # 分割标签和单词序列
words = line.split('*')[-1].replace(' ', '').strip() # 更新最大序列长度
maxlen = max(maxlen, len(words)) # 提取标签
label = line.split('*')[0] # 分割单词序列
wordcut = line.strip('01*\n').split(' ') # 将单词序列和标签序列化
labs = f_write_txt(wordcut, dict_txt, label) # 每10个样本抽取一个作为测试集,其余作为训练集
if i % 10 == 0:
f_test.write(labs) else:
f_train.write(labs) # 递增样本计数器
i += 1
# 打印完成信息
print("数据列表生成完成!")# 把生成的数据列表都放在自己的总类别文件夹中data_root_path = "/home/aistudio/work/" data_path = os.path.join(data_root_path, 'all_data.txt')
train_path = os.path.join(data_root_path, 'train_list.txt')
test_path = os.path.join(data_root_path, 'test_list.txt')
dict_path = os.path.join(data_root_path, "dict.txt")# 创建数据字典create_dict(wordCut, dict_path)# 创建数据列表#在生成数据之前,首先将test_list.txt和train_list.txt清空with open(test_path, 'w', encoding='utf-8') as f_test:
f_test.seek(0)
f_test.truncate()with open(train_path, 'w', encoding='utf-8') as f_train:
f_train.seek(0)
f_train.truncate()
create_data_list(data_path, train_path, test_path, dict_path)数据字典生成完成! 数据列表生成完成!
# 打印前2条训练数据vocab = load_vocab(dict_path)def ids_to_str(ids):
words = [] for k in ids:
w = list(vocab.keys())[list(vocab.values()).index(int(k))]
words.append(w if isinstance(w, str) else w.decode('ASCII')) return " ".join(words)with io.open(train_path, "r", encoding='utf8') as fin:
i = 0
for line in fin:
i += 1
cols = line.strip().split("\t") if len(cols) != 2:
sys.stderr.write("[NOTICE] Error Format Line!") continue
label = int(cols[1])
wids = cols[0].split(",") print(str(i)+":") print('sentence list id is:', wids) print('sentence list is: ', ids_to_str(wids)) print('sentence label id is:', label) print('---------------------------------')
if i == 2: break1: sentence list id is: ['1620', '8851', '5503', '20722', '16966', '20391', '2564', '5831', '3648', '20909', '20391', '11253', '4170', '11004', '3423', '18595', '571', '14560', '21914', '9106', '17779', '11112'] sentence list is: 真的 喜欢 超出 期望值 发货 速度 包装 仔细 严实 运送 速度 很快 满意 购物 高大 质量 价格 合适 网购 愉快 理想 产品 sentence label id is: 1 --------------------------------- 2: sentence list id is: ['12019', '14878', '15669', '23816', '6979', '4725', '7494', '8117', '20391', '23131', '17563', '10961', '24966', '11181'] sentence list is: 用惯 好 用 换 机 性价比 高 运动 速度 卡机 感谢 手机 带给 便利 sentence label id is: 1 ---------------------------------
本部分代码定义数据集类,从文本文件中读取数据,处理数据格式,并将处理后的数据转换为模型训练和测试所需的批量加载器;
首先初始化数据集路径,读取数据,对数据进行预处理,如分割、过滤和填充;
然后将处理后的数据封装成一个可迭代的数据加载器,用于模型的训练和测试;
class Dataset(paddle.io.Dataset):
def __init__(self, data_dir):
self.data_dir = data_dir
self.all_data = []
with io.open(self.data_dir, "r", encoding='utf8') as fin: for line in fin:
cols = line.strip().split("\t") if len(cols) != 2:
sys.stderr.write("[NOTICE] Error Format Line!") continue
label = []
label.append(int(cols[1]))
wids = cols[0].split(",") if len(wids)>=150:
wids = np.array(wids[:150]).astype('int64')
else:
wids = np.concatenate([wids, [vocab["<pad>"]]*(150-len(wids))]).astype('int64')
label = np.array(label).astype('int64')
self.all_data.append((wids, label))
def __getitem__(self, index):
data, label = self.all_data[index] return data, label def __len__(self):
return len(self.all_data)
batch_size = 32train_dataset = Dataset(train_path)
test_dataset = Dataset(test_path)
train_loader = paddle.io.DataLoader(train_dataset, places=paddle.CPUPlace(), return_list=True,
shuffle=True, batch_size=batch_size, drop_last=True)
test_loader = paddle.io.DataLoader(test_dataset, places=paddle.CPUPlace(), return_list=True,
shuffle=True, batch_size=batch_size, drop_last=True)CNN,即卷积神经网络,是一种深度学习模型,广泛应用于图像和文本数据的特征提取,通过卷积层、激活函数、池化层等结构,能够自动学习数据中的局部特征和层次表示,适用于图像识别、自然语言处理等多种任务。
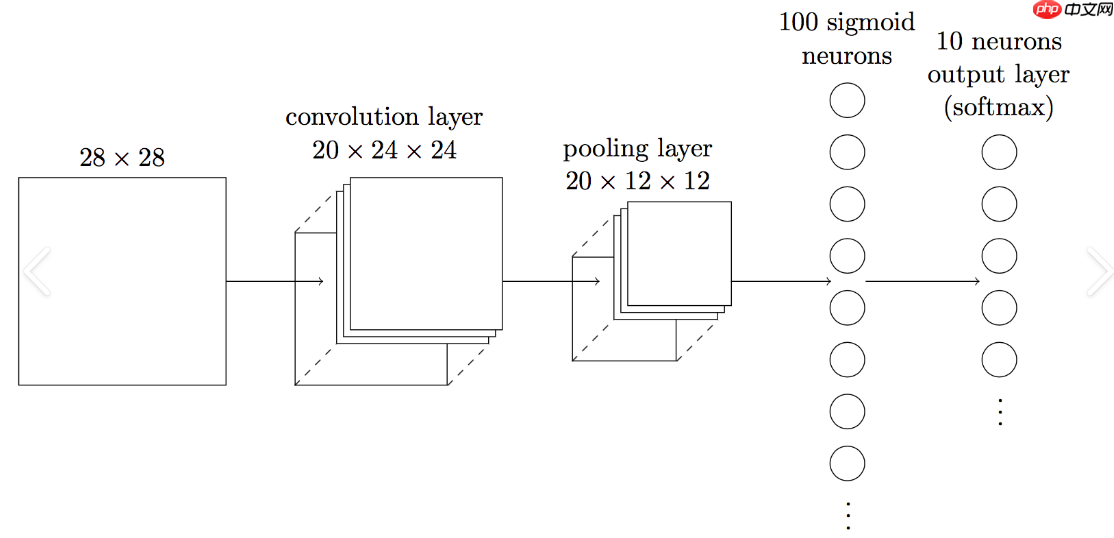
本项目所采用模型为CNN,适用于处理序列化的文本数据,通过卷积层和池化层提取文本特征,然后通过全连接层进行分类;
这种模型在自然语言处理中的文本分类任务中非常常见,能够有效地捕捉文本中的局部特征;
使用是因为它能有效提取文本的局部特征并自动学习有用的表示,同时减少参数数量并提高模型的泛化能力;
CNN的这些特性使其在处理文本数据和捕捉情感倾向方面表现出色;
#定义卷积网络class CNN(paddle.nn.Layer):
def __init__(self):
super(CNN,self).__init__()
self.dict_dim = vocab["<pad>"]
self.emb_dim = 128
self.hid_dim = 128
self.fc_hid_dim = 96
self.class_dim = 2
self.channels = 1
self.win_size = [3, self.hid_dim]
self.batch_size = 32
self.seq_len = 150
self.embedding = Embedding(self.dict_dim + 1, self.emb_dim, sparse=False)
self.hidden1 = paddle.nn.Conv2D(in_channels=1, #通道数
out_channels=self.hid_dim, #卷积核个数
kernel_size=self.win_size, #卷积核大小
padding=[1, 1]
)
self.relu1 = paddle.nn.ReLU()
self.hidden3 = paddle.nn.MaxPool2D(kernel_size=2, #池化核大小
stride=2) #池化步长2
self.hidden4 = paddle.nn.Linear(128*75, 2) #网络的前向计算过程
def forward(self,input):
#print('输入维度:', input.shape)
x = self.embedding(input)
x = paddle.reshape(x, [32, 1, 150, 128])
x = self.hidden1(x)
x = self.relu1(x) #print('第一层卷积输出维度:', x.shape)
x = self.hidden3(x) #print('池化后输出维度:', x.shape)
#在输入全连接层时,需将特征图拉平会自动将数据拉平.
x = paddle.reshape(x, shape=[self.batch_size, -1])
out = self.hidden4(x) return out本部分通过自定义的train函数来执行模型的训练,包括前向传播、损失计算、反向传播和参数更新;
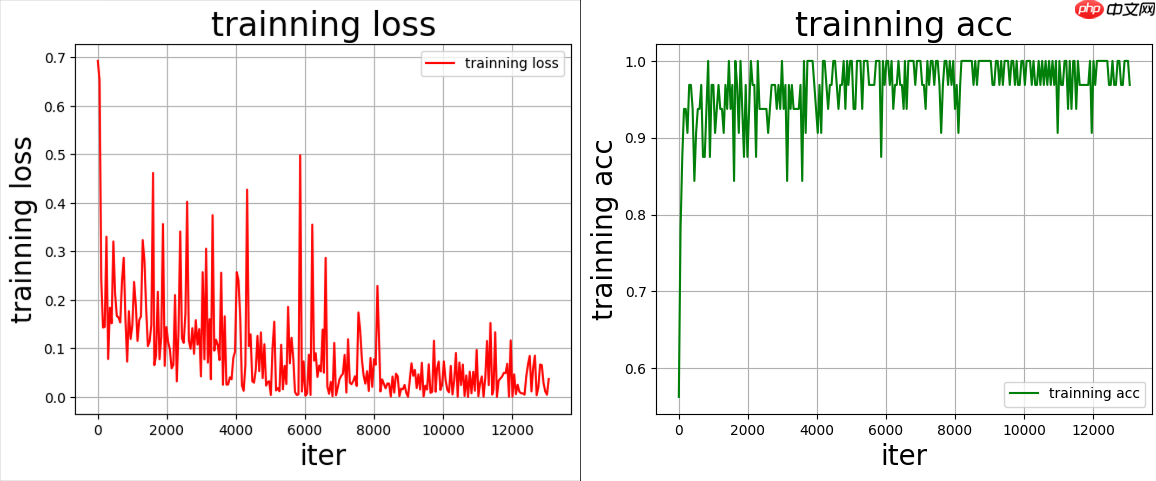
在训练过程中,每隔50个批次会记录损失和准确率,用于后续的可视化,每个epoch结束后,模型在测试集上进行评估,以监控泛化性能。
训练完成后,模型参数被保存,并且使用draw_process函数绘制训练和验证过程中的损失及准确率变化曲线;
训练七轮,最终为验证集准确度为91.5%,可根据实际需求,进行不断优化;
epoch: 7, batch_id: 1350, loss is: 0.0669107735157013 epoch: 7, batch_id: 1400, loss is: 0.06557288765907288 epoch: 7, batch_id: 1450, loss is: 0.028300032019615173 epoch: 7, batch_id: 1500, loss is: 0.011290575377643108 epoch: 7, batch_id: 1550, loss is: 0.004456622991710901 epoch: 7, batch_id: 1600, loss is: 0.037060000002384186 [validation] accuracy: 0.9157458543777466, loss: 0.6306926012039185
训练过程Loss下降和准确度变化如下图所示
# 定义绘制训练过程的函数def draw_process(title, color, iters, data, label):
plt.title(title, fontsize=24) # 设置图表标题和字体大小
plt.xlabel("iter", fontsize=20) # 设置x轴标签和字体大小
plt.ylabel(label, fontsize=20) # 设置y轴标签和字体大小
plt.plot(iters, data, color=color, label=label) # 绘制数据曲线
plt.legend() # 显示图例
plt.grid() # 显示网格
plt.show() # 显示图表# 定义训练模型的函数def train(model):
model.train() # 设置模型为训练模式
opt = paddle.optimizer.Adam(learning_rate=0.002, parameters=model.parameters()) # 定义优化器
steps = 0 # 初始化步骤计数器
Iters, total_loss, total_acc = [], [], [] # 初始化迭代次数、损失和准确率的列表
# 进行多个epoch的训练
for epoch in range(8): # 遍历训练数据集
for batch_id, data in enumerate(train_loader):
steps += 1 # 更新步骤计数器
sent = data[0] # 获取输入数据
label = data[1] # 获取标签
logits = model(sent) # 模型前向计算
loss = paddle.nn.functional.cross_entropy(logits, label) # 计算损失
acc = paddle.metric.accuracy(logits, label) # 计算准确率
if batch_id % 50 == 0: # 每50个batch记录一次
Iters.append(steps)
total_loss.append(loss.item()) # 记录损失
total_acc.append(acc.item()) # 记录准确率
print("epoch: {}, batch_id: {}, loss is: {}".format(epoch, batch_id, loss.numpy())) # 打印损失信息
loss.backward() # 反向传播
opt.step() # 更新模型参数
opt.clear_grad() # 清除梯度
# 每个epoch结束后评估模型
model.eval() # 设置模型为评估模式
accuracies = []
losses = [] for batch_id, data in enumerate(test_loader):
sent = data[0]
label = data[1]
logits = model(sent)
loss = paddle.nn.functional.cross_entropy(logits, label)
acc = paddle.metric.accuracy(logits, label)
accuracies.append(acc.numpy())
losses.append(loss.numpy())
avg_acc, avg_loss = np.mean(accuracies), np.mean(losses) # 计算平均准确率和损失
print("[validation] accuracy: {}, loss: {}".format(avg_acc, avg_loss)) # 打印评估信息
model.train() # 切换回训练模式
# 保存模型参数
paddle.save(model.state_dict(), "model_final.pdparams") # 绘制训练过程中的损失和准确率
draw_process("trainning loss", "red", Iters, total_loss, "trainning loss")
draw_process("trainning acc", "green", Iters, total_acc, "trainning acc")
# 创建CNN模型实例model = CNN()# 调用训练函数开始训练train(model)最终评估准确度为:[validation] accuracy: 0.9159185290336609, loss: 0.6325207352638245
显然数字是可以提高的,可以尝试增大Epoch进行更多轮的训练,去调优本模型识别效果;
'''
模型评估
'''model_state_dict = paddle.load('model_final.pdparams')
model = CNN()
model.set_state_dict(model_state_dict)
model.eval()
accuracies = []
losses = []for batch_id, data in enumerate(test_loader):
sent = data[0]
label = data[1]
logits = model(sent)
loss = paddle.nn.functional.cross_entropy(logits, label)
acc = paddle.metric.accuracy(logits, label)
accuracies.append(acc.numpy())
losses.append(loss.numpy())
avg_acc, avg_loss = np.mean(accuracies), np.mean(losses)print("[validation] accuracy: {}, loss: {}".format(avg_acc, avg_loss))[validation] accuracy: 0.9174723625183105, loss: 0.7229368090629578
本部分加载了一个预训练的CNN模型,并在测试数据上进行预测,将预测结果与实际标签进行对比,以评估模型的情感分类性能;
通过映射预测概率最高的索引到预定义的标签,然后打印出预测标签和实际标签,以及处理后的输入文本,查看推理效果
label_map = {0:"negative", 1:"positive"}
model_state_dict = paddle.load('model_final.pdparams')
model = CNN()
model.set_state_dict(model_state_dict)
model.eval()for batch_id, data in enumerate(test_loader):
sent = data[0]
gt_labels = data[1].numpy()
results = model(sent)
predictions = [] for probs in results: # 映射分类label
idx = np.argmax(probs)
labels = label_map[idx]
predictions.append(labels) print()
for i,pre in enumerate(predictions): print('数据: {} \n\n预测: {} \n原始标签:{}'.format(ids_to_str(sent[0]).replace(" ", "").replace("<pad>",""), pre, label_map[gt_labels[0][0]])) break
break数据: 收到质量不错挺手机挺漂亮动画挺大屏值得信赖声音挺大外观挺好看感谢商家感谢快递支持感谢商家感谢 预测: positive 原始标签:positive
以上就是【智情洞察】PaddlePaddle 3.0驱动的售后评价分析与优化系统的详细内容,更多请关注php中文网其它相关文章!

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号









 140
140
























