本文介绍了文本的向量表示,包括词向量的概念、将单词转化为向量的方式及词向量具备语义信息的特点。还讲解了独热编码、词袋模型、TF-IDF、N-gram模型等离散表示方法,并指出离散表示存在无法衡量词间关系、数据稀疏、计算复杂等缺点。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜


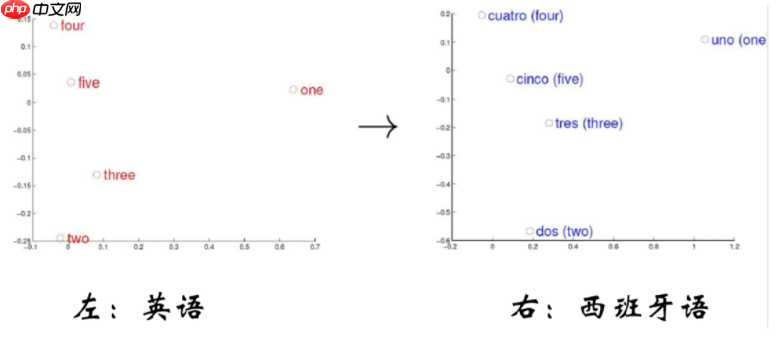
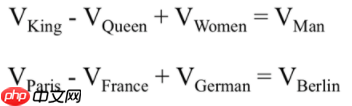
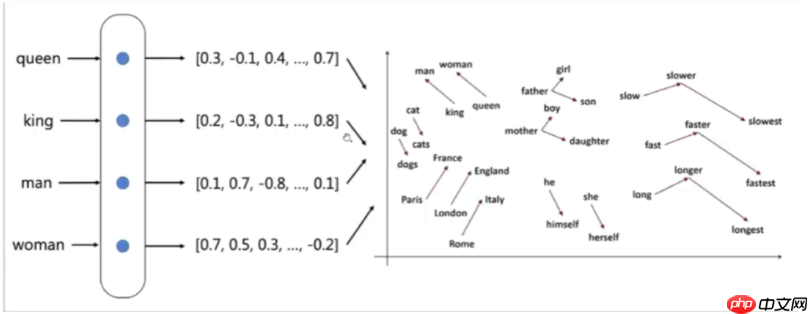
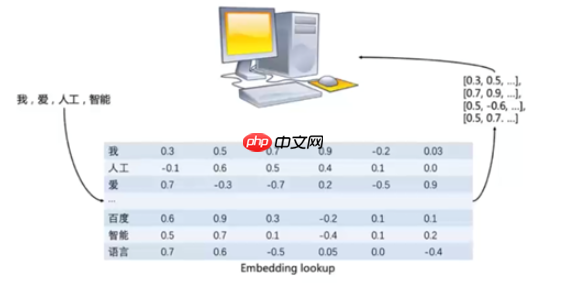
最终目标:单词的向量表示作为机器学习,特别是深度学习的输入和表示空间



采用 php+mysql 数据库方式运行的强大网上商店系统,执行效率高速度快,支持多语言,模板和代码分离,轻松创建属于自己的个性化用户界面 v3.5更新: 1).进一步静态化了活动商品. 2).提供了一些重要UFT-8转换文件 3).修复了除了网银在线支付其它支付显示错误的问题. 4).修改了LOGO广告管理,增加LOGO链接后主页LOGO路径错误的问题 5).修改了公告无法发布的问题,可能是打压
 0
0

深 1 0 0 0 度 0 1 0 0 学 0 0 1 0 习 0 0 0 1
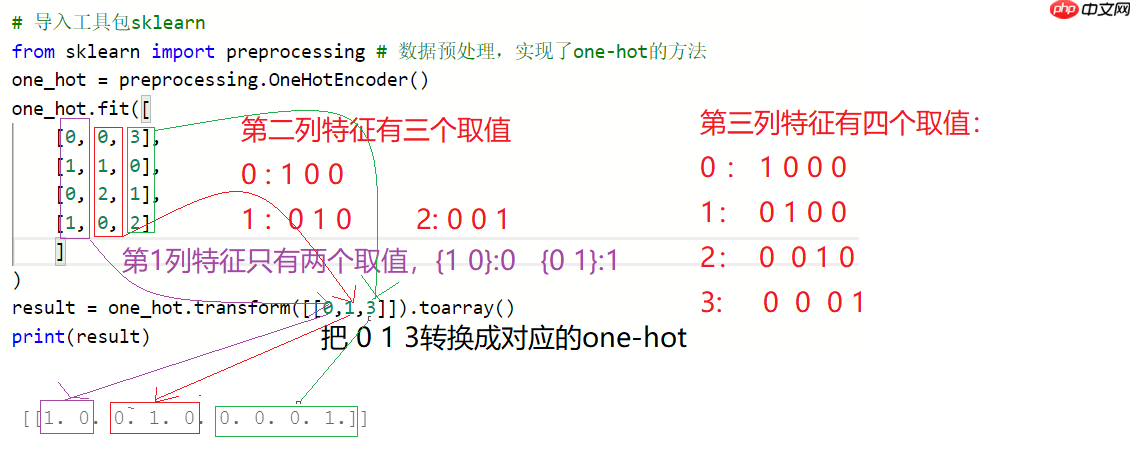
# 实现one-hot encoder编码表示"""
性别 区域 成绩
0 0 3
1 1 0
0 2 1
1 0 2
需求:请输出[0, 1, 3]每个数字的one-hot编码表示
"""# 导入工具包sklearnfrom sklearn import preprocessing # 数据预处理,实现了one-hot的方法one_hot = preprocessing.OneHotEncoder()
one_hot.fit([
[0, 0, 3],
[1, 1, 0],
[0, 2, 1],
[1, 0, 2]
]
)
result = one_hot.transform([[0,2,2]]).toarray()print(result)[[1. 0. 0. 0. 1. 0. 0. 1. 0.]]
orange banana apple grape banana apple apple grapeorange apple
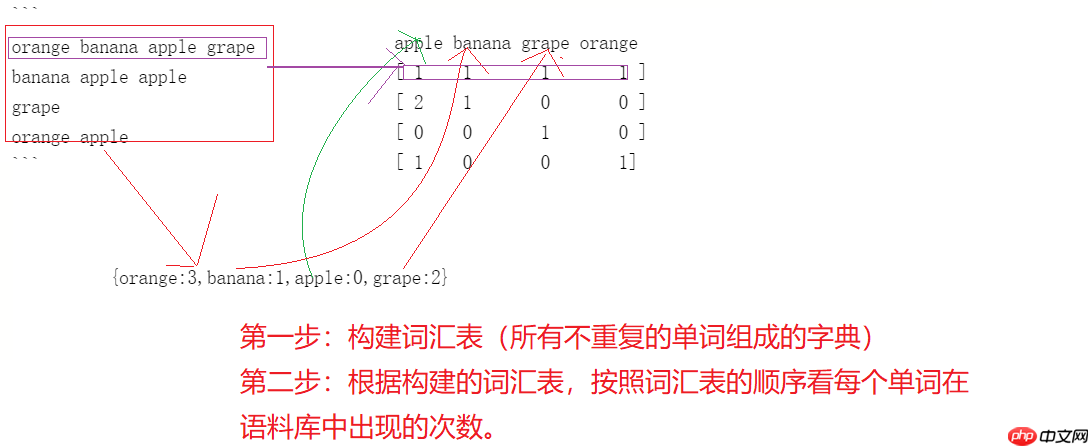
# 1. 导入工具库from sklearn.feature_extraction.text import CountVectorizer # 计数texts = [ "orange banana apple grape", "banana apple apple apple", "grape", "orange apple", ] count_vec = CountVectorizer() # 创建词袋模型的对象count_vec_fit = count_vec.fit_transform(texts) # 训练语料库print(count_vec.vocabulary_) # 输出根据语料库构建的词汇表print(count_vec_fit.toarray()) # 把文本转换成对应的向量表示
{'orange': 3, 'banana': 1, 'apple': 0, 'grape': 2}
[[1 1 1 1]
[3 1 0 0]
[0 0 1 0]
[1 0 0 1]]注意事项:如果一个单词在句子中出现的频率非常的高,说明该单词具有一定的重要性,但如果一个词语在整篇语料库中出现的频率都很高,就说明这个单词很普遍(常见)。
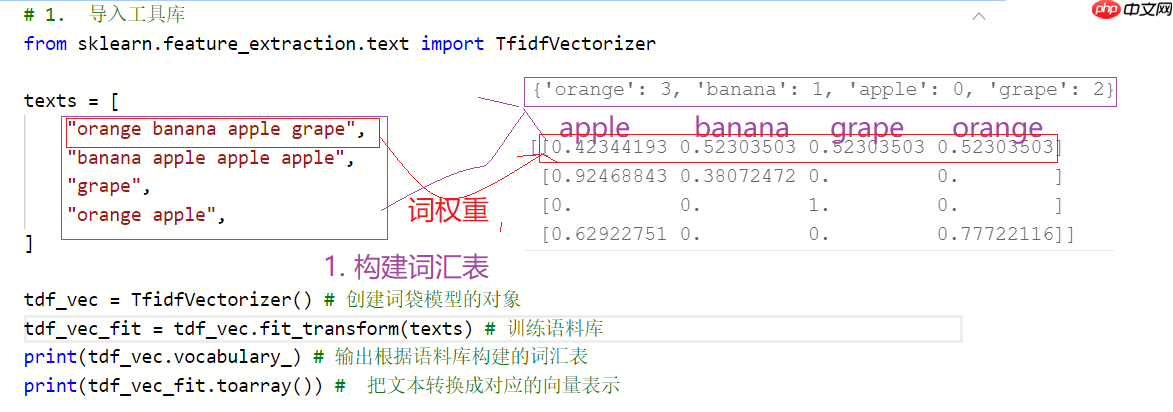
# 1. 导入工具库from sklearn.feature_extraction.text import TfidfVectorizer texts = [ "orange banana apple grape", "banana apple apple apple", "grape", "orange apple", ] tdf_vec = TfidfVectorizer() # 创建词袋模型的对象tdf_vec_fit = tdf_vec.fit_transform(texts) # 训练语料库print(tdf_vec.vocabulary_) # 输出根据语料库构建的词汇表print(tdf_vec_fit.toarray()) # 把文本转换成对应的向量表示
{'orange': 3, 'banana': 1, 'apple': 0, 'grape': 2}
[[0.42344193 0.52303503 0.52303503 0.52303503]
[0.92468843 0.38072472 0. 0. ]
[0. 0. 1. 0. ]
[0.62922751 0. 0. 0.77722116]]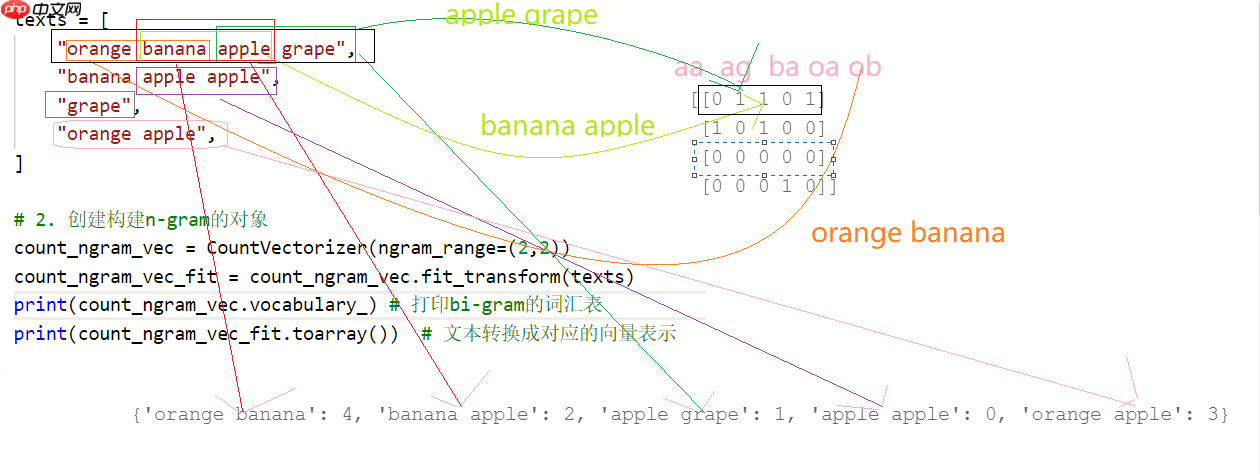
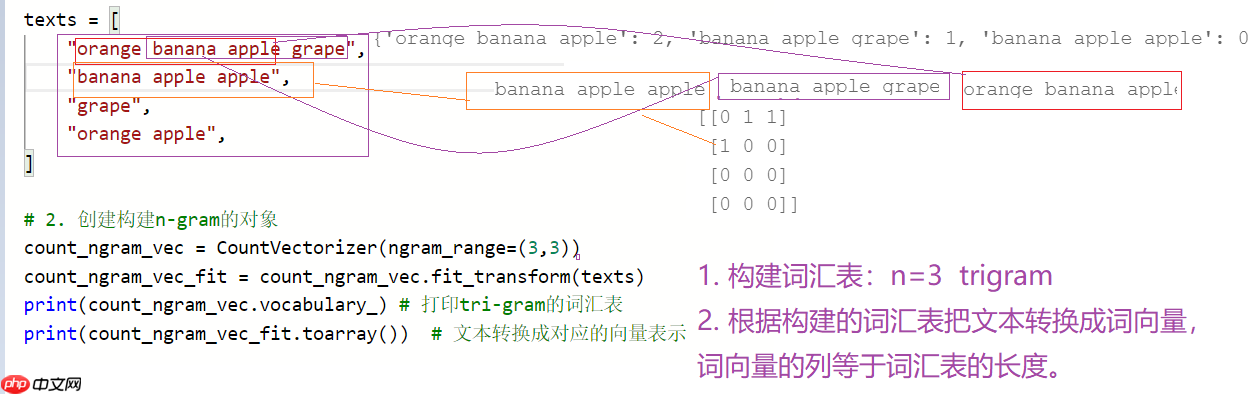
from sklearn.feature_extraction.text import CountVectorizer # 词频的统计可以实现n-gram# 1. 构建语料库texts = [ "orange banana apple grape", "banana apple apple", "grape", "orange apple", ]# 2. 创建构建n-gram的对象count_ngram_vec = CountVectorizer(ngram_range=(2,3)) count_ngram_vec_fit = count_ngram_vec.fit_transform(texts)print(count_ngram_vec.vocabulary_) # 打印bi-gram的词汇表print(count_ngram_vec_fit.toarray()) # 文本转换成对应的向量表示
{'orange banana': 6, 'banana apple': 2, 'apple grape': 1, 'orange banana apple': 7, 'banana apple grape': 4, 'apple apple': 0, 'banana apple apple': 3, 'orange apple': 5}
[[0 1 1 0 1 0 1 1]
[1 0 1 1 0 0 0 0]
[0 0 0 0 0 0 0 0]
[0 0 0 0 0 1 0 0]]酒店 1 0 0 宾馆 0 1 0 旅社 0 0 1
以上就是文本离散表示方法的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号





 700
700

























