本文围绕算子与机器学习展开,先介绍算子定义、与张量关系、常见类型及作用。接着讲解自动微积分,包括微积分基础、自动微分原理及PaddlePaddle中的实现。还阐述机器学习核心概念、工作流程,并以PaddlePaddle实现线性和多项式回归模型,展示其应用。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

在第一篇教材中,我们深入探讨了深度学习的数学基础,特别是张量及其计算的核心概念。张量作为深度学习中的基本数据结构,它不仅是数学模型的载体,更是训练与推理过程中信息流动的核心。从张量的定义到张量间的运算,理解这些基础将为我们构建更复杂的模型提供坚实的支撑。
今天,我们将进一步拓展这一基础,深入探讨 自动微积分 机制及其在模型训练中的重要性。随着深度学习模型日益复杂,如何高效地计算梯度、优化模型参数,已成为研究与应用中的关键挑战。通过自动微分,我们能够自动化地进行梯度计算,大大简化了神经网络的训练过程,并加速了优化器的设计与实现。
与此同时,我们将引入 机器学习的核心要素,以及回归模型的构建与优化,特别是 线性回归 和 多项式回归 的实践应用。这些概念不仅帮助我们理解机器学习的基本框架,还为后续的深度学习模型奠定了重要的理论与实操基础。随着对这些基础工具和方法的掌握,我们将进入更加复杂的模型设计与优化阶段,逐步揭示深度学习的强大潜力。
对于基础理论不太熟悉的同学可以查看项目,回顾知识点:
【PaddlePaddle】基础理论教程 - 深度学习中的数学基础:
https://aistudio.baidu.com/projectdetail/8742265?sUid=710848&shared=1&ts=1736152667326
在深度学习中,我们不断使用各种“算子”来进行计算。无论是在数据预处理、神经网络训练,还是在模型优化过程中,算子都扮演着至关重要的角色。
那么,什么是算子呢?我们将在这一小节中逐步揭开算子的面纱。
算子(Operator) 是对张量进行操作的基本单位。你可以把算子看作是一个“黑盒”,它接收一些输入(张量),然后对这些输入进行某种数学运算,最终返回一个新的输出张量。
算子的作用可以类比为一个数学函数,输入一定的数据,函数会返回对应的结果。比如加法、减法、乘法、卷积等,都可以看作是某种算子。
假设你有两个数字 2 和 3,如果你将它们相加,得到的结果就是 5。这里的“加法”就是一个算子,它接收 2 和 3 两个输入,返回 5 作为输出。
在深度学习中,算子不仅限于简单的数学运算,它们通常是对张量进行操作的函数。张量是深度学习中的数据表示方式,我们将在后续章节中详细介绍。
为了更好地理解算子,我们需要先理解张量。张量是多维数据的通用表示,它可以是一个标量(0维),也可以是向量(1维)、矩阵(2维),甚至更高维的数据。在深度学习中,所有的输入、权重、输出、梯度等都可以表示为张量。
算子与张量的关系非常密切。算子通过对张量进行操作来计算数据,比如矩阵乘法、卷积等常见操作都可以看作是算子对张量的处理。比如,在神经网络的训练过程中,我们会频繁使用加法算子、乘法算子、卷积算子等。
算子的种类繁多,以下是一些常见的算子类型:
算术算子:用于基本的数学计算。
矩阵运算算子:用于进行矩阵相关的操作。
激活函数算子:常用于神经网络的激活函数,帮助网络引入非线性。
卷积算子:在处理图像数据时广泛使用。
每个算子执行的操作可以从数学层面理解为“对数据进行转换”。这些转换能够使模型在训练过程中逐渐学习到数据中的规律,并最终进行有效的预测。
例如,卷积算子通常用于图像处理,它能提取出图像中的特征,而加法算子可以帮助我们合并不同层的数据,得到更为准确的模型输出。
通过将这些算子组合在一起,我们就能构建一个深度神经网络。
在深度学习中,模型训练的核心任务之一就是根据损失函数(Loss Function)对模型的参数进行优化。而计算损失函数对模型参数的导数(梯度)是优化过程的关键步骤。如何高效地计算这些梯度呢?这就是**自动微分(Automatic Differentiation,简称AutoDiff)**机制的作用所在。
自动微分不仅可以自动计算复杂函数的导数,还能极大地简化深度学习的训练过程。本节我们将从基础概念入手,了解自动微分的工作原理、应用以及如何在PaddlePaddle中实现。
在进入自动微分之前,首先需要了解一些微积分的基础知识,特别是导数和积分。
导数是描述函数变化率的工具。假设我们有一个函数 ( f(x) ),它表示某个变量 ( x ) 对应的输出。导数 ( f'(x) ) 就是描述这个函数在某一点上变化的快慢程度。
简单来说,导数表示的是函数的斜率,即在某一点上,函数值相对于自变量变化的比率。公式可以表示为:
f′(x)=Δx→0limΔxf(x+Δx)−f(x)
这个公式的含义是,导数就是函数在某个点的瞬时变化率。
例如,对于一个简单的函数 ( f(x) = x^2 ),它的导数 ( f'(x) ) 是 ( 2x ),这表示在任意点 ( x ) 上,函数 ( x^2 ) 的变化率是 ( 2x )。
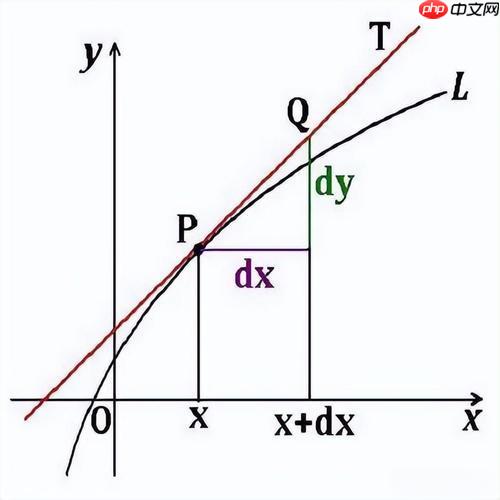
积分是微积分的另一个重要概念,它可以理解为面积的求解。假设我们有一个函数 ( f(x) ),它描述了某个量随时间变化的情况。通过对这个函数进行积分,我们可以得到函数图像下方的面积,进而得到某一段时间内的累计变化量。
积分的表示式如下:
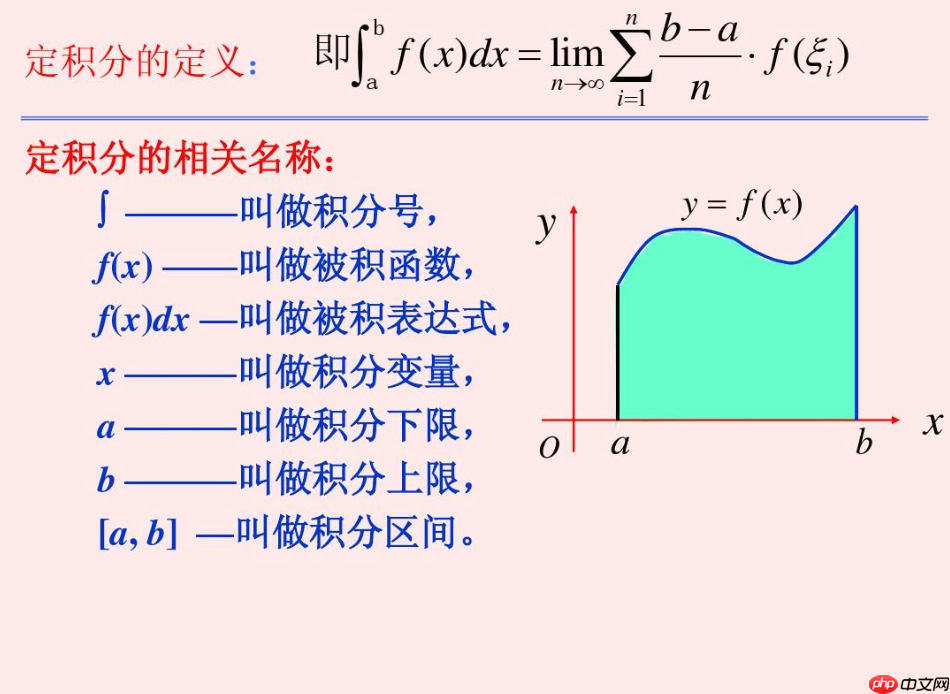
∫abf(x)dx
这表示对函数 ( f(x) ) 在区间 ([a, b]) 上进行积分,结果就是函数图像与 ( x )-轴之间的面积。
与导数不同,积分可以看作是求解某个区间的总变化量。
导数和积分是微积分中两大基本操作,它们之间有着密切的联系。根据基本微积分定理,积分和导数是互逆的。简单来说,导数是“求变化率”,而积分是“求总变化量”。
自动微分通过构建计算图,自动化地计算复杂函数的导数。我们来看一下自动微分如何通过链式法则(Chain Rule)来计算多重函数的导数。
计算图是一种图形化的表示方法,用于表示函数的计算过程。在计算图中,节点代表变量或操作(如加法、乘法等),边则表示数据流。通过这种方式,复杂的计算过程可以被分解为一系列简单的操作。
例如,考虑以下函数:
y=(x+2)(x+3)
对应计算图如下:
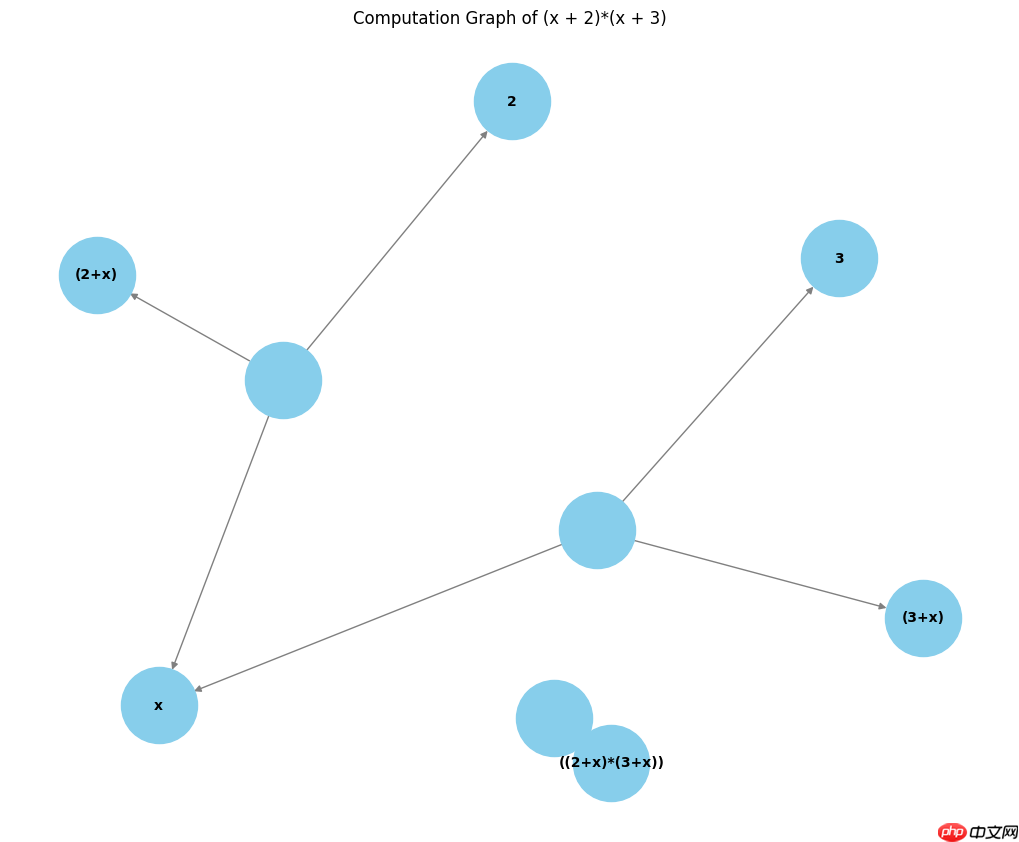
计算步骤:
1. 从输入 x 开始。 2. 将 x 加上常数 2,得到 x + 2 。 3. 将 x 加上常数 3,得到 x + 3 。 4. 将两个结果 (x + 2) 和 (x + 3) 相乘,得到最终的输出 y 。
在计算图中,我们将每个计算步骤表示为一个节点,而每个节点之间的依赖关系则通过边来连接。
链式法则是计算复合函数导数的基本工具。假设我们有一个复合函数 ( y = f(g(x)) ),那么它的导数就是:
dxdy=dgdy⋅dxdg
这个法则表明,复合函数的导数可以通过分别计算外函数和内函数的导数,然后将它们相乘来得到。
自动微分会自动构建计算图并依次计算各个节点的导数。具体来说,自动微分在前向传播时执行计算图中的所有操作,并在反向传播时计算每个节点的梯度。
我们可以使用自动微分来计算上述函数 ( y = (x + 2)(x + 3) ) 的导数。通过反向传播,我们可以轻松地计算出该函数在某一点的导数。
PaddlePaddle通过其自动微分机制,能够帮助我们高效地计算梯度。我们不需要手动计算每个参数的导数,PaddlePaddle会根据计算图自动推导并计算出所有的梯度。
我们通过PaddlePaddle来计算函数 ( f(x) = (x + 2)(x + 3) ) 在 ( x = 3 ) 时的导数。首先,我们需要定义一个张量并设置 stop_gradient=False,使得该张量参与自动微分的计算。
import paddle# 创建张量并启用梯度计算x = paddle.to_tensor([3.0], stop_gradient=False)# 定义函数 f(x) = (x + 2) * (x + 3)y = (x + 2) * (x + 3)# 计算反向传播y.backward()# 输出梯度print(f"f(x) = (x + 2) * (x + 3) 在 x = 3 时的导数为:{x.grad.numpy()}")f(x) = (x + 2) * (x + 3) 在 x = 3 时的导数为:[11.]
通过自动微分,PaddlePaddle能够生成一个计算图并自动进行反向传播计算梯度。你可以将计算图想象成一个有向图,图中的每个节点代表一个操作,边代表数据流动的过程。
x ──> (x + 2) ──> (x + 3) ──> (x + 2) * (x + 3) ──> y
反向传播过程会从 y 节点开始,依次计算每个节点的梯度,直到到达输入 x,最终得出梯度。
在神经网络中,自动微分的应用至关重要。神经网络的训练过程就是一个反向传播的过程,自动微分机制会帮助我们计算损失函数关于每个网络参数的梯度。
通过这种机制,深度学习框架能够快速地计算梯度并更新网络参数,使得模型的训练过程变得高效且自动化。
PaddlePaddle 的自动微分机制通过 backward() 方法和 paddle.grad 使得计算梯度变得非常简单。你可以通过定义损失函数,并调用 backward() 来计算梯度,从而进行模型的优化和训练。
在人工智能(AI)领域中,机器学习(Machine Learning, ML)是一个非常重要的分支。它的核心目标是使计算机系统能够自动从数据中学习并进行预测、分类或决策,而无需通过明确的编程来定义所有规则。简而言之,机器学习是通过数据让机器“自己学习”并改进其性能的一种技术。
机器学习是一种让计算机通过数据自我改进的技术。在传统的编程中,程序员需要编写详细的规则和指令来告诉计算机如何执行任务。而在机器学习中,程序员只需要提供数据和一些初步的指引,机器则会通过分析数据自动识别规律、做出预测,并不断改进其模型。
例如,在一个垃圾邮件分类的任务中,我们并不会给出“这封邮件是垃圾邮件的标准定义”。而是通过提供大量的已标记垃圾邮件和正常邮件样本,训练模型从中学习如何区分垃圾邮件和正常邮件。
机器学习的本质是基于数据来发现规律并做出预测。通过使用数学模型,机器可以从大量的数据中提取有价值的信息,从而帮助我们做出更为精准的决策。这些模型可以随着数据量的增加而不断改进,因此机器学习具有自我优化的能力。
举个例子,假设我们有一组历史销售数据,包含日期、销售额、天气等信息。我们可以训练一个机器学习模型,让它从这些数据中学习,并预测未来某天的销售额。随着时间的推移,当我们获得更多的销售数据时,模型会自动调整自己,以便给出更准确的预测结果。
传统编程:在传统的编程模式中,程序员编写明确的规则或算法,计算机根据这些规则执行任务。例如,判断一个数是否为正数,程序员可以编写简单的“if”语句进行判断。每个步骤都是人为定义的,计算机只会执行这些指令。
机器学习:机器学习不依赖显式的编程规则,而是通过数据自动学习规律。计算机系统通过对大量数据的分析来寻找隐藏的模式,并根据这些模式做出预测或决策。程序员只需要提供数据,算法会根据数据自动调整,最终得到模型。
机器学习的目标是让计算机能够在没有明确指令的情况下完成任务,并通过数据不断优化其表现。可以分为以下几个方面:
机器学习的核心要素可以概括为以下几个方面:
数据:机器学习的基础是数据,只有通过数据才能让模型进行学习和改进。数据可以是各种形式,如图片、文本、音频等。
算法:算法是机器学习的核心,它决定了如何处理数据以及如何从数据中提取有用的信息。常见的机器学习算法有线性回归、决策树、支持向量机(SVM)、神经网络等。
模型:机器学习模型是通过算法在数据上进行训练得到的结果。模型用于根据输入数据做出预测或分类。
损失函数:损失函数衡量了模型预测结果与真实结果之间的差异,训练的目标是最小化损失函数,从而提高模型的准确性。
优化:优化是调整模型参数以最小化损失函数的过程,常见的优化方法有梯度下降、随机梯度下降等。
机器学习的工作流程通常包括以下几个主要步骤:
数据收集:首先,我们需要收集相关的、具有代表性的数据。数据可以从多种途径获取,如公共数据集、用户生成的数据、传感器等。
数据预处理:收集到的数据往往不直接适合用于训练,因此需要进行清理和预处理。这包括去除缺失数据、去除噪音、标准化等操作。
模型选择与训练:选择适合问题的机器学习模型,并使用训练数据进行训练。训练过程的目的是让模型根据数据学习规律,优化其内部参数。
模型评估与调优:通过验证数据集评估模型的性能,并根据评估结果调整模型参数,进一步优化其性能。
部署与监控:模型训练完成后,可以将其部署到实际应用中进行预测和决策。同时,需要监控模型在实际环境中的表现,必要时进行更新和调整。
线性回归(Linear Regression)是最基础的回归算法之一,用于预测一个连续的目标变量(例如房价、温度等)与一个或多个特征变量之间的关系。在本节中,我们将通过一个简单的例子,利用 PaddlePaddle 框架实现一个线性回归模型。
线性回归的目标是找到一个模型,使得输入特征 ( x ) 和输出值 ( y ) 之间的关系尽可能简单地表示为一个线性函数:
y=w⋅x+b
其中:
在训练过程中,我们希望通过最小化预测值 ( y ) 和真实值 $$ y_{\text{true}} $$ 之间的差距来调整模型的权重 ( w ) 和偏置 ( b )。
为了优化线性回归模型的参数(权重 ( w ) 和偏置 ( b )),我们需要定义一个损失函数,通常使用 均方误差(Mean Squared Error, MSE)作为损失函数:
MSE=N1i=1∑N(ypred(i)−ytrue(i))2
其中:
我们的目标是通过最小化这个损失函数来使得模型的预测结果尽可能接近实际值。
接下来,我们将使用 PaddlePaddle 来实现一个简单的线性回归模型。我们将随机生成一些数据,然后训练线性回归模型。
首先,我们需要导入 PaddlePaddle 框架以及一些辅助库。
import paddleimport numpy as npimport matplotlib.pyplot as plt
我们将生成一些简单的线性数据。假设目标变量 ( y ) 和输入特征 ( x ) 之间的关系是线性的:
y=3⋅x+2
!pip install openpyxl
Looking in indexes: https://mirror.baidu.com/pypi/simple/, https://mirrors.aliyun.com/pypi/simple/ Collecting openpyxl Downloading https://mirrors.aliyun.com/pypi/packages/c0/da/977ded879c29cbd04de313843e76868e6e13408a94ed6b987245dc7c8506/openpyxl-3.1.5-py2.py3-none-any.whl (250 kB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 250.9/250.9 kB 7.6 MB/s eta 0:00:00Collecting et-xmlfile (from openpyxl) Downloading https://mirrors.aliyun.com/pypi/packages/c1/8b/5fe2cc11fee489817272089c4203e679c63b570a5aaeb18d852ae3cbba6a/et_xmlfile-2.0.0-py3-none-any.whl (18 kB) Installing collected packages: et-xmlfile, openpyxl Successfully installed et-xmlfile-2.0.0 openpyxl-3.1.5
# 我们将使用这个关系生成一些样本数据。import numpy as npimport pandas as pd# 设置随机种子,确保结果可重复np.random.seed(0)# 生成100个随机数x_data = np.random.rand(100, 1).astype('float32')# 根据 y = 3x + 2 + 噪声 生成 y_datay_data = 3 * x_data + 2 + np.random.normal(0, 0.1, (100, 1)).astype('float32')# 创建 DataFramedf = pd.DataFrame({'x': x_data.flatten(), 'y': y_data.flatten()})# 保存到 Excel 文件df.to_excel('sample_data.xlsx', index=False)# 展示前10行数据print("前10行数据:")print(df.head(10))print("样本数据已保存到 'sample_data.xlsx'")前10行数据:
x y
0 0.548814 3.529926
1 0.715189 4.235651
2 0.602763 3.854856
3 0.544883 3.481025
4 0.423655 3.419790
5 0.645894 4.127271
6 0.437587 3.430640
7 0.891773 4.657326
8 0.963663 4.783913
9 0.383442 3.255770
样本数据已保存到 'sample_data.xlsx'在PaddlePaddle中,我们可以使用 paddle.nn.Linear 类来定义一个简单的线性回归模型。这个类会自动创建一个具有线性关系的模型,并初始化权重和偏置。
# 定义线性回归模型class LinearRegression(paddle.nn.Layer):
def __init__(self):
super(LinearRegression, self).__init__()
self.linear = paddle.nn.Linear(in_features=1, out_features=1) # 1个输入特征,1个输出特征
def forward(self, x): # 前向计算函数
return self.linear(x)我们接下来初始化模型、损失函数和优化器。在这里我们使用均方误差(MSE)作为损失函数,使用SGD(随机梯度下降)优化器来更新参数。
# 初始化模型model = LinearRegression()# 定义均方误差损失函数loss_fn = paddle.nn.MSELoss()# 使用随机梯度下降优化器optimizer = paddle.optimizer.SGD(learning_rate=0.1, parameters=model.parameters())
在训练过程中,我们将通过前向传播计算模型输出,然后使用损失函数计算预测值与真实值之间的误差,并通过反向传播优化模型参数。
# 转换数据为PaddleTensorx_tensor = paddle.to_tensor(x_data)
y_tensor = paddle.to_tensor(y_data)# 训练模型epochs = 200for epoch in range(epochs): # 前向传播
y_pred = model(x_tensor)
# 计算损失
loss = loss_fn(y_pred, y_tensor)
# 反向传播和优化
loss.backward()
optimizer.step()
optimizer.clear_grad() if (epoch + 1) % 20 == 0: # 每20个epoch输出一次损失值
print(f"Epoch [{epoch+1}/{epochs}], Loss: {loss.numpy()}")Epoch [20/200], Loss: 0.15615370869636536 Epoch [40/200], Loss: 0.09513530135154724 Epoch [60/200], Loss: 0.05957860127091408 Epoch [80/200], Loss: 0.038858912885189056 Epoch [100/200], Loss: 0.02678518369793892 Epoch [120/200], Loss: 0.019749531522393227 Epoch [140/200], Loss: 0.015649711713194847 Epoch [160/200], Loss: 0.013260645791888237 Epoch [180/200], Loss: 0.011868501082062721 Epoch [200/200], Loss: 0.011057266034185886
训练完成后,我们可以查看模型的预测结果,并将其与真实数据进行对比。
# 绘制训练数据plt.scatter(x_data, y_data, color='blue', label='True Data')# 使用训练好的模型进行预测y_pred = model(x_tensor).numpy()# 绘制预测数据plt.plot(x_data, y_pred, color='red', label='Fitted Line')
plt.legend()
plt.xlabel('X')
plt.ylabel('Y')
plt.title('Linear Regression - PaddlePaddle')
plt.show()<Figure size 640x480 with 1 Axes>
通过训练,我们的模型会学到一个接近真实的直线(3 * x + 2)。图像中蓝色的点代表实际数据,而红色的线代表我们训练得到的线性回归模型。
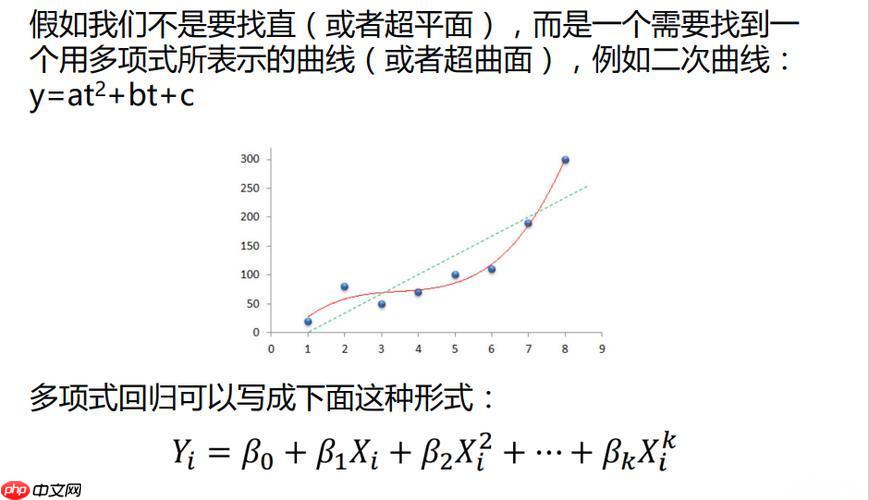
现在,我们将通过PaddlePaddle框架实现另一个机器学习中常见的基础 多项式回归(Polynomial Regression)模型。多项式回归是一种通过高次多项式函数来拟合数据的回归方法。它能够处理线性回归难以拟合的非线性数据。
多项式回归是一种扩展的线性回归方法。线性回归假设目标变量和输入特征之间存在线性关系,而多项式回归通过引入高次项,将输入特征转换为多项式形式,从而能够拟合非线性关系。
多项式回归的数学形式如下:
y=w0+w1x+w2x2+w3x3+⋯+wnxn
其中,( y ) 是目标变量,( x ) 是输入特征,( w_0, w_1, \dots, w_n ) 是模型的权重,( n ) 是多项式的阶数。
通过增加多项式的阶数,模型能够更好地拟合复杂的非线性关系,但也容易出现过拟合问题。因此,在实际应用中,我们需要小心调整多项式的阶数。
为了演示多项式回归模型,我们首先构建一个简单的示例数据集。我们使用正弦函数 (y=sin(x)) 作为目标函数,生成一个包含25个数据点的Toy数据集。
import numpy as npimport matplotlib.pyplot as pltimport pandas as pd# 生成Toy数据集:x在[0, 10]之间,y为sin(x)的值np.random.seed(0)
x_data = np.linspace(0, 10, 25).reshape(-1, 1).astype('float32') # 25个数据点y_data = np.sin(x_data) + np.random.normal(0, 0.1, x_data.shape).astype('float32') # 添加噪声# 数据标准化(归一化)x_max, x_min = np.max(x_data), np.min(x_data)
x_data = (x_data - x_min) / (x_max - x_min) # 将x数据归一化到[0, 1]之间# 将数据保存到 DataFramedf = pd.DataFrame({'x': x_data.flatten(), 'y': y_data.flatten()})# 保存到 Excel 文件df.to_excel('toy_data.xlsx', index=False)# 展示前10行数据print("数据集 前10行数据:")print(df.head(10))# 可视化数据plt.scatter(x_data, y_data, color='blue', label='Data')
plt.plot(x_data, np.sin(x_data), color='red', label='True Sin(x)', linestyle='--')
plt.xlabel('X')
plt.ylabel('Y')
plt.title('ToySin25 Data')
plt.legend()
plt.show()print("数据已保存到 'toy_data.xlsx'")数据集 前10行数据:
x y
0 0.000000 0.176405
1 0.041667 0.444730
2 0.083333 0.838051
3 0.125000 1.173074
4 0.166667 1.182164
5 0.208333 0.773775
6 0.250000 0.693481
7 0.291667 0.207898
8 0.333333 -0.200890
9 0.375000 -0.530501<Figure size 640x480 with 1 Axes>
数据已保存到 'toy_data.xlsx'
在上图中,蓝色点表示数据点,红色虚线表示真实的正弦函数。数据点在正弦函数附近波动,但也包含了一些噪声。
在PaddlePaddle中,我们可以通过构建一个自定义的 Layer 类来实现多项式回归。由于是回归任务,我们将使用一个简单的线性层来拟合数据,同时引入多项式特征。
# 定义多项式回归模型class PolynomialRegression(nn.Layer):
def __init__(self, degree):
super(PolynomialRegression, self).__init__()
self.degree = degree # 创建多项式的系数参数
self.coefficients = self.create_parameter(
shape=[degree + 1, 1], # 多项式的参数个数为 degree + 1
dtype='float32',
default_initializer=nn.initializer.Normal(mean=0, std=0.1) # 使用正态分布初始化
)
def forward(self, x):
# 计算多项式的输出
y_pred = paddle.zeros_like(x) for i in range(self.degree + 1):
y_pred += self.coefficients[i] * (x ** i) return y_pred在这个模型中,我们首先通过 paddle.pow 函数生成高次多项式特征,然后将这些特征传递给线性层进行预测。
现在,我们可以通过定义损失函数(均方误差)和优化器(如SGD)来训练我们的多项式回归模型。
# 转换数据为PaddleTensorx_tensor = paddle.to_tensor(x_data)
y_tensor = paddle.to_tensor(y_data)# 初始化模型,损失函数和优化器degree = 5 # 多项式的阶数model = PolynomialRegression(degree)
loss_fn = nn.MSELoss()
optimizer = paddle.optimizer.Adam(learning_rate=0.01, parameters=model.parameters()) # 降低学习率# 训练模型epochs = 10000for epoch in range(epochs): # 前向传播
y_pred = model(x_tensor)
# 计算损失
loss = loss_fn(y_pred, y_tensor)
# 反向传播和优化
loss.backward()
optimizer.step()
optimizer.clear_grad() if (epoch + 1) % 1000 == 0: # 每100个epoch输出一次损失值
print(f"Epoch [{epoch+1}/{epochs}], Loss: {loss.numpy()}")Epoch [1000/10000], Loss: 0.2618849277496338 Epoch [2000/10000], Loss: 0.22850266098976135 Epoch [3000/10000], Loss: 0.19773395359516144 Epoch [4000/10000], Loss: 0.16594302654266357 Epoch [5000/10000], Loss: 0.1382530927658081 Epoch [6000/10000], Loss: 0.11737764626741409 Epoch [7000/10000], Loss: 0.1040974110364914 Epoch [8000/10000], Loss: 0.09691537916660309 Epoch [9000/10000], Loss: 0.09346676617860794 Epoch [10000/10000], Loss: 0.09180866181850433
在这个训练过程中,我们使用均方误差(MSE)作为损失函数,并通过梯度下降优化器更新模型的参数。
训练完成后,我们可以通过可视化模型的预测结果与真实值的对比来评估模型的性能。
# 预测结果y_pred = model(x_tensor).numpy()# 可视化预测结果plt.scatter(x_data, y_data, color='blue', label='True Data')
plt.plot(x_data, y_pred, color='green', label='Predicted Line', linestyle='--')
plt.xlabel('X')
plt.ylabel('Y')
plt.title('Polynomial Regression - Degree 5')
plt.legend()
plt.show()<Figure size 640x480 with 1 Axes>
从图中可以看到,绿色的虚线是我们的多项式回归模型的预测结果,它能够很好地拟合数据,尤其是在数据波动的区域。
多项式回归的一个主要问题是容易过拟合,特别是当多项式阶数较高时。为了缓解过拟合问题,我们可以引入 L2正则化(也叫Ridge回归)。L2正则化通过在损失函数中加入模型参数的平方和来限制模型的复杂度,从而避免过拟合。
# 定义带L2正则化的损失函数regularization_factor = 0.01 # 正则化系数# 训练模型for epoch in range(epochs): # 前向传播
y_pred = model(x_tensor)
# 计算正则化损失
regularization_loss = sum(paddle.norm(param) ** 2 for param in model.parameters())
# 计算总损失
loss = loss_fn(y_pred, y_tensor) + regularization_factor * regularization_loss
# 反向传播和优化
loss.backward(retain_graph=True) # 保持计算图
optimizer.step()
optimizer.clear_grad() if (epoch + 1) % 1000 == 0: print(f"Epoch [{epoch+1}/{epochs}], Loss: {loss.numpy()}")Epoch [1000/10000], Loss: 0.40152958035469055 Epoch [2000/10000], Loss: 0.40152958035469055 Epoch [3000/10000], Loss: 0.40152955055236816 Epoch [4000/10000], Loss: 0.40152958035469055 Epoch [5000/10000], Loss: 0.4015296399593353 Epoch [6000/10000], Loss: 0.40152958035469055 Epoch [7000/10000], Loss: 0.40153011679649353 Epoch [8000/10000], Loss: 0.40152958035469055 Epoch [9000/10000], Loss: 0.4015297591686249 Epoch [10000/10000], Loss: 0.40152961015701294
# 预测结果y_pred = model(x_tensor).numpy()# 可视化预测结果plt.scatter(x_data, y_data, color='blue', label='True Data')
plt.plot(x_data, y_pred, color='green', label='Predicted Line', linestyle='--')
plt.xlabel('X')
plt.ylabel('Y')
plt.title('Polynomial Regression - Degree 5 -- L2 ')
plt.legend()
plt.show()<Figure size 640x480 with 1 Axes>
(引入正则化后,我们可以观察到loss最终值明显比之前偏高,当然这时如果预测肯定是不准确的,所以实际这部分的应用需要结合实际情况使用)
代码说明: • retain_graph=True:在调用 loss.backward() 时,指定 retain_graph=True 参数来保持计算图。这样可以保证计算图不被清除,从而可以进行后续的反向传播。
注意事项: • 使用 retain_graph=True 会增加内存消耗,尤其是对于大的计算图,因此只有在必要时才使用它。如果你没有多次调用 backward(),可以不需要使用 retain_graph=True,但在此情况下,由于正则化项的计算,反向传播可能需要多次调用。
进一步优化:
如果正则化项与损失函数计算是一起做的,而且你确定不需要在每次 backward() 之前保留计算图,你可以尝试将正则化项的计算与常规损失的反向传播放在同一次反向传播中:
# 计算损失并同时包含正则化项loss = loss_fn(y_pred, y_tensor) + regularization_factor * sum(paddle.norm(param) ** 2 for param in model.parameters())# 反向传播和优化loss.backward() optimizer.step() optimizer.clear_grad()
以上就是【PaddlePaddle】基础理论教程 - 算子与机器学习概述的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 290
290























