该项目基于飞桨构建模型对Fashion-MNIST数据集分类。数据集含60000张训练图、10000张测试图,为28x28灰度图,分10类。项目先解压数据、查看概览,再划分训练集与验证集(8:2),计算均值和方差,定义数据读取器。构建简单卷积神经网络,经两次训练(固定和变动学习率),评估得精度0.91225,最后保存模型并实现预测功能。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

- 图像分类(image classification)是计算机视觉领域中最简单最基础的任务,学习研究图像分类是每个计算机视觉研究者的必经之路,图像分类网络也是很多更复杂任务(如目标检测、语义分割等)算法的基础。
- 项目目标:构建一种机器学习算法模型,对Fashion-MNIST数据集正确分类
- 环境要求:飞桨 PaddlePaddle 2.2 及以上版本
- Fashion-MNIST由60000张训练集图像、10000张测试集图像及对应的标签构成,每张图像是分辨率为28x28的灰度图像,包含10种分类:T恤、裤子、套头衫、连衣裙、大衣、凉鞋、衬衫、运动鞋、包、短靴。
- 数据特点:图片太小,但数量充足,标签分布均匀
- 项目概述:
- 主要思路:数据图片是灰度图形式,数量充足,但是28 * 28 的尺寸是比较小的,因此考虑对原始数据进行放大处理,以使特征充分暴露。也可考虑其他数据增强方式,比如制作jia的RGB三通道图像等。
- 操作过程:分析数据--》划分数据集--》构建数据读取器--》构建网络模型--》训练模型--》评估模型--》保存模型--》调用模型进行预测
- 模型问题:本项目手动构建了一个简单模型,结构比较简单、原始,但好处是规模较小,容易训练,效果也还可以吧。另外这个小模型还有个好处,就是你可以很方便的对结构进行变更,来比较不同的模型配置的实际效果。针对本项目,层数越多未必越好,卷积核太大效果也不太理想。
- 训练问题:本项目进行了两次训练,第一次使用固定学习率,第二次使用了变动学习率,以进一步提升精度。训练中要特别注意曲线变化,因为模型很小,很容易过拟合。
- 一个瑕疵:使用 interpolation=cv2.INTER_CUBIC 方式放大图片的效果比默认方式好,但有个副作用:每次放大生成的图片可能略有不同,导致均值和方差的计算结果不是定值,喂给模型的图片也会存在细微差别,虽然人眼看不出来。但从实际的训练效果来看,似乎影响不大。
- 一个坑:图片分类模型的输出层通常接一个softmax,虽然这并不会对精度提升有帮助,但是会使输出的结果比较规矩。但是需要注意:使用 paddle.nn.CrossEntropyLoss 做损失函数时,如果模型中已经有了sofmax输出层,则应该设置 use_softmax = False,否则会导致训练失败,loss值不下降。
- 这个示例使用 paddle version:2.3.0
- 使用pandas处理csv文件
- 使用cv2对图片进行放大
# import 导入模块import paddlefrom paddle.io import Dataset#from paddle.vision.transforms import functional as F#from paddle.vision.transforms import RandomRotation#from paddle.vision import transforms#import matplotlibimport matplotlib.pyplot as plt#import PIL.Image as Imageimport numpy as npimport pandas as pdimport cv2import osimport shutilimport zipfile#import platform#import globimport random#import datetime#---打印paddle 版本print(f"paddle version:{paddle.__version__}")
- 数据集链接:https://aistudio.baidu.com/aistudio/datasetdetail/145250
- 数据以csv文件方式提供
- 解压并查看数据
# func 解压zip文件def unzip_files(file_path,unzip_path):
zipFile = zipfile.ZipFile(file_path) try: for file in zipFile.namelist():
zipFile.extract(file, unzip_path) except: pass
finally:
zipFile.close()# 定义这个解压函数不是必须的,仅仅是为了跨系统时代码可以通用。也可以手动解压,Linux 可以使用unzip等工具# run 解压训练数据# 28*28灰度图,10种分类:T恤、裤子、套头衫、连衣裙、大衣、凉鞋、衬衫、运动鞋、包、短靴fd_data = "./data/" # data文件夹#zip_file_path = "./data/fashion-mnist_train.zip" # 训练数据zip_file_path = "./data/data145250/fashion-mnist_train.zip" # 训练数据 aistudio数据挂载路径unzip_files(os.path.normpath(zip_file_path),os.path.normpath(fd_data)) # 解压训练数据# 压缩包里面有两个文件,“fashion-mnist_train.csv”是训练数据,“fashion-mnist_test_data.csv”是测试数据
# run 查看原始数据train_csv_path = "./data/fashion-mnist_train.csv"train_csv = pd.read_csv(os.path.normpath(train_csv_path))print(train_csv)# fashion-mnist_train.csv 这个文件中,第一列是标签,后面是灰度图每一个像素点对应的灰度值,运行这段代码可以看到基本文件结构
# run 对标签数量进行统计train_csv["label"].value_counts()# 这个统计是为了查看数据的分布情况。这个数据集的分布非常均匀,每一个标签的图片数量都是6000
9 6000 8 6000 7 6000 6 6000 5 6000 4 6000 3 6000 2 6000 1 6000 0 6000 Name: label, dtype: int64
# func 传入索引,提取图片img_e_h, img_e_w = 96, 96 # 放大尺寸def get_pic(row_idx, data_csv, enlarge=False):
img_data = list(data_csv.loc[row_idx]) # 获取一行数据
img_label = img_data[0] # 获取标签
img = img_data[1:] # 获取数据
img = np.array(img,dtype="uint8") # 转换为np数组
img.resize(img_h,img_w) # 还原成28*28
if(enlarge): # 放大图片
img = cv2.resize(img, (img_e_h, img_e_w), interpolation=cv2.INTER_CUBIC) # interpolation=cv2.INTER_CUBIC效果好但速度慢,而且每次放大的结果都稍有不同
#img = cv2.resize(img, (img_e_h, img_e_w)) # 使用默认放大方式,执行此行
return (img_label, img)# 这个函数用于从csv文件中提取还原出图片# 函数中有一个放大操作,这里是放大到96*96,这个时候人眼已经可以比较轻松的识别了# 原始图片非常小,不好操作,所以考虑进行放大处理# 没有放大到整数倍,是因为担心放大到整数倍对于计算机来说没有多大意义# 也可以放到很大,但是模型参数会比较多,96*96相对比较适中# fashion-mnist_train.csv 文件中的第一列是标签,fashion-mnist_test_data.csv 文件中的第一列是索引,所以训练和测试可以共用这个函数# run 随机查看一张图片img_h, img_w = 28, 28 # 图片高度和宽度label_list = ["T恤","裤子","套头衫","连衣裙","大衣","凉鞋","衬衫","运动鞋","包","短靴"] # 标签列表row_count = train_csv.shape[0] # 获取行数 60000row_idx = random.randint(0 ,row_count - 1) # 随机生成一个行索引label1, img1 = get_pic(row_idx, train_csv)print(f"Label for a random pic:{label_list[label1]}")
plt.imshow(img1,cmap="gray") # 显示灰度图# 尝试还原一张图片,看看原始图片的样子# 这段代码同时初始化了标签列表Label for a random pic:连衣裙
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/cbook/__init__.py:2349: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working if isinstance(obj, collections.Iterator): /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/cbook/__init__.py:2366: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working return list(data) if isinstance(data, collections.MappingView) else data
<matplotlib.image.AxesImage at 0x7f8aa2967150>
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/image.py:425: DeprecationWarning: np.asscalar(a) is deprecated since NumPy v1.16, use a.item() instead a_min = np.asscalar(a_min.astype(scaled_dtype)) /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/image.py:426: DeprecationWarning: np.asscalar(a) is deprecated since NumPy v1.16, use a.item() instead a_max = np.asscalar(a_max.astype(scaled_dtype))
<Figure size 432x288 with 1 Axes>
# run 尝试将图片放大label1, img1 = get_pic(row_idx, train_csv, enlarge=True)print(f"Label for a random pic:{label_list[label1]}")
plt.figure(figsize=(8,8),dpi=50) #修改显示的图像大小#plt.axis('off')plt.imshow(img1,cmap="gray")print(np.array(img1).shape)# 尝试将图片放大,看看放大后的效果Label for a random pic:连衣裙 (96, 96)
<Figure size 400x400 with 1 Axes>
- 分割训练集和验证集
- 训练集和验证集比例:8:2
- 计算均值和方差
- 定义了两个计算均值和标准差的函数,实际使用的是第二个
- 放大图片使用了interpolation=cv2.INTER_CUBIC,这个放大方法得到的图片并不总是一定的,这导致对均值和标准差的计算结果存在不确定性
- 定义数据读取器
- interpolation=cv2.INTER_CUBIC放大方法的问题,使得:即使是同一张图片,每次喂给模型的数据会存在非常细微的不同
- 准备训练集和验证集
# run 划分 训练集和验证集idx_split = int(row_count*0.8) # 前80%设置为训练集print(idx_split) # 48000# 原始数据集已经是乱序排列,所以没有在进行乱序处理,直接计算出一个分割值
48000
# func 计算原始图片的均值和标准差def calc_means_stdevs():
means, stdevs = 0, 0 # 均值和标准差
pix_count = img_h*img_w*row_count # 像素总数
sum = train_csv.iloc[:,1:].sum(axis=1) # 对所有行的第1列到最末列求和
sum = np.array(sum) # 转成np数组
sum = sum.sum() # 求和
means = sum / pix_count # 均值
print(f"means:{means}")
data_all = train_csv.iloc[:,1:] # 获取所有数据
data_all = np.array(data_all) # 转成np数组
data_all = data_all - means # 减去均值
data_all = data_all**2 # 平方
stdevs = np.sqrt(data_all.sum() / pix_count) # 得到标准差
print(f"stdevs:{stdevs}") return (means, stdevs)# 这个函数不是必须的,因为我这里是使用放大后的图片,仅列示出来以供参考# func 计算放大后图片的均值和标准差def calc_means_stdevs_enlarge():
means, stdevs = 0, 0 # 均值和标准差
pix_count = img_e_h*img_e_w*row_count # 像素总数
sum = 0 # 求和
for idx in range(0, row_count):
label1, img1 = get_pic(row_idx, train_csv, enlarge=True) # 获取放大后的图片
img1 = np.array(img1) # 转成np数组
sum += img1.sum() # 计算和
means = sum / pix_count # 均值
print(f"means:{means}")
sum1 = 0 # 减均值,然后求平方和
for idx in range(0, row_count):
label1, img1 = get_pic(row_idx, train_csv, enlarge=True) # 获取放大后的图片
img1 = np.array(img1) # 转成np数组
img1 = img1 - means # 减均值
img1 = img1 ** 2 # 平方
sum1 += img1.sum() # 计算和
stdevs = np.sqrt(sum1 / pix_count) # 得到标准差
print(f"stdevs:{stdevs}") return (means, stdevs)# 这个函数用来计算放大后的图片的均值和标准差,因为我们要把放大后的图片喂给模型# 由于放大方式使用了interpolation=cv2.INTER_CUBIC,这个方法的放大结果存在一定不确定性,导致均值和标准差的计算结果也存在一定不确定性# 使用 interpolation=cv2.INTER_CUBIC是我这个示例的瑕疵之一,但从实际效果来看,似乎影响甚微# run 计算均值和标准差#means, stdevs = 0, 1 # 不使用减均值除标准差的处理,执行此行#means, stdevs = calc_means_stdevs() # 要使用原始数据的均值和方差,执行此行means, stdevs = calc_means_stdevs_enlarge() # 要使用放大后图片的均值和方差,执行此行
means:61.16547309027778 stdevs:54.048929187014885
# class 定义数据读取器class DataReader(Dataset):
def __init__(self,
means, #均值
stdevs, #标准差
data_csv, # 数据
mode='train_set'): # train_set val_set
"""
初始化函数
"""
self.mode = mode
self.data = []
self.data_csv = data_csv
self.means = means
self.stdevs = stdevs
idx_begin = 0
idx_end = idx_split # 分割点
if mode == 'train_set': pass
elif mode == "val_set":
idx_begin = idx_split
idx_end = row_count # 总条数
for idx in range(idx_begin, idx_end):
d_row = list(train_csv.loc[idx]) # 取出一行
d_label = d_row[0] # 分离出标签
#d_date = d_row[1:] # 分离出数据
self.data.append([idx, d_label]) print(f"size of {mode}:{len(self.data)}")
def __getitem__(self, index):
"""
读取图片,对图片进行归一化处理,返回图片和 标签
"""
row_idx, label = self.data[index] # 获取数据
label, img = get_pic(row_idx, train_csv, enlarge=True) # 获取图片,并放大
img = np.array(img, dtype="float32") # 转换为np数组,float32格式
img = img - self.means # 减均值
img = img / self.stdevs # 除方差
img = img / 255 # 归一化
img = np.expand_dims(img, axis=0) #扩展一个维度
return img, np.array(label, dtype='int64') def __len__(self):
"""
获取样本总数
"""
return len(self.data)# 喂给模型的是处理好的数据,处理方法要在这里定义好# run 准备数据集读取器train_dataset = DataReader(means, stdevs, train_csv, 'train_set') # 训练集数据加载器val_dataset = DataReader(means, stdevs, train_csv, 'val_set') # 评估集数据加载器idx_max = train_dataset.__len__()
idx = random.randint(0 ,idx_max - 1) # 随机生成一个索引data, label = train_dataset[idx] # 随机取出一个数据print(f"data label:{label}")print(f"data shape:{np.array(data).shape}")print(f"data content:\n{data}")
- 定义网络模型
- 自定义了一个简单模型
- 准备模型网络

# class 构造模型class FashionNet(paddle.nn.Layer): # 自定义的类
def __init__(self, num_classes=10, model_name="model_mk0"): # 输出的分类数,模型名称
super(FashionNet, self).__init__()
self.model_name = model_name
self.conv1 = paddle.nn.Conv2D(in_channels=1, out_channels=96, kernel_size=(5, 5), stride=1, padding = 1) #self.pool1 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.relu1=paddle.nn.ReLU()
self.conv2 = paddle.nn.Conv2D(in_channels=96, out_channels=96, kernel_size=(3,3), stride=2, padding = 0) #self.pool2 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.relu2=paddle.nn.ReLU()
self.conv3 = paddle.nn.Conv2D(in_channels=96, out_channels=96, kernel_size=(3,3), stride=2, padding = 0)
self.relu3=paddle.nn.ReLU()
self.conv4 = paddle.nn.Conv2D(in_channels=96, out_channels=96, kernel_size=(3,3), stride=2, padding = 1) #self.pool4 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.relu4=paddle.nn.ReLU() #self.conv5 = paddle.nn.Conv2D(in_channels=96, out_channels=96, kernel_size=(5,5), stride=1, padding = 1)
#self.pool5 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
#self.relu5=paddle.nn.ReLU()
self.flatten = paddle.nn.Flatten()
#self.linear1 = paddle.nn.Linear(in_features=14336, out_features=224)
self.linear1 = paddle.nn.Linear(in_features=11616, out_features=96)
self.relu6=paddle.nn.ReLU()
self.linear2 = paddle.nn.Linear(in_features=96, out_features=num_classes)
self.sm1 = paddle.nn.Softmax()
def forward(self, x):
x = self.conv1(x) #x = self.pool1(x)
x = self.relu1(x)
x = self.conv2(x)
x = self.relu2(x)
x = self.conv3(x)
x = self.relu3(x)
x = self.conv4(x) #x = self.pool4(x)
x = self.relu4(x) #x = self.conv5(x)
#x = self.relu5(x)
x = self.flatten(x)
x = self.linear1(x)
x = self.relu6(x)
x = self.linear2(x)
x = self.sm1(x)
return x# run 准备网络model = paddle.Model(FashionNet(num_classes=10,model_name="fashion_mk1"))print(f"model name:{model.network.model_name}")
model.summary((1, 1, 96, 96))model name:fashion_mk1
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
Conv2D-9 [[1, 1, 96, 96]] [1, 96, 94, 94] 2,496
ReLU-6 [[1, 96, 94, 94]] [1, 96, 94, 94] 0
Conv2D-10 [[1, 96, 94, 94]] [1, 96, 46, 46] 83,040
ReLU-7 [[1, 96, 46, 46]] [1, 96, 46, 46] 0
Conv2D-11 [[1, 96, 46, 46]] [1, 96, 22, 22] 83,040
ReLU-8 [[1, 96, 22, 22]] [1, 96, 22, 22] 0
Conv2D-12 [[1, 96, 22, 22]] [1, 96, 11, 11] 83,040
ReLU-9 [[1, 96, 11, 11]] [1, 96, 11, 11] 0
Flatten-3 [[1, 96, 11, 11]] [1, 11616] 0
Linear-5 [[1, 11616]] [1, 96] 1,115,232
ReLU-10 [[1, 96]] [1, 96] 0
Linear-6 [[1, 96]] [1, 10] 970
Softmax-3 [[1, 10]] [1, 10] 0
===========================================================================
Total params: 1,367,818
Trainable params: 1,367,818
Non-trainable params: 0
---------------------------------------------------------------------------
Input size (MB): 0.04
Forward/backward pass size (MB): 17.02
Params size (MB): 5.22
Estimated Total Size (MB): 22.27
---------------------------------------------------------------------------{'total_params': 1367818, 'trainable_params': 1367818}
- 配置参数,加载数据,训练模型
- 模型中已经使用了softmax做输出层,在使用CrossEntropyLoss时不需要使用softmax做归一化,需要配置use_softmax = False
- 模型训练了两次,第一次使用固定学习率,第二次使用变动学习率
# run 训练模型 固定学习率fd_visualdl_log = "visualdl_log" # visualdl log文件夹lr = 5e-5 # 学习率 0.00005optim = paddle.optimizer.Adam(learning_rate=lr, parameters=model.parameters()) # 优化器visualdl = paddle.callbacks.VisualDL(log_dir=fd_visualdl_log) # VisualDL工具的回调函数model.prepare(optim,
paddle.nn.CrossEntropyLoss(use_softmax = False), # 因为模型中已经使用了softmax做输出层,因此这里面不需要使用softmax做归一化
paddle.metric.Accuracy()) # 验证函数model.fit(train_dataset, # 训练数据集
val_dataset, # 评估数据集
epochs=7, # 训练的总轮次
batch_size=5, # 训练使用的批大小,使用变动学习率时,batch_size最好小一些,6,8
verbose=1, # 设置可视化
callbacks=[visualdl]) # visualdl# 第一次训练,先使用固定学习率看看效果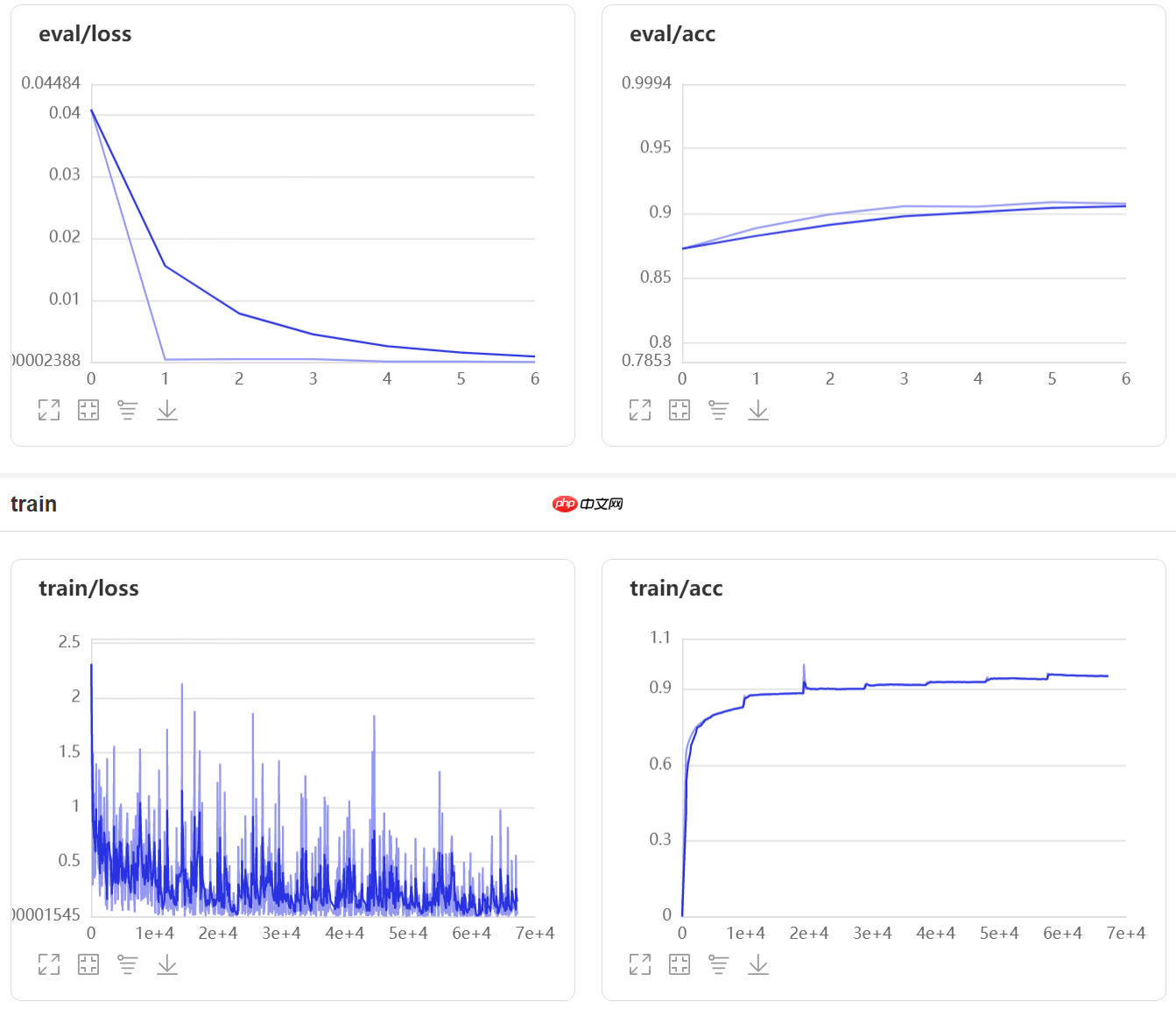
# run 训练模型 变动学习率fd_visualdl_log = "visualdl_log" # visualdl log文件夹lr = 5e-5 # 学习率scheduler = paddle.optimizer.lr.LinearWarmup(
learning_rate=lr, warmup_steps=20, start_lr=5e-5, end_lr=3e-4, verbose=False)
optim = paddle.optimizer.Adam(learning_rate=scheduler, parameters=model.parameters())
visualdl = paddle.callbacks.VisualDL(log_dir=fd_visualdl_log) # VisualDL工具的回调函数model.prepare(optim,
paddle.nn.CrossEntropyLoss(use_softmax = False), # 因为模型中已经使用了softmax做输出层,因此这里面不需要使用softmax做归一化
paddle.metric.Accuracy()) # 验证函数model.fit(train_dataset, # 训练数据集
val_dataset, # 评估数据集
epochs=7, # 训练的总轮次
batch_size=5, # 训练使用的批大小,使用变动学习率时,batch_size最好小一些,6,8
verbose=1, # 设置可视化
callbacks=[visualdl]) # visualdl# 第二次训练,这次加了个wormup,看看是不是能提升一下精度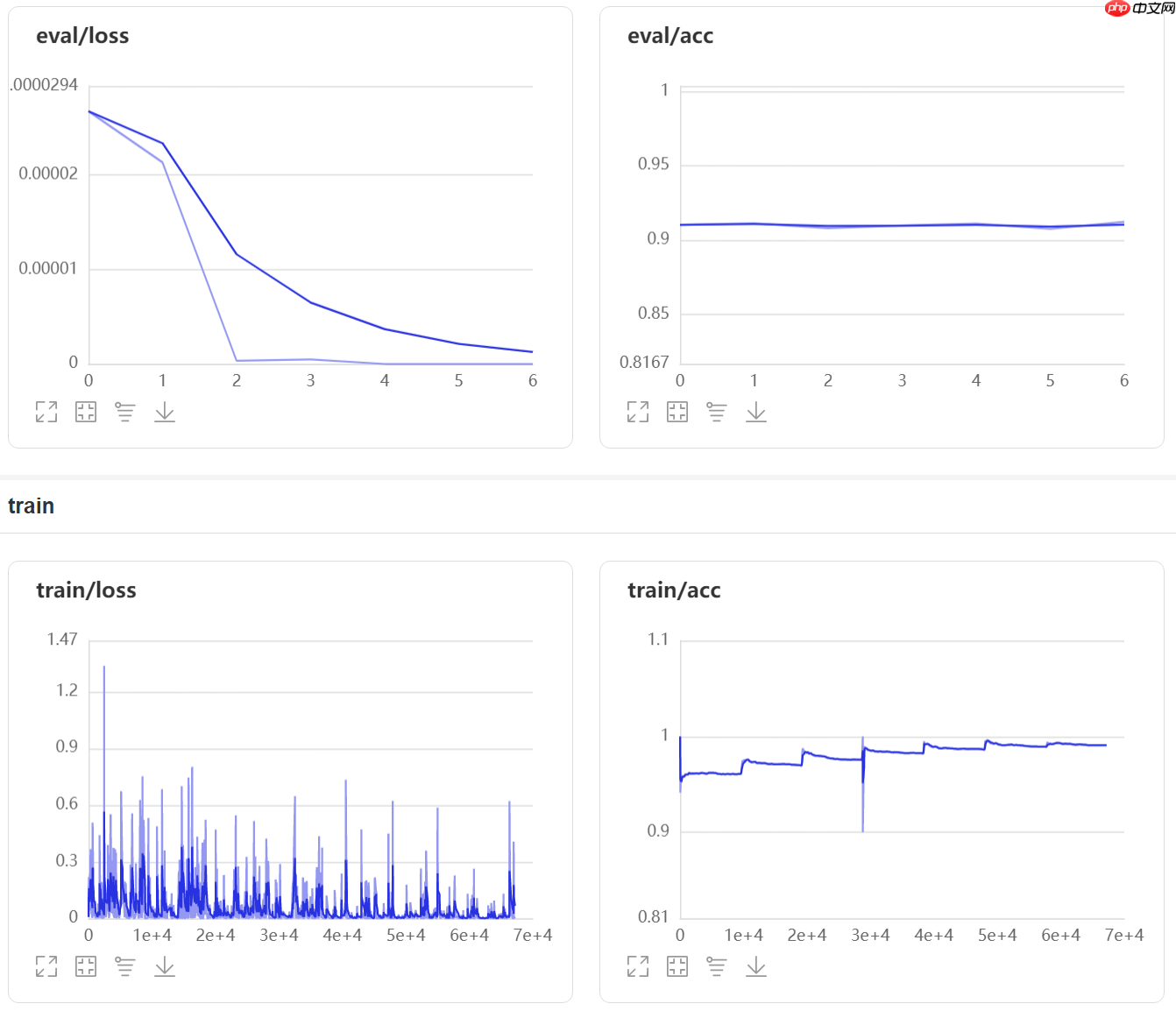
- 评估模型训练效果
# run 评估模型result = model.evaluate(val_dataset, verbose=1)print(result)# 由于模型结构非常简单原始,这大概是这个模型能达到的最好效果了
Eval begin...
step 12000/12000 [==============================] - loss: -0.0000e+00 - acc: 0.9123 - 5ms/step
Eval samples: 12000
{'loss': [-0.0], 'acc': 0.91225}
- 保存训练的结果
# func 保存模型参数的函数fd_model_save = "./model_save/" #模型保存目录os.path.normpath(fd_model_save)def model_save(model):
if os.path.exists(os.path.normpath(fd_model_save)):shutil.rmtree(os.path.normpath(fd_model_save)) #保存模型的文件夹
print(f"saving model {model.network.model_name} for training...")
model.save(fd_model_save+model.network.model_name) # save for training
print(f"saving model {model.network.model_name} for inference...")
model.save(fd_model_save+model.network.model_name, False) # save for inference
print(f"model {model.network.model_name} has been saved to {fd_model_save}")# 这个函数用来 把训练好的模型保存起来,以用于日后调用或者再次训练# run 保存模型model_save(model)
saving model fashion_mk1 for training... saving model fashion_mk1 for inference... model fashion_mk1 has been saved to ./model_save/
- 用训练的模型进行预测
- 随机选取一个test集中的数据进行预测
# run 解压test数据集fd_data = "./data/" # data文件夹#zip_file_path = "./data/fashion-mnist_test_data.zip" # test数据zip_file_path = "./data/data145250/fashion-mnist_test_data.zip" # test数据 aistudio数据挂载路径unzip_files(os.path.normpath(zip_file_path),os.path.normpath(fd_data)) # 解压test数据# 把test数据集解压出来,这里复用了解压函数,也可以手动解压
# run 查看test原始数据test_csv_path = "./data/fashion-mnist_test_data.csv"test_csv = pd.read_csv(os.path.normpath(test_csv_path))print(test_csv)# test数据和训练数据的唯一却别是,第一列不是标签而是索引值,这样就可以复用前面定义的图片提取并放大的函数
# run 查看一张随机 test集图片row_count = test_csv.shape[0] # 获取行数 60000row_idx = random.randint(0 ,row_count - 1) # 随机生成一个行索引idx1, img1 = get_pic(row_idx, test_csv) plt.imshow(img1,cmap="gray") # 显示灰度图# 随机查看一张test图片,先人眼判断一下
<matplotlib.image.AxesImage at 0x7f8a19329510>
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/image.py:425: DeprecationWarning: np.asscalar(a) is deprecated since NumPy v1.16, use a.item() instead a_min = np.asscalar(a_min.astype(scaled_dtype)) /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/image.py:426: DeprecationWarning: np.asscalar(a) is deprecated since NumPy v1.16, use a.item() instead a_max = np.asscalar(a_max.astype(scaled_dtype))
<Figure size 432x288 with 1 Axes>
# func 模型预测函数,传入模型类、模型名称、图片索引、数据集dataframe,加载模型并预测数据def model_predict(my_net,model_name,img_idx,data_csv):
#paddle.set_device('gpu:1')
#paddle.set_device('cpu')
#定制化模型(无需label)
input_define = paddle.static.InputSpec(shape=[1,3,112,112], dtype="float32", name="img")
model = paddle.Model(my_net(num_classes=10,model_name=model_name),input_define) #加载模型参数
model_path = os.path.join(os.path.normpath(fd_model_save), model_name)
model.load(model_path)
model.prepare()
idx, img = get_pic(row_idx, data_csv, enlarge=True) # 获取图片,并放大
img = np.array(img, dtype="float32") # 转换为np数组,float32格式
img = img - means # 减均值
img = img / stdevs # 除方差
img = img / 255 # 归一化
img = np.expand_dims(img, axis=0) # 扩展一个维度
img = np.expand_dims(img, axis=0) # 扩展一个维度
#img = paddle.to_tensor(img)
result = model.predict(test_data=[img]) #print(result)
#idx = np.argmax(result)
#print(f"result:[{label_list[idx]}]")
return result# 这个函数用来调用已经保存的模型,然后对传入的数据进行预测# run 用模型预测选取的图片,并打印输出预测结果result = model_predict(FashionNet,"fashion_mk1",idx1,test_csv)print(result)
idx = np.argmax(result)print(f"result:[{label_list[idx]}]")# 把刚才随机选出的图片交给模型进行预测,看看预测的结果Predict begin...
step 1/1 [==============================] - 4ms/step
Predict samples: 1
[(array([[5.2177566e-13, 3.2803663e-15, 1.3896773e-05, 1.4886105e-16,
9.9998593e-01, 3.0198786e-18, 2.2157795e-07, 9.9112047e-19,
1.9151252e-12, 2.9413131e-20]], dtype=float32),)]
result:[大衣]针对本项目:
- 使用 interpolation=cv2.INTER_CUBIC 方式放大图片的效果比默认方式好,但有个副作用:每次放大生成的图片可能略有不同,导致均值和方差的计算结果不是定值
- 大卷积核未必效果好
- 图片放大到 96 * 96 比放大到 112 * 112 或 224 * 224 更划算
- 学习率,5e-5比3e-4 效果好
- 使用变动的学习率,效果往往更好
- 层数多未必好用
- 使用 paddle.nn.CrossEntropyLoss 做损失函数时,如果模型中已经有了sofmax输出层,则应该设置 use_softmax = False
# run 清理文件if os.path.exists("visualdl_log"):shutil.rmtree("visualdl_log") #visualdl_log文件夹if os.path.exists(os.path.normpath(fd_model_save)):shutil.rmtree(os.path.normpath(fd_model_save)) #保存模型的文件夹# 如果数据有用,可不必清理# 但是在测试过程中,应该保持一个良好的习惯# 查看可视化曲线 :(本地运行时)终端运行 visualdl --logdir ./visualdl_log
以上就是【AI达人特训营】服装分类:Fashion-MNIST数据集的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 165
165
























