本文介绍飞桨图像分类套件PaddleClas竞赛实战方法,包括模型库概览,其提供服务器端和端侧模型;还讲解了竞赛实战的前置条件、数据集准备、模型训练评估、数据增广、图像推理等,最后提及番外篇用PaddleX做图像分类。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

前情提要
前置课程:图像分类课程(1)
通过上一次课程的学习,相信大家对于如何搭建一个分类网络已经清晰了。那么我们不禁会想,有没有更快速的尝试模型及技巧的方法呢?因为我们在上一次课程中使用的代码都需要自己进行开发,自己写需要很多的精力。PaddleClas作为飞桨的一个图像分类套件,已经为大家把所有的内容都写好了,只需要大家选择模型、并适配自己的数据集即可。
- 本文原作者:@李长安
- 新增VisualDL、提交脚本和PaddleX番外
飞桨图像分类套件PaddleClas竞赛实战
PaddleClas 是什么?
PaddleClas是飞桨为工业界和学术界所准备的一个图像分类任务的工具集,助力使用者训练出更好的视觉模型和应用落地。PaddleClas提供了基于图像分类的模型训练、评估、预测、部署全流程的服务,方便大家更加高效地学习图像分类。
下面将从PaddleClas模型库概览、特色应用、快速上手、实践应用几个方面介绍PaddleClas实践方法:
- PaddleClas模型库概览:概要介绍PaddleClas有哪些分类网络结构和预训练模型。
- PaddleClas柠檬竞赛实战:重点介绍数据增广方法。
1.1 PaddleClas模型库概览
图像分类模型有大有小,其应用场景各不相同,在云端或者服务器端应用时,一般情况下算力是足够的,更倾向于应用高精度的模型;在手机、嵌入式等端侧设备中应用时,受限于设备的算力和内存,则对模型的速度和大小有较高的要求。PaddleClas同时提供了服务器端模型与端侧轻量化模型来支撑不同的应用场景。
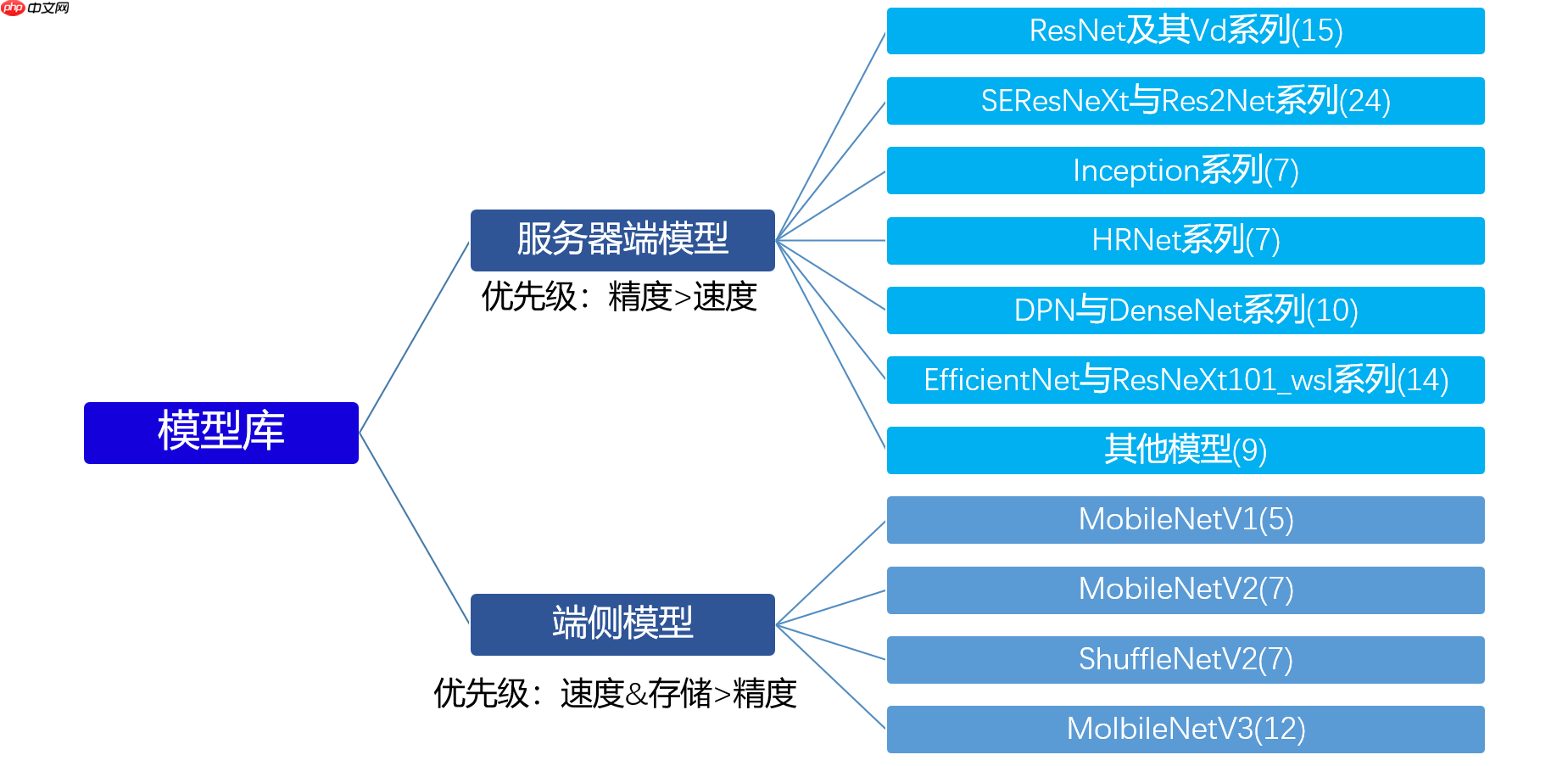
这里我们使用MobileNetV2模型,因为它在预测速度和性能上都具有很大的优势,而且符合我们此次竞赛实战的要求,用户可以根据预测耗时的要求选择不同的网络。此外,PaddleClas也开源了预训练模型,我们可以基于此在自己的数据集上进行微调,提升效果。
更多模型详细介绍和模型训练技巧,可查看PaddleClas模型库文档。
1.2 PaddleClas竞赛实战
- 先来看看树莓派长啥样:

- 寻找合适的模型
PaddleClas移动端系列模型 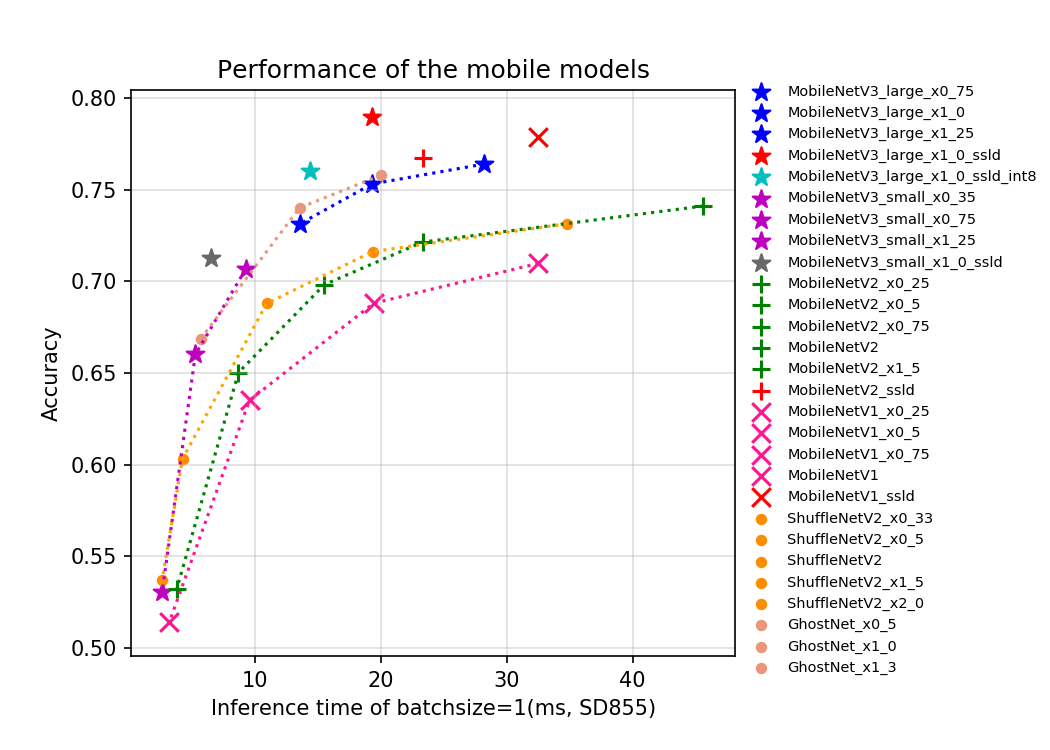
一、前置条件
- 安装Python3.5或更高版本版本。
- 安装PaddlePaddle 1.7或更高版本,具体安装方法请参见快速安装。由于图像分类模型计算开销大,推荐在GPU版本的PaddlePaddle下使用PaddleClas。
- 下载PaddleClas的代码库。
cd path_to_clone_PaddleClas 以下二者任选其一 git clone https://github.com/PaddlePaddle/PaddleClas.git git clone https://gitee.com/paddlepaddle/PaddleClas.git
- 安装Python依赖库。Python依赖库在requirements.txt中给出。(本地)
pip install --upgrade -r requirements.txt
- 设置PYTHONPATH环境变量(本地)
export PYTHONPATH=path_to_PaddleClas:$PYTHONPATH
!git clone https://gitee.com/paddlepaddle/PaddleClas.git
Cloning into 'PaddleClas'... remote: Enumerating objects: 7754, done. remote: Counting objects: 100% (7754/7754), done. remote: Compressing objects: 100% (4435/4435), done. remote: Total 7754 (delta 5296), reused 4873 (delta 3228), pack-reused 0 Receiving objects: 100% (7754/7754), 33.31 MiB | 5.40 MiB/s, done. Resolving deltas: 100% (5296/5296), done. Checking connectivity... done.
!pip install -r PaddleClas/requirements.txt
二、准备数据集
PaddleClas数据准备文档提供了ImageNet1k数据集以及flowers102数据集的准备过程。当然,如果大家希望使用自己的数据集,则需要至少准备以下两份文件。
- 训练集图像,以图像文件形式保存。
- 训练集标签文件,以文本形式保存,每一行的文件都包含文件名以及图像标签,以空格隔开。下面给出一个示例。
ILSVRC2012_val_00000001.JPEG 65...
如果需要在训练的时候进行验证,则也同时需要提供验证集图像以及验证集标签文件。
以训练集配置为例,配置文件中对应如下
TRAIN: # 训练配置
batch_size: 32 # 训练的batch size
num_workers: 4 # 每个trainer(1块GPU上可以视为1个trainer)的进程数量
file_list: "./dataset/flowers102/train_list.txt" # 训练集标签文件,每一行由"image_name label"组成
data_dir: "./dataset/flowers102/" # 训练集的图像数据路径
shuffle_seed: 0 # 数据打散的种子
transforms: # 训练图像的数据预处理
- DecodeImage: # 解码
to_rgb: True
to_np: False
channel_first: False
- RandCropImage: # 随机裁剪
size: 224
- RandFlipImage: # 随机水平翻转
flip_code: 1
- NormalizeImage: # 归一化
scale: 1./255.
mean: [0.485, 0.456, 0.406] std: [0.229, 0.224, 0.225] order: ''
- ToCHWImage: # 通道转换其中file_list即训练数据集的标签文件,data_dir是图像所在的文件夹。
解压数据集
!unzip data/data71799/lemon_lesson.zip
Archive: data/data71799/lemon_lesson.zip creating: lemon_lesson/ inflating: lemon_lesson/sample_submit.csv inflating: lemon_lesson/test_images.zip inflating: lemon_lesson/train_images.csv inflating: lemon_lesson/train_images.zip
!unzip lemon_lesson/train_images.zip -d lemon_lesson/
!unzip lemon_lesson/test_images.zip -d lemon_lesson/
自己切分数据集
import pandas as pdimport codecsimport osfrom PIL import Image
df = pd.read_csv('lemon_lesson/train_images.csv')
all_file_dir = 'lemon_lesson'train_file = codecs.open(os.path.join(all_file_dir, "train_list.txt"), 'w')
eval_file = codecs.open(os.path.join(all_file_dir, "eval_list.txt"), 'w')
image_path_list = df['id'].values
label_list = df['class_num'].values# 划分训练集和校验集all_size = len(image_path_list)
train_size = int(all_size * 0.8)
train_image_path_list = image_path_list[:train_size]
train_label_list = label_list[:train_size]
val_image_path_list = image_path_list[train_size:]
val_label_list = label_list[train_size:]
image_path_pre = 'lemon_lesson/train_images'for file,label_id in zip(train_image_path_list, train_label_list): # print(file)
# print(label_id)
try:
img = Image.open(os.path.join(image_path_pre, file))
# train_file.write("{0}\0{1}\n".format(os.path.join(image_path_pre, file), label_id))
train_file.write("{0}{1}{2}\n".format(os.path.join(image_path_pre, file),' ', label_id)) # eval_file.write("{0}\t{1}\n".format(os.path.join(image_path_pre, file), label_id))
except Exception as e: pass
# 存在一些文件打不开,此处需要稍作清洗
# print('error!')for file,label_id in zip(val_image_path_list, val_label_list): # print(file)
# print(label_id)
try:
img = Image.open(os.path.join(image_path_pre, file)) # train_file.write("{0}\t{1}\n".format(os.path.join(image_path_pre, file), label_id))
eval_file.write("{0}{1}{2}\n".format(os.path.join(image_path_pre, file),' ', label_id)) except Exception as e: # pass
# 存在一些文件打不开,此处需要稍作清洗
print('error!')
train_file.close()
eval_file.close()用PaddleX API一键切分数据集
数据标注、转换、划分 » 图像分类
- 先把每个分类的数据集都拎出来,归属到各自目录下
- 再用PaddleX自带的API,一键切分数据集
!cp -r lemon_lesson MyDataset
!pip install paddlex
import pandas as pdimport codecsimport osfrom PIL import Image
df = pd.read_csv('MyDataset/train_images.csv')
image_path_list = df['id'].values
label_list = df['class_num'].valuesdf.class_num.value_counts()
0 400 1 255 2 235 3 212 Name: class_num, dtype: int64
!mkdir MyDataset/0!mkdir MyDataset/1!mkdir MyDataset/2!mkdir MyDataset/3
class_0 = df[df.class_num==0] class_0_list = class_0['id'].values
import shutilfor i in class_0_list: try:
shutil.copy(os.path.join('MyDataset/train_images', i), os.path.join('MyDataset/0', i)) except Exception as e: passclass_1 = df[df.class_num==1] class_1_list = class_1['id'].values
import shutilfor i in class_1_list: try:
shutil.copy(os.path.join('MyDataset/train_images', i), os.path.join('MyDataset/1', i)) except Exception as e: passclass_2 = df[df.class_num==2]
class_2_list = class_2['id'].valuesimport shutilfor i in class_2_list: try:
shutil.copy(os.path.join('MyDataset/train_images', i), os.path.join('MyDataset/2', i)) except Exception as e: passclass_3 = df[df.class_num==3]
class_3_list = class_3['id'].valuesimport shutilfor i in class_3_list: try:
shutil.copy(os.path.join('MyDataset/train_images', i), os.path.join('MyDataset/3', i)) except Exception as e: pass!ls MyDataset/0 -l |grep "^-"|wc -l !ls MyDataset/1 -l |grep "^-"|wc -l !ls MyDataset/2 -l |grep "^-"|wc -l !ls MyDataset/3 -l |grep "^-"|wc -l
400 255 235 212
# 使用PaddleX数据切分API要删除多余目录和list文件,否则会出现异常!rm -r MyDataset/train_images !rm -r MyDataset/test_images !rm MyDataset/*.txt
!paddlex --split_dataset --format ImageNet --dataset_dir MyDataset --val_value 0.2 --test_value 0.1
Dataset Split Done. Train samples: 773 Eval samples: 220 Test samples: 109 Split files saved in MyDataset
知识点 迁移学习
什么是迁移学习?为什么要用迁移学习
迁移学习(Transfer learning) 顾名思义就是就是把已学训练好的模型参数迁移到新的模型来帮助新模型训练。考虑到大部分数据或任务是存在相关性的,所以通过迁移学习我们可以将已经学到的模型参数(也可理解为模型学到的知识)通过某种方式来分享给新模型从而加快并优化模型的学习效率不用像大多数网络那样从零学习(starting from scratch,tabula rasa)。
三、模型训练与评估
在自己的数据集上训练分类模型时,更推荐加载预训练进行微调。
预训练模型使用以下方式进行下载。
python tools/download.py -a MobileNetV3_small_x1_0 -p ./pretrained -d True
更多的预训练模型可以参考这里:https://paddleclas.readthedocs.io/zh_CN/latest/models/models_intro.html
PaddleClas 提供模型训练与评估脚本:tools/train.py和tools/eval.py
3.1 模型训练
准备好配置文件之后,可以使用下面的方式启动训练。
python tools/train.py \
-c configs/quick_start/MobileNetV3_large_x1_0_finetune.yaml \
-o pretrained_model="" \
-o use_gpu=True其中,-c用于指定配置文件的路径,-o用于指定需要修改或者添加的参数,其中-o pretrained_model=""表示不使用预训练模型,-o use_gpu=True表示使用GPU进行训练。如果希望使用CPU进行训练,则需要将use_gpu设置为False。
更详细的训练配置,也可以直接修改模型对应的配置文件。
运行上述命令,可以看到输出日志,示例如下:
- 如果在训练中使用了mixup或者cutmix的数据增广方式,那么日志中只会打印出loss(损失)、lr(学习率)以及该minibatch的训练时间。
train step:890 loss: 6.8473 lr: 0.100000 elapse: 0.157s

- 如果训练过程中没有使用mixup或者cutmix的数据增广,那么除了loss(损失)、lr(学习率)以及该minibatch的训练时间之外,日志中也会打印出top-1与top-k(默认为5)的信息。
epoch:0 train step:13 loss:7.9561 top1:0.0156 top5:0.1094 lr:0.100000 elapse:0.193s
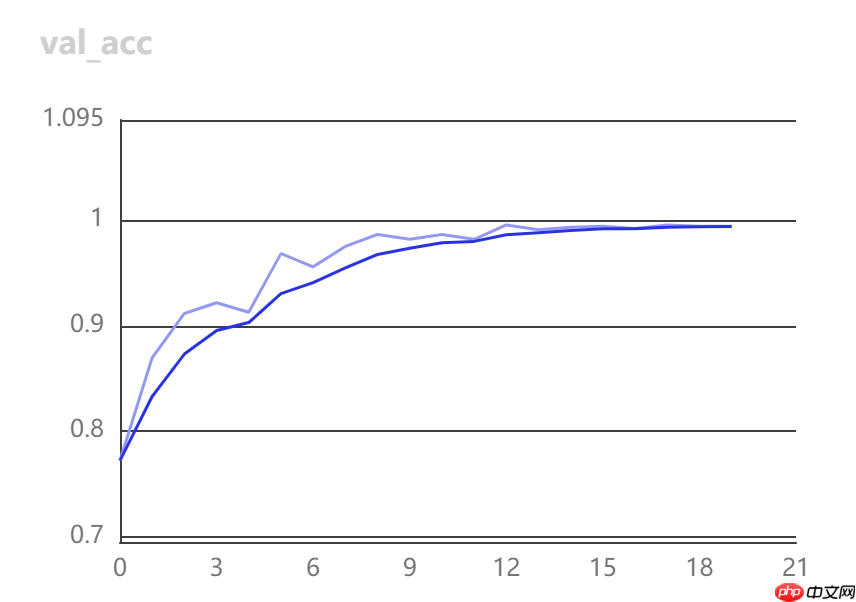
训练期间也可以通过VisualDL实时观察loss变化。
%cd PaddleClas/
/home/aistudio/PaddleClas
!ls -ll
total 168 drwxr-xr-x 27 aistudio aistudio 4096 Mar 6 19:51 configs drwxr-xr-x 3 aistudio aistudio 4096 Mar 6 19:51 dataset drwxr-xr-x 5 aistudio aistudio 4096 Mar 6 19:51 deploy drwxr-xr-x 5 aistudio aistudio 4096 Mar 6 19:51 docs -rw-r--r-- 1 aistudio aistudio 671 Mar 6 19:51 __init__.py -rw-r--r-- 1 aistudio aistudio 11357 Mar 6 19:51 LICENSE -rw-r--r-- 1 aistudio aistudio 144 Mar 6 19:51 MANIFEST.in -rw-r--r-- 1 aistudio aistudio 15236 Mar 6 19:51 paddleclas.py drwxr-xr-x 6 aistudio aistudio 4096 Mar 6 19:51 ppcls -rw-r--r-- 1 aistudio aistudio 48619 Mar 6 19:51 README_cn.md -rw-r--r-- 1 aistudio aistudio 49625 Mar 6 19:51 README.md -rw-r--r-- 1 aistudio aistudio 64 Mar 6 19:51 requirements.txt -rw-r--r-- 1 aistudio aistudio 2075 Mar 6 19:51 setup.py drwxr-xr-x 7 aistudio aistudio 4096 Mar 6 19:51 tools
!python tools/download.py -a MobileNetV3_large_x1_0 -p ./pretrained -d True
2021-03-06 20:13:09 INFO: Downloading MobileNetV3_large_x1_0_pretrained.pdparams from https://paddle-imagenet-models-name.bj.bcebos.com/dygraph/MobileNetV3_large_x1_0_pretrained.pdparams 100%|██████████████████████████████████| 32503/32503 [00:00<00:00, 41162.42KB/s] 2021-03-06 20:13:10 INFO: download ./pretrained/MobileNetV3_large_x1_0_pretrained.pdparams finished
在AI Studio上查看可视化效果:参考VisualDL文档
设置日志文件并记录标量数据:
from visualdl import LogWriter# 在`./log/scalar_test/train`路径下建立日志文件with LogWriter(logdir="./log/scalar_test/train") as writer: # 使用scalar组件记录一个标量数据 writer.add_scalar(tag="acc", step=1, value=0.5678) writer.add_scalar(tag="acc", step=2, value=0.6878) writer.add_scalar(tag="acc", step=3, value=0.9878)
因此,训练前可以改造一下tools/train.py的代码,加入VisualDL可视化,比如这里,把每轮验证集上的准确率结果记录下来:
# 在`./logdir`路径下建立日志文件
with LogWriter(logdir="./logdir") as writer: for epoch_id in range(last_epoch_id + 1, config.epochs):
net.train() # 1. train with train dataset
program.run(train_dataloader, config, net, optimizer, lr_scheduler,
epoch_id, 'train') # 2. validate with validate dataset
if config.validate and epoch_id % config.valid_interval == 0:
net.eval() with paddle.no_grad():
top1_acc = program.run(valid_dataloader, config, net, None, None, epoch_id, 'valid') if top1_acc > best_top1_acc:
best_top1_acc = top1_acc
best_top1_epoch = epoch_id if epoch_id % config.save_interval == 0:
model_path = os.path.join(config.model_save_dir,
config.ARCHITECTURE["name"])
save_model(net, optimizer, model_path, "best_model")
message = "The best top1 acc {:.5f}, in epoch: {:d}".format(
best_top1_acc, best_top1_epoch)
logger.info("{:s}".format(logger.coloring(message, "RED"))) # 使用scalar组件记录一个标量数据
writer.add_scalar(tag="val_acc", step=epoch_id, value=top1_acc)!cp ../train.py tools/train.py
# 开始训练!python tools/train.py -c ../MobileNetV3_large_x1_0_finetune.yaml
3.2 模型微调
30分钟玩转PaddleClas中包含大量模型微调的示例,可以参考该章节进行模型微调。
3.3 模型评估
可以更改configs/eval.yaml中的ARCHITECTURE.name字段和pretrained_model字段来配置评估模型,也可以通过-o参数更新配置。
注意: 加载预训练模型时,需要指定预训练模型的前缀,例如预训练模型参数所在的文件夹为output/ResNet50_vd/19,预训练模型参数的名称为output/ResNet50_vd/19/ppcls.pdparams,则pretrained_model参数需要指定为output/ResNet50_vd/19/ppcls,PaddleClas会自动补齐.pdparams的后缀。
!python tools/eval.py \
-c ../MobileNetV3_large_x1_0_finetune.yaml \
-o pretrained_model="./output/MobileNetV3_large_x1_0/best_model/ppcls"\
-o load_static_weights=False2021-03-06 20:40:07 WARNING: A new filed (load_static_weights) detected! 2021-03-06 20:40:07 INFO: =========================================================== == PaddleClas is powered by PaddlePaddle ! == =========================================================== == == == For more info please go to the following website. == == == == https://github.com/PaddlePaddle/PaddleClas == =========================================================== 2021-03-06 20:40:07 INFO: ARCHITECTURE : 2021-03-06 20:40:07 INFO: name : MobileNetV3_large_x1_0 2021-03-06 20:40:07 INFO: ------------------------------------------------------------ 2021-03-06 20:40:07 INFO: LEARNING_RATE : 2021-03-06 20:40:07 INFO: function : Cosine 2021-03-06 20:40:07 INFO: params : 2021-03-06 20:40:07 INFO: lr : 0.00375 2021-03-06 20:40:07 INFO: ------------------------------------------------------------ 2021-03-06 20:40:07 INFO: OPTIMIZER : 2021-03-06 20:40:07 INFO: function : Momentum 2021-03-06 20:40:07 INFO: params : 2021-03-06 20:40:07 INFO: momentum : 0.9 2021-03-06 20:40:07 INFO: regularizer : 2021-03-06 20:40:07 INFO: factor : 1e-06 2021-03-06 20:40:07 INFO: function : L2 2021-03-06 20:40:07 INFO: ------------------------------------------------------------ 2021-03-06 20:40:07 INFO: TRAIN : 2021-03-06 20:40:07 INFO: batch_size : 32 2021-03-06 20:40:07 INFO: data_dir : ../ 2021-03-06 20:40:07 INFO: file_list : ../lemon_lesson/train_list.txt 2021-03-06 20:40:07 INFO: num_workers : 0 2021-03-06 20:40:07 INFO: shuffle_seed : 2021 2021-03-06 20:40:07 INFO: transforms : 2021-03-06 20:40:07 INFO: DecodeImage : 2021-03-06 20:40:07 INFO: channel_first : False 2021-03-06 20:40:07 INFO: to_np : False 2021-03-06 20:40:07 INFO: to_rgb : True 2021-03-06 20:40:07 INFO: RandCropImage : 2021-03-06 20:40:07 INFO: size : 224 2021-03-06 20:40:07 INFO: RandFlipImage : 2021-03-06 20:40:07 INFO: flip_code : 1 2021-03-06 20:40:07 INFO: NormalizeImage : 2021-03-06 20:40:07 INFO: mean : [0.485, 0.456, 0.406] 2021-03-06 20:40:07 INFO: order : 2021-03-06 20:40:07 INFO: scale : 1./255. 2021-03-06 20:40:07 INFO: std : [0.229, 0.224, 0.225] 2021-03-06 20:40:07 INFO: ToCHWImage : None 2021-03-06 20:40:07 INFO: ------------------------------------------------------------ 2021-03-06 20:40:07 INFO: VALID : 2021-03-06 20:40:07 INFO: batch_size : 16 2021-03-06 20:40:07 INFO: data_dir : ../ 2021-03-06 20:40:07 INFO: file_list : ../lemon_lesson/train_list.txt 2021-03-06 20:40:07 INFO: num_workers : 0 2021-03-06 20:40:07 INFO: shuffle_seed : 2021 2021-03-06 20:40:07 INFO: transforms : 2021-03-06 20:40:07 INFO: DecodeImage : 2021-03-06 20:40:07 INFO: channel_first : False 2021-03-06 20:40:07 INFO: to_np : False 2021-03-06 20:40:07 INFO: to_rgb : True 2021-03-06 20:40:07 INFO: ResizeImage : 2021-03-06 20:40:07 INFO: resize_short : 256 2021-03-06 20:40:07 INFO: CropImage : 2021-03-06 20:40:07 INFO: size : 224 2021-03-06 20:40:07 INFO: NormalizeImage : 2021-03-06 20:40:07 INFO: mean : [0.485, 0.456, 0.406] 2021-03-06 20:40:07 INFO: order : 2021-03-06 20:40:07 INFO: scale : 1.0/255.0 2021-03-06 20:40:07 INFO: std : [0.229, 0.224, 0.225] 2021-03-06 20:40:07 INFO: ToCHWImage : None 2021-03-06 20:40:07 INFO: ------------------------------------------------------------ 2021-03-06 20:40:07 INFO: classes_num : 4 2021-03-06 20:40:07 INFO: epochs : 20 2021-03-06 20:40:07 INFO: image_shape : [3, 224, 224] 2021-03-06 20:40:07 INFO: load_static_weights : False 2021-03-06 20:40:07 INFO: mode : train 2021-03-06 20:40:07 INFO: model_save_dir : ./output/ 2021-03-06 20:40:07 INFO: pretrained_model : ./output/MobileNetV3_large_x1_0/best_model/ppcls 2021-03-06 20:40:07 INFO: save_interval : 1 2021-03-06 20:40:07 INFO: topk : 1 2021-03-06 20:40:07 INFO: total_images : 881 2021-03-06 20:40:07 INFO: valid_interval : 1 2021-03-06 20:40:07 INFO: validate : True W0306 20:40:07.714506 6263 device_context.cc:362] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1 W0306 20:40:07.720638 6263 device_context.cc:372] device: 0, cuDNN Version: 7.6. 2021-03-06 20:40:13 INFO: Finish initing model from ./output/MobileNetV3_large_x1_0/best_model/ppcls 2021-03-06 20:40:13 INFO: epoch:0 , valid step:0 , top1: 1.00000, loss: 0.02483, lr: 0.000000, batch_cost: 0.34671 s, reader_cost: 0.31402 s, ips: 46.14865 images/sec. 2021-03-06 20:40:14 INFO: epoch:0 , valid step:10 , top1: 1.00000, loss: 0.00227, lr: 0.000000, batch_cost: 0.13076 s, reader_cost: 0.10751 s, ips: 122.36519 images/sec. 2021-03-06 20:40:16 INFO: epoch:0 , valid step:20 , top1: 0.93750, loss: 0.09456, lr: 0.000000, batch_cost: 0.13080 s, reader_cost: 0.10737 s, ips: 122.32439 images/sec. 2021-03-06 20:40:17 INFO: epoch:0 , valid step:30 , top1: 1.00000, loss: 0.01403, lr: 0.000000, batch_cost: 0.13100 s, reader_cost: 0.10741 s, ips: 122.13658 images/sec. 2021-03-06 20:40:18 INFO: epoch:0 , valid step:40 , top1: 1.00000, loss: 0.03857, lr: 0.000000, batch_cost: 0.13145 s, reader_cost: 0.10739 s, ips: 121.72137 images/sec. 2021-03-06 20:40:20 INFO: epoch:0 , valid step:50 , top1: 1.00000, loss: 0.00866, lr: 0.000000, batch_cost: 0.13441 s, reader_cost: 0.10830 s, ips: 119.04292 images/sec. 2021-03-06 20:40:20 INFO: END epoch:0 valid top1: 0.99319, loss: 0.02812, batch_cost: 0.13135 s, reader_cost: 0.10557 s, batch_cost_sum: 6.04213 s, ips: 7.61321 images/sec.
四、图像增广
ImageNet1k数据集包含128W张图片,即使不加其他策略训练,一般也能获得很高的精度,而在大部分实际场景中,都无法获得这么多的数据,这也会导致训练结果很差,通过一些数据增广的方式去扩充训练样本,可以增加训练样本的丰富度,提升模型的泛化性能。PaddleClas开源了8种数据增广方案。包括图像变换类、图像裁剪类以及图像混叠类。经过实验验证,ResNet50模型在ImageNet数据集上, 与标准变换相比,采用数据增广,识别准确率最高可以提升1%。

下面这个流程图是图片预处理并被送进网络训练的一个过程,需要经过解码、随机裁剪、水平翻转、归一化、通道转换以及组batch,最终训练的过程。

- 图像变换类:图像变换类是在随机裁剪与翻转之间进行的操作,也可以认为是在原图上做的操作。主要方式包括AutoAugment和RandAugment,基于一定的策略,包括锐化、亮度变化、直方图均衡化等,对图像进行处理。这样网络在训练时就已经见过这些情况了,之后在实际预测时,即使遇到了光照变换、旋转这些很棘手的情况,网络也可以从容应对了。
- 图像裁剪类:图像裁剪类主要是在生成的在通道转换之后,在图像上设置掩码,随机遮挡,从而使得网络去学习一些非显著性的特征。否则网络一直学习很重要的显著性区域,之后在预测有遮挡的图片时,泛化能力会很差。主要方式包括:CutOut、RandErasing、HideAndSeek、GridMask。这里需要注意的是,在通道转换前后去做图像裁剪,其实是没有区别的。因为通道转换这个操作不会修改图像的像素值。
- 图像混叠类:组完batch之后,图像与图像、标签与标签之间进行混合,形成新的batch数据,然后送进网络进行训练。这也就是图像混叠类数据增广方式,主要的有Mixup与Cutmix两种方式。
4.1 数据增广的尝试-RandomErasing
- 训练数据量较小时,使用数据增广可以进一步提升模型精度,基于3.3节中的训练方法,结合RandomErasing的数据增广方式进行训练,配置文件中的训练集配置如下所示。
但是!在这个比赛可能是副作用!读者可以思考下原因。
TRAIN:
batch_size: 32
num_workers: 0
file_list: "../lemon_lesson/train_list.txt"
data_dir: "../"
shuffle_seed: 2021
transforms:
- DecodeImage:
to_rgb: True
to_np: False
channel_first: False
- RandCropImage:
size: 224
- RandFlipImage:
flip_code: -1
- RandomErasing: # 使用RandomErasing方法进行数据增广
EPSILON: 0.5
- NormalizeImage:
scale: 1./255.
mean: [0.485, 0.456, 0.406] std: [0.229, 0.224, 0.225] order: ''
- ToCHWImage:!cp ../random_erasing.py ppcls/data/imaug/random_erasing.py
!python tools/train.py -c ../MobileNetV3_large_x1_0_finetune.yaml
4.2 离线数据增广
这是一个离线数据增广的脚本,可以帮助我们利用PaddleClas的自动数据增强功能,快速进行离线数据扩充
!cp ../img_aug.py ./
!mkdir ../img_aug
!python img_aug.py
再次提醒!滥用数据增强可能是作用!起码这柠檬估计没人敢吃……

参考资料:
- 深度学习中几种常用增强数据的库
- imgaug
- Albumentations
五、模型推理
首先,对训练好的模型进行转换:
python tools/export_model.py \ --model=模型名字 \ --pretrained_model=预训练模型路径 \ --output_path=预测模型保存路径
之后,通过推理引擎进行推理:
python tools/infer/predict.py \
-m model文件路径 \ -p params文件路径 \ -i 图片路径 \ --use_gpu=1 \ --use_tensorrt=True更多的参数说明可以参考https://github.com/PaddlePaddle/PaddleClas/blob/master/tools/infer/predict.py中的parse_args函数。
更多关于服务器端与端侧的预测部署方案请参考:https://www.paddlepaddle.org.cn/documentation/docs/zh/advanced_guide/inference_deployment/index_cn.html
# 注意要写入类别数!python tools/export_model.py \
--model=MobileNetV3_large_x1_0 \
--pretrained_model=output/MobileNetV3_large_x1_0/best_model/ppcls \
--output_path=inference \
--class_dim 4W0306 23:31:42.187705 20495 device_context.cc:362] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1 W0306 23:31:42.193265 20495 device_context.cc:372] device: 0, cuDNN Version: 7.6. /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:77: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working return (isinstance(seq, collections.Sequence) and
!ls ../lemon_lesson/test_images -l |grep "^-"|wc -l
1651
# 可以预测整个目录!python tools/infer/predict.py \
--model_file inference/inference.pdmodel \
--params_file inference/inference.pdiparams \
--image_file ../lemon_lesson/test_images \
--use_gpu=True六、输出预测结果
做一些小幅改造,让预测结果以sample_submit.csv的格式保存,便于提交。
!cp ../predict.py tools/infer/submit.py
# 可以预测整个目录!python tools/infer/submit.py \
--model_file inference/inference.pdmodel \
--params_file inference/inference.pdiparams \
--image_file ../lemon_lesson/test_images \
--use_gpu=True总结
-
本教程希望能够让大家对PaddleClas有一个直观的认识,并带领大家进行图像分类竞赛实战。更多丰富的内容与示例可以参考PaddleClas的github与教程文档。
- PaddleClas github地址:https://github.com/PaddlePaddle/PaddleClas/
- PaddleClas教程文档地址:https://paddleclas.readthedocs.io/zh_CN/latest/index.html
如果大家在使用PaddleClas的过程中遇到问题,欢迎去PaddleClas的github上提issue:https://github.com/PaddlePaddle/PaddleClas/issues/new
番外篇:PaddleX做图像分类
在PaddleClas之上,飞桨还提供了全流程开发工具PaddleX,以低代码的形式支持图像分类、目标检测、语义分割、实例分割任务开发,PaddleX的更偏向实际产业应用场景,在深度学习竞赛中,更适合做一个基线参考。也就是说,如果我们开发的模型跑不过PaddleX,那问题可大了……
- PaddleX图像分类教程
模型训练
直接运行下面代码即可,代码会自动下载训练数据
%cd ~
/home/aistudio
# 环境变量配置,用于控制是否使用GPU# 说明文档:https://paddlex.readthedocs.io/zh_CN/develop/appendix/parameters.html#gpuimport os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'from paddlex.cls import transformsimport paddlex as pdx# 定义训练和验证时的transforms# API说明https://paddlex.readthedocs.io/zh_CN/develop/apis/transforms/cls_transforms.htmltrain_transforms = transforms.Compose([
transforms.RandomCrop(crop_size=224), transforms.RandomHorizontalFlip(),
transforms.Normalize()
])
eval_transforms = transforms.Compose([
transforms.ResizeByShort(short_size=256),
transforms.CenterCrop(crop_size=224), transforms.Normalize()
])# 定义训练和验证所用的数据集# API说明:https://paddlex.readthedocs.io/zh_CN/develop/apis/datasets.html#paddlex-datasets-imagenet# 主要就是把数据集目录配置进去train_dataset = pdx.datasets.ImageNet(
data_dir='MyDataset',
file_list='MyDataset/train_list.txt',
label_list='MyDataset/labels.txt',
transforms=train_transforms,
shuffle=True)
eval_dataset = pdx.datasets.ImageNet(
data_dir='MyDataset',
file_list='MyDataset/val_list.txt',
label_list='MyDataset/labels.txt',
transforms=eval_transforms)# 初始化模型,并进行训练# 可使用VisualDL查看训练指标,参考https://paddlex.readthedocs.io/zh_CN/develop/train/visualdl.htmlmodel = pdx.cls.MobileNetV3_small_ssld(num_classes=len(train_dataset.labels))# API说明:https://paddlex.readthedocs.io/zh_CN/develop/apis/models/classification.html#train# 各参数介绍与调整说明:https://paddlex.readthedocs.io/zh_CN/develop/appendix/parameters.htmlmodel.train(
num_epochs=10,
train_dataset=train_dataset,
train_batch_size=32,
eval_dataset=eval_dataset,
lr_decay_epochs=[4, 6, 8],
learning_rate=0.025,
save_dir='output/MobileNetV3_small_ssld',
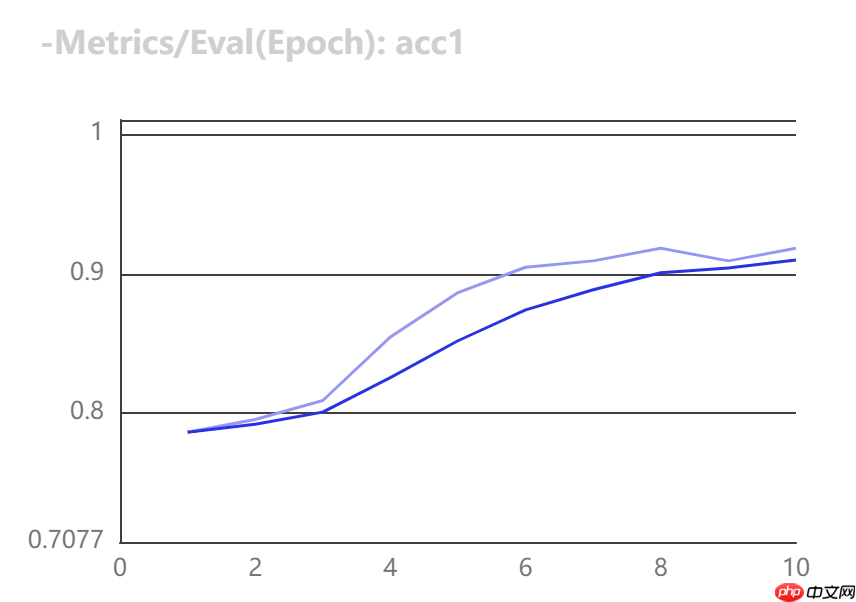
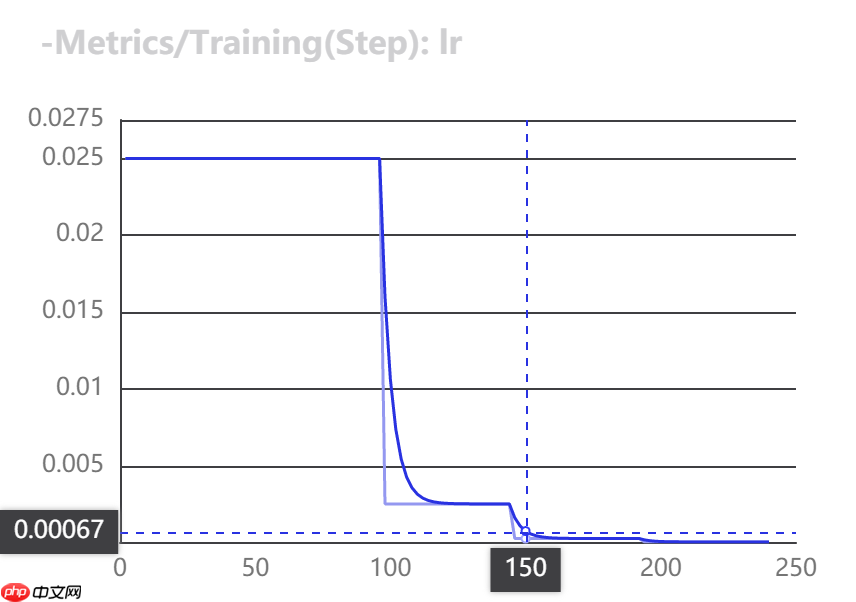
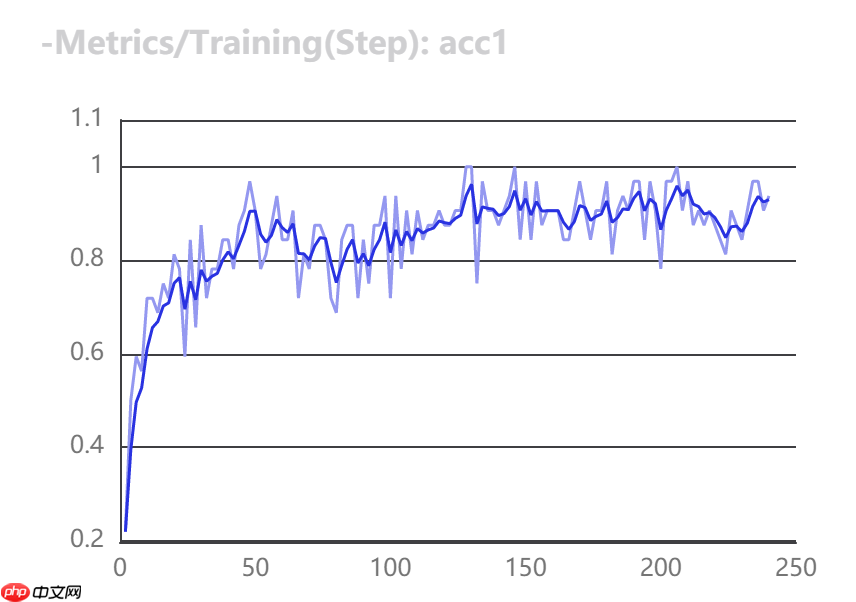
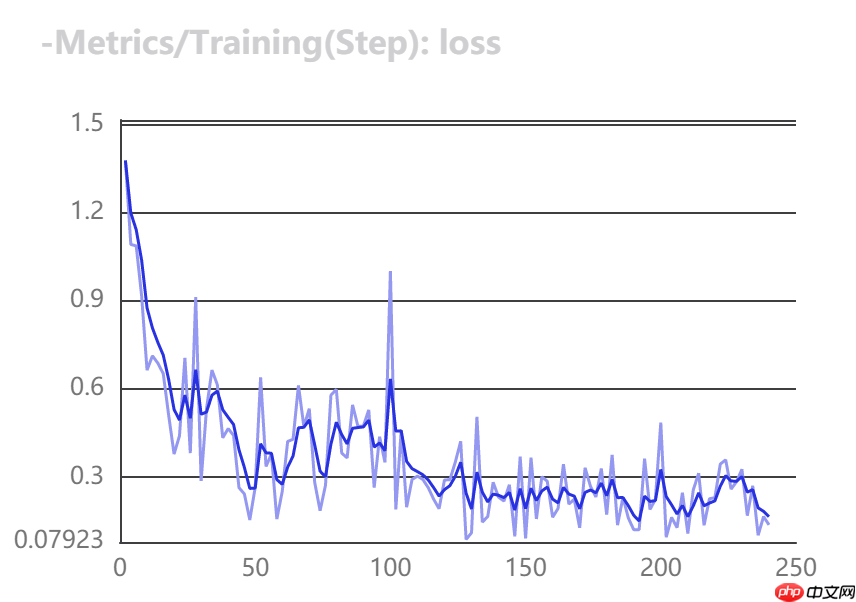
use_vdl=True)VisualDL可视化训练指标
在模型训练过程,在train函数中,将use_vdl设为True,则训练过程会自动将训练日志以VisualDL的格式打点在save_dir(用户自己指定的路径)下的vdl_log目录