






本文介绍单阶段检测模型YOLOF,其仅用一层特征层便达到多层特征层检测效果,速度领先。作者将检测分encoder和decoder,提出单进单出的Dilated Encoder及Uniform Matching组件,解决相关问题。对比其他模型,YOLOF精度相当或更高,速度更快、耗时更少。还介绍了其复现过程、结果、代码及使用方法。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

论文介绍
论文地址:https://arxiv.org/abs/2103.09460
YOLOF是一个单阶段检测模型,它成功地只使用了一层特征层,就达到了使用多层特征层(FPN)进行检测一样的效果,并在速度上遥遥领先于多特征层检测器。
与其他模型对比:
- 与对齐后的RetinaNet达到了相同的AP,但是推理速度快了2.5x。
- 在不利用transformer,只使用C5特征层的情况下,达到了DETR的精度,但是训练耗时少了7x。
- 对比YOLOv4,对齐后的YOLOF精度更高,速度更快。
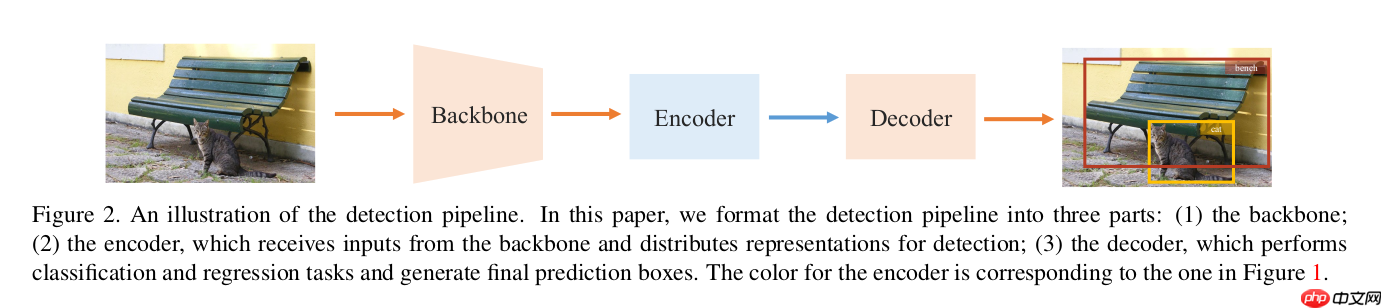
首先作者将检测的过程分为encoder和decoder:
- Encoder:将backbone的特征层映射到用于检测的特征层。
- Decoder:将encoder输出的特征层解码成检测结果。
如下图所示:
然后作者尝试了多种encoder结构,包括多进多出,单进多出,多进单出,单进单出,发现单进多出能达到多进多出(FPN)差不多的精度,如下图:
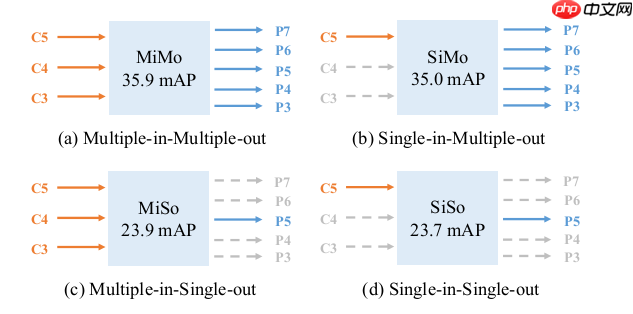
所以得出结论:FPN的效果得益于分而治之而并非多层特征融合。基于这样的观察,作者提出YOLOF,成功地在单特征层上进行高效地目标检测。
YOLOF有两个重要的组件,Dilated Encoder和Uniform Matching:
Dilated Encoder
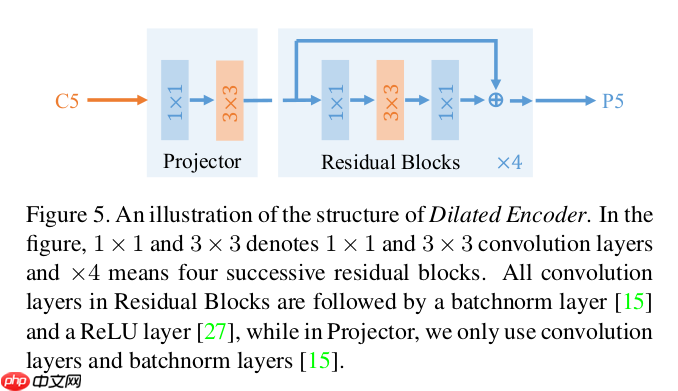
Dilated Encoder其实是一个单进单出的neck,它的结构如上图所示,它由Projector和Residual Blocks两部分组成。首先C5特征层经过1x1的卷积将通道从2048降到512,然后通过一个3x3的卷积对语义信息进行refine,这是Projector部分。然后是一组residual blocks,每个block中的卷积层均采用了空洞卷积,并加入了残差模块,这是Residual Blocks部分。作者使用了4个residual blocks,空洞大小分别为2,4,6,8。最后输出的检测特征层具有和C5一样的stride(32)。
据作者描述,空洞卷积的作用是高效地增大感受野,残差模块是将不同感受野的特征融合到一个特征层上。
Uniform Matching
由于只用了一层特征层,anchor的分布变得非常稀疏,导致大物体更容易被匹配到,为了解决这种不平衡,作者提出了Uniform Matching,每个GT选取k个最接近的anchor进行匹配,从而保证了每个GT都有足够多的样本进行学习。
最后YOLOF具有如下结构:
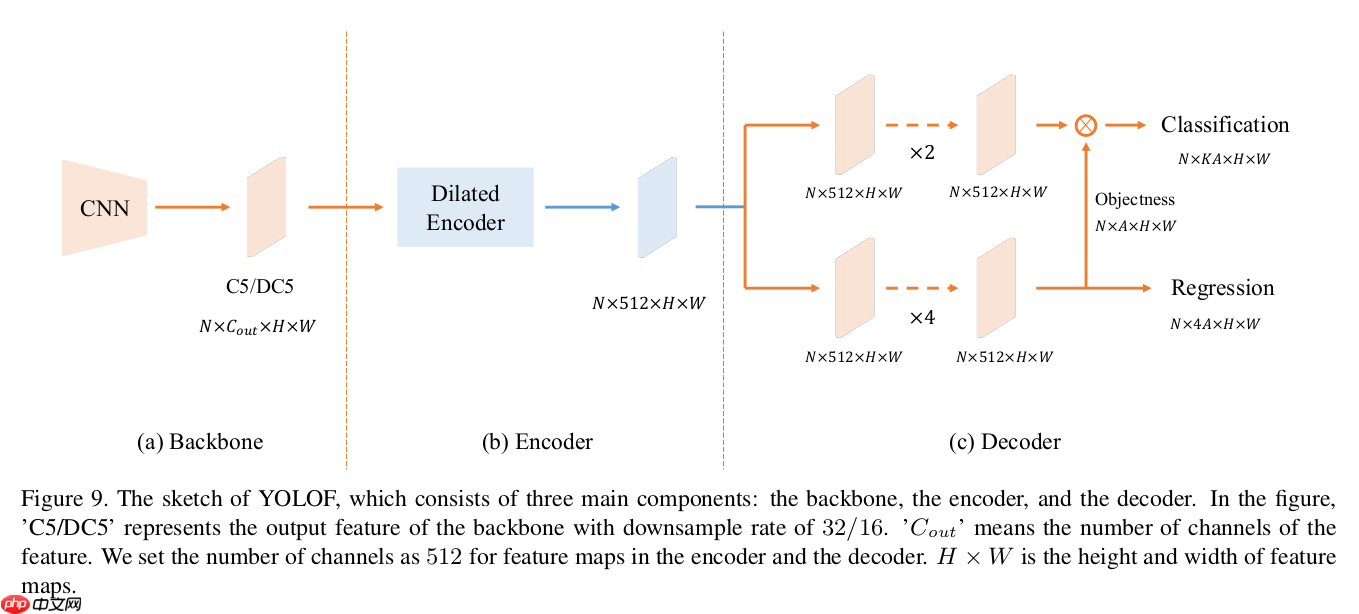
在最后的检测模块,YOLOF使用用2个卷积层作为分类分支,4个卷积层作为回归分支,在回归分支上还加入了隐性objectness,最后并入分类结果合并作为最后的分类分数。隐性的意思是没有监督信息去监督objectness的学习。
实验结果
下图是和RetinaNet对比的结果,RetinaNet+是补上了GN,implicit objectness,GIoU这些trick后的RetinaNet。
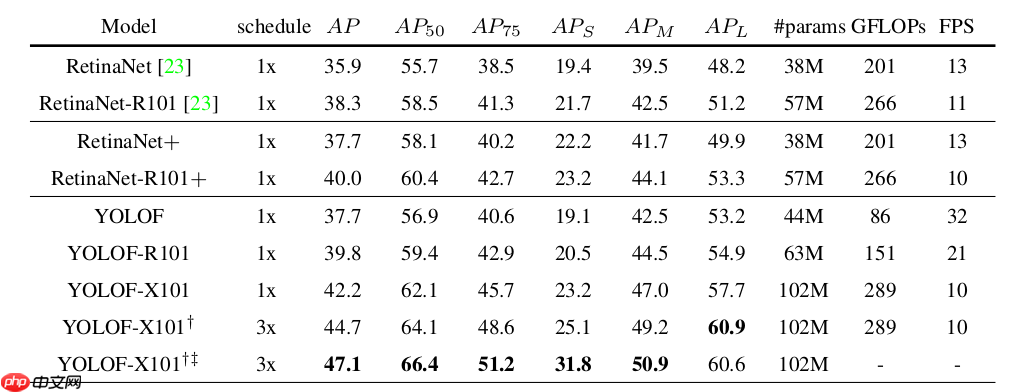
总结
该论文写地很细,读者关心的细节都解释地很清楚,实验也做的很完整,强烈建议大家一读。
复现过程
官方给出了两个实现版本,一个是基于Detectron2的,一个是基于cvpods的,可以在这里可以找到。其中Detectron2不用过多介绍了,cvpods本人不太熟,貌似是旷世的一个计算机视觉框架。同时MMDetection也对YOLOF进行了实现,并纳入到了他们的检测模型库中。这里我的实现版本主要参照的是MMDetection的实现版本和官方基于Detectron2的版本。

我选择基于PaddleDetection进行复现,因为里面集成了很多检测相关组件,可以节省很多时间。而且PaddleDetection官方并没有支持YOLOF,所以是一个很好的炼手机会。其实YOLOF也可以被认为是RetinaNet的一个变种,所以之前复现RetinaNet的经验帮了很大的忙。为了和PaddleDetection风格保持一致,YOLOF的接口设计借鉴了PaddleDetection关于GFL的实现,因为大家都是RetinaNet的变种。要注意的是YOLOF使用的是caffe形式的ResNet,在PaddleDetection下需要把ResNet的variant设置成a。但是PaddleDetection官方并没有提供这个版本的ImageNet预训练权重,所以需要手动转换。我已经将转换好的权重上传到了百度网盘,感兴趣的同学可以前往下载[rpsb]。
当代码敲完,首先在VOC数据上进行训练,调试,直到在VOC上的实现和MMDetection的版本有着差不多的AP之后,再在COCO上进行实验。
复现结果
| source | backbone | AP | epochs | config | model | train-log | dataset |
|---|---|---|---|---|---|---|---|
| official | R-50-C5 | 37.7 | 12.3(detail) | config | model[qr6o] | NA | coco2017 |
| mmdet | R-50-C5 | 37.5 | 12 | config | model | log | coco2017 |
| this | R-50-C5 | 37.5 | 12 | config | model[3z7q] | log | coco2017 |
| this_re-train | R-50-C5 | 37.4 | 12 | config | model[6faq] | log | coco2017 |
以上是官方的结果和我复现的结果对比,数据集大家采用的都是coco2017,其中模型的训练是在百度的aistudio上完成,使用4张V100显卡,每张显卡上放了8张图片,这个和官方保持一直。这里要特别感谢飞浆团队提供的优质算力。
这里是我复现的代码地址:Paddle-YOLOF,欢迎大家star,上面除了有复现的代码,还有训练好的模型,config和训练过程产生的log。如果有什么疑问可以在issue里提出,我会尽量解答。
使用方法
安装要求:
- python 3.7+
- Paddle v2.2: 访问这里了解如何安装
去github拉取复现的代码:
git clone https://github.com/thisisi3/Paddle-YOLOF.git pip install -e Paddle-YOLOF/PaddleDetection -v
访问这个链接了解如何安装PaddleDetection,按照这个链接了解如何使用PaddleDetection.
数据准备:
cd Paddle-YOLOF wget http://images.cocodataset.org/annotations/annotations_trainval2017.zip wget http://images.cocodataset.org/zips/train2017.zip wget http://images.cocodataset.org/zips/val2017.zip mkdir dataset mkdir dataset/coco unzip annotations_trainval2017.zip -d dataset/coco unzip train2017.zip -d dataset/coco unzip val2017.zip -d dataset/coco
如果官方的下载比较缓慢,可以访问aistudio下载coco2017数据。
下载backbone的预训练权重:
前往这边[rpsb]下载。然后放在pretrain/目录下。
单卡训练YOLOF:
python PaddleDetection/tools/train.py -c configs/yolof_r50_c5_1x_coco_8x4GPU.yml --eval
4卡训练YOLOF:
python -m paddle.distributed.launch --gpus 0,1,2,3 PaddleDetection/tools/train.py -c configs/yolof_r50_c5_1x_coco_8x4GPU.yml --eval
如果不想在训练的时候计算AP,可以去掉--eval这个选项。
计算AP:
python PaddleDetection/tools/eval.py -c configs/yolof_r50_c5_1x_coco_8x4GPU.yml -o weights=path_to_model_final.pdparams




























