






本文介绍一种基于PaddleSlim的GPNAS集成模型预测rank的方法。采用顺序和one-hot编码保留先验信息,用inverse-sigmoid转换rank标签分布。模型由多个子回归器经GPNAS集成,针对每个任务选子回归器参数和种类,用贝叶斯优化选GPNAS参数,还优化了GPNAS核函数和初始化方法,给出了实现流程、代码及结果。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

整体介绍
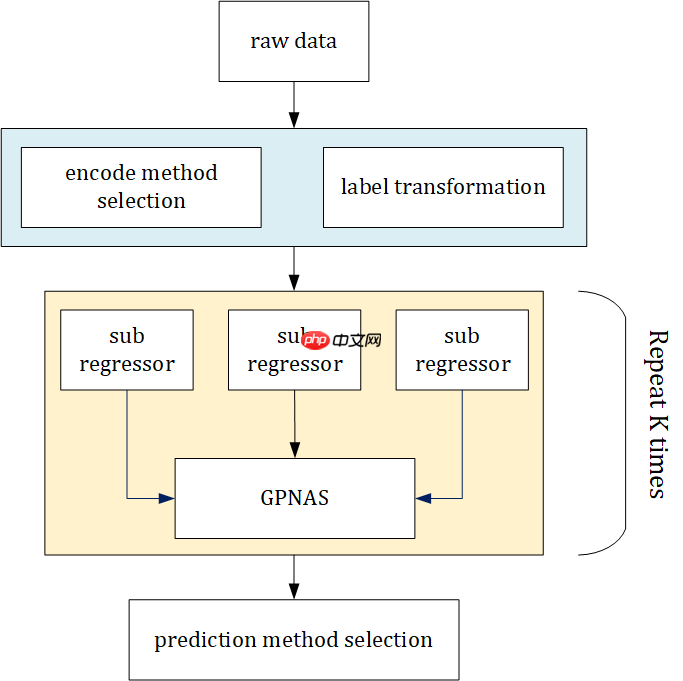
参考官方baseline和NAS的方式,使用以PaddleSlim的GPNAS为基础的集成模型进行rank的预测。
数据编码:通常而言网络模型的性能和深度有较强的相关性,这一先验在大多数的任务中得到了验证,但对某些任务而言则更看重其余的参数变化。因而数据编码部分我们使用了顺序编码和one-hot编码两种表达方式,来保留上述先验信息,尽可能降低问题的复杂度。rank标签通过inverse-sigmoid进行数据分布转换,尝试了(1)直接回归rank值和(2)回归score,进行排序得到rank两种方式。
模型选择:模型整体结构为多个子回归器通过GPNAS进行集成。对于每一个任务,我们验证了各个子回归器的性能,以选择所进行GPNAS集成的子回归器参数和种类。同时,对于每个任务,利用贝叶斯优化来选择每个任务对应的GPNAS参数。 对于GPNAS本身,我们同样对核函数的设计和初始化方法进行了优化和尝试。
大致流程如下
环境依赖安装
!pip install scikit-learn==1.0.2 -i https://mirror.baidu.com/pypi/simple/ !pip install lightgbm==3.3.2 -i https://mirror.baidu.com/pypi/simple/ !pip install xgboost==1.6.2 -i https://mirror.baidu.com/pypi/simple/ !pip install catboost==1.1 -i https://mirror.baidu.com/pypi/simple/ !!pip install bayesian-optimization==1.3.1 -i https://mirror.baidu.com/pypi/simple/
Looking in indexes: https://mirror.baidu.com/pypi/simple/ Requirement already satisfied: scikit-learn==1.0.2 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (1.0.2) Requirement already satisfied: scipy>=1.1.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-learn==1.0.2) (1.3.0) Requirement already satisfied: threadpoolctl>=2.0.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-learn==1.0.2) (3.1.0) Requirement already satisfied: numpy>=1.14.6 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-learn==1.0.2) (1.19.5) Requirement already satisfied: joblib>=0.11 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-learn==1.0.2) (0.14.1)[notice] A new release of pip available: 22.1.2 -> 22.3.1[notice] To update, run: pip install --upgrade pipLooking in indexes: https://mirror.baidu.com/pypi/simple/ Requirement already satisfied: lightgbm==3.3.2 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (3.3.2) Requirement already satisfied: wheel in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from lightgbm==3.3.2) (0.33.6) Requirement already satisfied: scipy in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from lightgbm==3.3.2) (1.3.0) Requirement already satisfied: numpy in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from lightgbm==3.3.2) (1.19.5) Requirement already satisfied: scikit-learn!=0.22.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from lightgbm==3.3.2) (1.0.2) Requirement already satisfied: joblib>=0.11 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-learn!=0.22.0->lightgbm==3.3.2) (0.14.1) Requirement already satisfied: threadpoolctl>=2.0.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-learn!=0.22.0->lightgbm==3.3.2) (3.1.0)[notice] A new release of pip available: 22.1.2 -> 22.3.1[notice] To update, run: pip install --upgrade pipLooking in indexes: https://mirror.baidu.com/pypi/simple/ Requirement already satisfied: xgboost==1.6.2 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (1.6.2) Requirement already satisfied: scipy in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from xgboost==1.6.2) (1.3.0) Requirement already satisfied: numpy in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from xgboost==1.6.2) (1.19.5)[notice] A new release of pip available: 22.1.2 -> 22.3.1[notice] To update, run: pip install --upgrade pipLooking in indexes: https://mirror.baidu.com/pypi/simple/ Requirement already satisfied: catboost==1.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (1.1) Requirement already satisfied: plotly in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from catboost==1.1) (5.8.0) Requirement already satisfied: pandas>=0.24.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from catboost==1.1) (1.1.5) Requirement already satisfied: scipy in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from catboost==1.1) (1.3.0) Requirement already satisfied: six in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from catboost==1.1) (1.16.0) Requirement already satisfied: matplotlib in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from catboost==1.1) (2.2.3) Requirement already satisfied: numpy>=1.16.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from catboost==1.1) (1.19.5) Requirement already satisfied: graphviz in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from catboost==1.1) (0.13) Requirement already satisfied: python-dateutil>=2.7.3 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pandas>=0.24.0->catboost==1.1) (2.8.2) Requirement already satisfied: pytz>=2017.2 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pandas>=0.24.0->catboost==1.1) (2019.3) Requirement already satisfied: cycler>=0.10 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from matplotlib->catboost==1.1) (0.10.0) Requirement already satisfied: pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from matplotlib->catboost==1.1) (3.0.9) Requirement already satisfied: kiwisolver>=1.0.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from matplotlib->catboost==1.1) (1.1.0) Requirement already satisfied: tenacity>=6.2.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from plotly->catboost==1.1) (8.0.1) Requirement already satisfied: setuptools in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from kiwisolver>=1.0.1->matplotlib->catboost==1.1) (41.4.0)[notice] A new release of pip available: 22.1.2 -> 22.3.1[notice] To update, run: pip install --upgrade pip
['Looking in indexes: https://mirror.baidu.com/pypi/simple/', 'Requirement already satisfied: bayesian-optimization==1.3.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (1.3.1)', 'Requirement already satisfied: scipy>=1.0.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from bayesian-optimization==1.3.1) (1.3.0)', 'Requirement already satisfied: numpy>=1.9.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from bayesian-optimization==1.3.1) (1.19.5)', 'Requirement already satisfied: scikit-learn>=0.18.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from bayesian-optimization==1.3.1) (1.0.2)', 'Requirement already satisfied: threadpoolctl>=2.0.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-learn>=0.18.0->bayesian-optimization==1.3.1) (3.1.0)', 'Requirement already satisfied: joblib>=0.11 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-learn>=0.18.0->bayesian-optimization==1.3.1) (0.14.1)', '', '[notice] A new release of pip available: 22.1.2 -> 22.3.1', '[notice] To update, run: pip install --upgrade pip']
引入必要依赖
import catboostimport lightgbmimport xgboostimport sklearnfrom sklearn import ensemblefrom sklearn.experimental import enable_hist_gradient_boostingfrom sklearn.ensemble import *from sklearn.kernel_ridge import *from sklearn.linear_model import *from sklearn.semi_supervised import *from sklearn.svm import *from sklearn.metrics import mean_squared_error, make_scorerimport numpy as npimport scipyimport copyimport jsonfrom sklearn.model_selection import cross_val_scorefrom scipy.linalg import hankel
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/sklearn/experimental/enable_hist_gradient_boosting.py:17: UserWarning: Since version 1.0, it is not needed to import enable_hist_gradient_boosting anymore. HistGradientBoostingClassifier and HistGradientBoostingRegressor are now stable and can be normally imported from sklearn.ensemble. "Since version 1.0, "
实现过程
以PaddleSlim的GPNAS为基础进行修改作为核心模块
GPNAS源码链接:https://github.com/PaddlePaddle/PaddleSlim/blob/develop/paddleslim/nas/gp_nas.py
修改参考代码:https://aistudio.baidu.com/aistudio/projectdetail/3751972?channelType=0&channel=0
新增如下核函数
Kernel=∣⟨M1,M2⟩∣
Kernel=α×2e16−⟨M,M⟩+β×e12−⟨M,M⟩
初始化方式
self.w = inv(X.T*X)X.T*Y as initial mean
self.cov_w = self.hp_cov * np.linalg.inv(X.T * X)
class GPNAS2(object):
_estimator_type = "regressor"
def __init__(self, cov_w=None, w=None, c_flag=2, m_flag=2, hp_mat=0.0000001, hp_cov=0.01, icov=1):
self.hp_mat = hp_mat
self.hp_cov = hp_cov
self.cov_w = cov_w
self.w = w
self.c_flag = c_flag
self.m_flag = m_flag
self.icov = icov def get_params(self, deep=True):
return { "hp_mat": self.hp_mat, "hp_cov": self.hp_cov, "cov_w": self.cov_w, "w": self.w, "c_flag": self.c_flag, "m_flag": self.m_flag, "icov": self.icov,
} def set_params(self, **parameters):
for parameter, value in parameters.items(): setattr(self, parameter, value) return self def _get_corelation(self, mat1, mat2):
"""
give two typical kernel function
Auto kernel hyperparameters estimation to be updated
"""
mat_diff = abs(mat1 - mat2) if self.c_flag == 1: return 0.5 * np.exp(-np.dot(mat_diff, mat_diff) / 16) elif self.c_flag == 2: return 1 * np.exp(-np.sqrt(np.dot(mat_diff, mat_diff)) / 12) elif self.c_flag == 3: return np.abs(np.dot(mat1, mat2)) elif self.c_flag == 4: return 0.7 * 1 * np.exp(-np.sqrt(np.dot(mat_diff, mat_diff)) / 12) + \ 0.3 * 0.5 * np.exp(-np.dot(mat_diff, mat_diff) / 16) def _preprocess_X(self, X):
"""
preprocess of input feature/ tokens of architecture
more complicated preprocess can be added such as nonlineaer transformation
"""
X = X.tolist()
p_X = copy.deepcopy(X) for feature in p_X: feature.append(1) return p_X def _get_cor_mat(self, X):
"""get kernel matrix"""
X = np.array(X)
l = X.shape[0]
cor_mat = [] for c_idx in range(l):
col = []
c_mat = X[c_idx].copy() for r_idx in range(l):
r_mat = X[r_idx].copy()
temp_cor = self._get_corelation(c_mat, r_mat)
col.append(temp_cor)
cor_mat.append(col) return np.mat(cor_mat) def _get_cor_mat_joint(self, X, X_train):
"""
get kernel matrix
"""
X = np.array(X)
X_train = np.array(X_train)
l_c = X.shape[0]
l_r = X_train.shape[0]
cor_mat = [] for c_idx in range(l_c):
col = []
c_mat = X[c_idx].copy() for r_idx in range(l_r):
r_mat = X_train[r_idx].copy()
temp_cor = self._get_corelation(c_mat, r_mat)
col.append(temp_cor)
cor_mat.append(col) return np.mat(cor_mat) def fit(self, X, y):
self.get_initial_mean(X[0::2], y[0::2])
self.get_initial_cov(X) # 更新(训练)gpnas预测器超参数
self.get_posterior_mean(X[1::2], y[1::2]) def predict(self, X):
X = self._preprocess_X(X)
X = np.mat(X) # print('beta',self.w.flatten())
return X * self.w def get_predict(self, X):
"""
get the prediction of network architecture X
"""
X = self._preprocess_X(X)
X = np.mat(X) return X * self.w def get_predict_jiont(self, X, X_train, Y_train):
"""
get the prediction of network architecture X based on X_train and Y_train
"""
X = np.mat(X)
X_train = np.mat(X_train)
Y_train = np.mat(Y_train)
m_X = self.get_predict(X)
m_X_train = self.get_predict(X_train)
mat_train = self._get_cor_mat(X_train)
mat_joint = self._get_cor_mat_joint(X, X_train) return m_X + mat_joint * np.linalg.inv(mat_train + self.hp_mat * np.eye(
X_train.shape[0])) * (Y_train.T - m_X_train) def get_initial_mean(self, X, Y):
"""
get initial mean of w
"""
X = self._preprocess_X(X)
X = np.mat(X)
Y = np.mat(Y)
self.w = np.linalg.inv(X.T * X + self.hp_mat * np.eye(X.shape[ 1])) * X.T * Y.T # inv(X.T*X)X.T*Y as initial mean
print('Variance', np.var(Y - X * self.w)) # Show variance of residual then we can base this tunning self.hp_cov
return self.w def get_initial_cov(self, X):
"""
get initial coviarnce matrix of w
"""
X = self._preprocess_X(X)
X = np.mat(X) if self.icov == 1: # use inv(X.T*X) as initial covariance
self.cov_w = self.hp_cov * np.linalg.inv(X.T * X) elif self.icov == 0: # use identity matrix as initial covariance
self.cov_w = self.hp_cov * np.eye(X.shape[1]) else: assert 0, 'not available yet'
return self.cov_w def get_posterior_mean(self, X, Y):
"""
get posterior mean of w
"""
X = self._preprocess_X(X)
X = np.mat(X)
Y = np.mat(Y)
cov_mat = self._get_cor_mat(X) if self.m_flag == 1:
self.w = self.w + self.cov_w * X.T * np.linalg.inv(
np.linalg.inv(cov_mat + self.hp_mat * np.eye(X.shape[0])) + X *
self.cov_w * X.T + self.hp_mat * np.eye(X.shape[0])) * (
Y.T - X * self.w) else:
self.w = np.linalg.inv(X.T * np.linalg.inv(
cov_mat + self.hp_mat * np.eye(X.shape[0])) * X + np.linalg.inv(
self.cov_w + self.hp_mat * np.eye(X.shape[ 1])) + self.hp_mat * np.eye(X.shape[1])) * (
X.T * np.linalg.inv(cov_mat + self.hp_mat * np.eye(
X.shape[0])) * Y.T +
np.linalg.inv(self.cov_w + self.hp_mat * np.eye(
X.shape[1])) * self.w) return self.w def get_posterior_cov(self, X, Y):
"""
get posterior coviarnce matrix of w
"""
X = self._preprocess_X(X)
X = np.mat(X)
Y = np.mat(Y)
cov_mat = self._get_cor_mat(X)
self.cov_mat = np.linalg.inv(
np.linalg.inv(X.T * cov_mat * X + self.hp_mat * np.eye(X.shape[1]))
+ np.linalg.inv(self.cov_w + self.hp_mat * np.eye(X.shape[ 1])) + self.hp_mat * np.eye(X.shape[1])) return self.cov_mat
def convert_X1(arch_str):
# Transform all the encode to [-1, 0, 1]
tmp_arch = [] for i, elm in enumerate(arch_str): if i in [3, 6, 9, 12, 15, 18, 21, 24, 27, 30, 33, 36]: pass
elif elm == 'j':
tmp_arch.append(1 - 2) elif elm == 'k':
tmp_arch.append(2 - 2) elif elm == 'l':
tmp_arch.append(3 - 2) elif int(elm) == 0:
tmp_arch.append(2 - 2) else:
tmp_arch.append(int(elm) - 2) return tmp_archdef convert_X2(arch_str):
tmp_arch = [] for i, elm in enumerate(arch_str): if i in [3, 6, 9, 12, 15, 18, 21, 24, 27, 30, 33, 36]: pass
elif elm == 'j':
tmp_arch = tmp_arch + [1, 0, 0, 0] elif elm == 'k':
tmp_arch = tmp_arch + [0, 1, 0, 0] elif elm == 'l':
tmp_arch = tmp_arch + [0, 0, 1, 0] elif int(elm) == 0:
tmp_arch = tmp_arch + [0, 0, 0, 0] elif int(elm) == 1:
tmp_arch = tmp_arch + [1, 0, 0, 0] elif int(elm) == 2:
tmp_arch = tmp_arch + [0, 1, 0, 0] elif int(elm) == 3:
tmp_arch = tmp_arch + [0, 0, 1, 0] return tmp_archwith open('CCF_UFO_train.json', 'r') as f: # train_data is
# keys from 'arch1' to 'arch500'
# 'arch': 'l231131331121121331111211121331321321', j-10, k-11, l-12
# l 231 131 331 121 121 331 111 211 121 331 321 321
# k 111 221 321 131 331 321 311 321 311 311 321 000
# j 221 311 211 121 321 321 111 331 221 311 000 000
train_data = json.load(f) with open('CCF_UFO_test.json', 'r') as f:
test_data = json.load(f)test_arch_list1, test_arch_list2 = [], []for key in test_data.keys():
test_arch = convert_X1(test_data[key]['arch'])
test_arch_list1.append(test_arch)for key in test_data.keys():
test_arch = convert_X2(test_data[key]['arch'])
test_arch_list2.append(test_arch)#encoding methods for training datatrain_list = [[], [], [], [], [], [], [], []]
arch_list_train1, arch_list_train2 = [], []
name_list = ['cplfw_rank', 'market1501_rank', 'dukemtmc_rank', 'msmt17_rank', 'veri_rank', 'vehicleid_rank', 'veriwild_rank', 'sop_rank']for key in train_data.keys(): for idx, name in enumerate(name_list):
train_list[idx].append(train_data[key][name])
xx = train_data[key]['arch']
arch_list_train1.append(convert_X1(xx))for key in train_data.keys():
xx = train_data[key]['arch']
arch_list_train2.append(convert_X2(xx))标签编码
直接预测原始的rank标签效果不好,通过inverse-sigmoid更改标签分布
Y_all0 = np.array(train_list) # shape: 8x500Y_all = np.log((Y_all0 + 1) / (500 - Y_all0))
超参数设置
对每个task使用不同的学习率,回归器参数等等
同时每个task有一个特定的GPNAS来集成各个模块特征
max_iter = [10000, 10000, 10000, 10000, 10000, 10000, 10000, 10000]
learning_rate = [0.004, 0.038, 0.035, 0.03, 0.025, 0.01, 0.03, 0.01]
max_depth = [1, 3, 2, 2, 2, 3, 1, 3]
max_depth2 = [1, 1, 1, 1, 1, 1, 1, 1]
cv = [5, 10, 10, 10, 5, 5, 4, 5]
list_est = []
model_GBRT, model_HISTGB, model_CATGB, model_LIGHTGB, model_XGB, model_GBRT2, model_CATGB2 = [], [], [], [], [], [], []for i in range(8):
params_GBRT = {"n_estimators": max_iter[i], "max_depth": max_depth[i], "subsample": .8, "learning_rate": learning_rate[i], "loss": 'huber', "max_features": 'sqrt', "random_state": 1,
}
model_GBRT.append(ensemble.GradientBoostingRegressor(**params_GBRT))
params_HISTGB = { "max_depth": max_depth2[i], "max_iter": max_iter[i], "learning_rate": learning_rate[i], "loss": 'squared_error', "max_leaf_nodes": 31, "min_samples_leaf": 5, "l2_regularization": 5, "random_state": 1,
}
model_HISTGB.append(HistGradientBoostingRegressor(**params_HISTGB))
model_CATGB.append(catboost.CatBoostRegressor(iterations=max_iter[i],
learning_rate=learning_rate[i],
depth=max_depth[i],
silent=True,
task_type="CPU",
loss_function='RMSE',
eval_metric='RMSE',
random_seed=1,
od_type='Iter',
metric_period=75,
od_wait=100,
))
model_LIGHTGB.append(lightgbm.LGBMRegressor(boosting_type='gbdt', learning_rate=learning_rate[i], num_leaves=31,
max_depth=max_depth2[i], alpha=0.1, n_estimators=max_iter[i],
random_state=1))
model_XGB.append(xgboost.XGBRegressor(learning_rate=learning_rate[i], tree_method='auto',
max_depth=max_depth2[i], alpha=0.8, n_estimators=max_iter[i], random_state=1))
params_GBRT2 = {"n_estimators": max_iter[i], "max_depth": max_depth[i], "subsample": .8, "learning_rate": learning_rate[i], "loss": 'squared_error', "max_features": 'log2', "random_state": 1,
}
model_GBRT2.append(ensemble.GradientBoostingRegressor(**params_GBRT2))
model_CATGB2.append(catboost.CatBoostRegressor(iterations=max_iter[i],
learning_rate=learning_rate[i],
depth=max_depth[i],
silent=True,
task_type="CPU",
loss_function='Huber:delta=2',
eval_metric='Huber:delta=2',
random_seed=1,
od_type='Iter',
metric_period=75,
od_wait=100,
l2_leaf_reg=1,
subsample=0.8,
))不同的task使用不同的子回归器,且各自参数不同
如 task1 使用 GBRT HISTGB CATGB LIGHTGB XGB GBRT2 CATGB2
task2 使用 GBRT CATGB LIGHTGB XGB GBRT2 CATGB2
# Task 1list_est.append([
('GBRT', model_GBRT[0]),
('HISTGB', model_HISTGB[0]),
('CATGB', model_CATGB[0]),
('LIGHTGB', model_LIGHTGB[0]),
('XGB', model_XGB[0]),
('GBRT2', model_GBRT2[0]),
('CATGB2', model_CATGB2[0]),
])# Task 2list_est.append([
('GBRT', model_GBRT[1]),
('CATGB', model_CATGB[1]),
('LIGHTGB', model_LIGHTGB[1]),
('XGB', model_XGB[1]),
('GBRT2', model_GBRT2[1]),
('CATGB2', model_CATGB2[1]),
])# Task 3list_est.append([
('GBRT', model_GBRT[2]),
('HISTGB', model_HISTGB[2]),
('CATGB', model_CATGB[2]),
('LIGHTGB', model_LIGHTGB[2]),
('XGB', model_XGB[2]),
('CATGB2', model_CATGB2[2]),
])# Task 4list_est.append([
('GBRT', model_GBRT[3]),
('HISTGB', model_HISTGB[3]),
('CATGB', model_CATGB[3]),
('LIGHTGB', model_LIGHTGB[3]),
('XGB', model_XGB[3]),
('GBRT2', model_GBRT2[3]),
('CATGB2', model_CATGB2[3]),
])# Task 5list_est.append([
('GBRT', model_GBRT[4]),
('HISTGB', model_HISTGB[4]),
('CATGB', model_CATGB[4]),
('LIGHTGB', model_LIGHTGB[4]),
('XGB', model_XGB[4]),
('CATGB2', model_CATGB2[4]),
])# Task 6list_est.append([
('HISTGB', model_HISTGB[5]),
('CATGB', model_CATGB[5]),
('LIGHTGB', model_LIGHTGB[5]),
('XGB', model_XGB[5]),
('GBRT2', model_GBRT2[5]),
('CATGB2', model_CATGB2[5]),
])# Task 7list_est.append([
('GBRT', model_GBRT[6]),
('HISTGB', model_HISTGB[6]),
('CATGB', model_CATGB[6]),
('LIGHTGB', model_LIGHTGB[6]),
('XGB', model_XGB[6]),
('CATGB2', model_CATGB2[6]),
])# Task 8list_est.append([
('GBRT', model_GBRT[7]),
('HISTGB', model_HISTGB[7]),
('CATGB', model_CATGB[7]),
('LIGHTGB', model_LIGHTGB[7]),
('XGB', model_XGB[7]),
('GBRT2', model_GBRT2[7]),
('CATGB2', model_CATGB2[7]),
])各任务对应的GPNAS
gp_est = [
GPNAS2(c_flag=1, m_flag=1, hp_mat=0.07, hp_cov=0.04, icov=0), # Task 1
GPNAS2(c_flag=2, m_flag=2, hp_mat=0.5, hp_cov=3, icov=1), # Task 2
GPNAS2(c_flag=1, m_flag=2, hp_mat=0.3, hp_cov=2.0, icov=0), # Task 3
GPNAS2(c_flag=1, m_flag=2, hp_mat=0.5, hp_cov=0.1, icov=1), # Task 4
GPNAS2(c_flag=1, m_flag=2, hp_mat=0.4, hp_cov=0.5, icov=0), # Task 5
GPNAS2(c_flag=1, m_flag=2, hp_mat=0.1, hp_cov=0.01, icov=0), # Task 6
GPNAS2(c_flag=2, m_flag=2, hp_mat=0.01, hp_cov=0.5, icov=1), # Task 7
GPNAS2(c_flag=1, m_flag=2, hp_mat=0.47, hp_cov=2, icov=1), # Task 8]训练预测方式1
对应AB榜最优结果
# encode 1X_train_k1 = np.array(arch_list_train1)
X_val1 = np.array(test_arch_list1)
rank_all1 = []for i in [0, 1, 2, 3, 4, 5, 7]: print('No: ', i) # stack different regressor by GPNAS with cross validation
model_final = StackingRegressor(estimators=list_est[i],
final_estimator=gp_est[i],
passthrough=False, cv=cv[i], n_jobs=4)
Y_train_k = Y_all[i]
model_final.fit(X_train_k1, Y_train_k)
zz = np.round((X_val1.shape[0] - 1) / (1 + np.exp(-1 * model_final.predict(X_val1))) - 1) # 标签解码
rank_all1.append(zz)# encode 2X_train_k2 = np.array(arch_list_train2)
X_val2 = np.array(test_arch_list2)
rank_all2 = []for i in [6]: print('No: ', i) # stack different regressor by GPNAS with cross validation
model_final = StackingRegressor(estimators=list_est[i],
final_estimator=gp_est[i],
passthrough=False, cv=cv[i], n_jobs=4)
Y_train_k = Y_all[i]
model_final.fit(X_train_k2, Y_train_k)
zz = np.round((X_val2.shape[0] + 1) / (1 + np.exp(-1 * model_final.predict(X_val2))) - 1) # 标签解码
rank_all2.append(zz)No: 0
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/joblib/externals/loky/process_executor.py:706: UserWarning: A worker stopped while some jobs were given to the executor. This can be caused by a too short worker timeout or by a memory leak. "timeout or by a memory leak.", UserWarning
Variance 3.350329103751692 No: 1
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/joblib/externals/loky/process_executor.py:706: UserWarning: A worker stopped while some jobs were given to the executor. This can be caused by a too short worker timeout or by a memory leak. "timeout or by a memory leak.", UserWarning
Variance 6.049711124124197105 No: 2
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/joblib/externals/loky/process_executor.py:706: UserWarning: A worker stopped while some jobs were given to the executor. This can be caused by a too short worker timeout or by a memory leak. "timeout or by a memory leak.", UserWarning
Variance 6.008238879323918 No: 3
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/joblib/externals/loky/process_executor.py:706: UserWarning: A worker stopped while some jobs were given to the executor. This can be caused by a too short worker timeout or by a memory leak. "timeout or by a memory leak.", UserWarning
Variance 6.104897599073192 No: 4
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/joblib/externals/loky/process_executor.py:706: UserWarning: A worker stopped while some jobs were given to the executor. This can be caused by a too short worker timeout or by a memory leak. "timeout or by a memory leak.", UserWarning
Variance 6.0256214558717325 No: 5 Variance 5.838685457519473
训练预测方式2
对应B榜主动提交结果
将预测结果重排
# X_train_k1 = np.array(arch_list_train1)# X_val1 = np.array(test_arch_list1)# rank_all1 = []# for i in [0, 1, 2, 3, 4, 5, 7]:# print('No: ', i)# model_final = StackingRegressor(estimators=list_est[i],# final_estimator=gp_est[i],# passthrough=False, cv=cv[i], n_jobs=4)# Y_train_k = Y_all[i]# model_final.fit(X_train_k1, Y_train_k)# zz = ((X_val1.shape[0] - 1) / (1 + np.exp(-1 * model_final.predict(X_val1))) - 1)# zz = np.asarray(zz)# zz = zz.reshape(99500,)# tmp = zz.argsort()# rr = np.empty_like(tmp)# rr[tmp] = np.arange(len(zz))# rank_all1.append(rr)# X_train_k2 = np.array(arch_list_train2)# X_val2 = np.array(test_arch_list2)# rank_all2 = []# for i in [6]:# print('No: ', i)# model_final = StackingRegressor(estimators=list_est[i],# final_estimator=gp_est[i],# passthrough=False, cv=cv[i], n_jobs=4)# Y_train_k = Y_all[i]# model_final.fit(X_train_k2, Y_train_k)# zz = ((X_val2.shape[0] + 1) / (1 + np.exp(-1 * model_final.predict(X_val2))) - 1)# zz = np.asarray(zz)# zz = zz.reshape(99500, )# tmp = zz.argsort()# rr = np.empty_like(tmp)# rr[tmp] = np.arange(len(zz))# rank_all2.append(rr)生成提交文件
for idx, key in enumerate(test_data.keys()):
test_data[key]['cplfw_rank'] = int(rank_all1[0][idx])
test_data[key]['market1501_rank'] = int(rank_all1[1][idx])
test_data[key]['dukemtmc_rank'] = int(rank_all1[2][idx])
test_data[key]['msmt17_rank'] = int(rank_all1[3][idx])
test_data[key]['veri_rank'] = int(rank_all1[4][idx])
test_data[key]['vehicleid_rank'] = int(rank_all1[5][idx])
test_data[key]['veriwild_rank'] = int(rank_all2[0][idx])
test_data[key]['sop_rank'] = int(rank_all1[6][idx])with open('./aistudio-version.json', 'w') as f:
json.dump(test_data, f)贝叶斯优化调参
调参过程
下面给出task1的GPNAS调参过程示例
# from bayes_opt import BayesianOptimization# X_train_k1 = np.array(arch_list_train1)# X_val1 = np.array(test_arch_list1)# def rf_cv(hp_mat, hp_cov):# val = cross_val_score(StackingRegressor(estimators=list_est[0],# final_estimator=GPNAS2(c_flag=1, m_flag=1, hp_mat=float(hp_mat),# hp_cov=float(hp_cov), icov=0),# passthrough=False, cv=cv[i], n_jobs=4)# , X=X_train_k1, y=Y_all[0], verbose=0, cv=5, scoring=make_scorer(mean_squared_error)# ).mean()# return 1 - val# rf_bo = BayesianOptimization(# rf_cv,# {# 'hp_mat': (0, 3),# 'hp_cov': (0, 3),# }# )# rf_bo.maximize()
























