






飞桨常规赛:PALM眼底彩照视盘探测与分割
常规赛简介
飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,是中国首个开源开放、技术领先、功能完备的产业级深度学习平台。更多飞桨资讯,点击此处查看。
飞桨常规赛由百度飞桨于 2019 年发起,面向全球 AI 开发者,赛题范围广,涵盖领域多。常规赛旨在通过长期发布的经典比赛项目,为开发者提供学习锻炼机会,助力大家在飞桨大赛中获得骄人成绩。
参赛选手需使用飞桨框架,基于特定赛题下的真实行业数据完成并提交任务。常规赛采取月度评比方式,为打破历史最高记录选手和当月有资格参与月度评奖的前 10 名选手提供飞桨特别礼包奖励。更多惊喜,更多收获,尽在飞桨常规赛。
赛题介绍 本赛题原型为ISBI2019PALM眼科大赛。 近视已成为全球公共卫生负担。在近视患者中,约35%为高度近视。近视导致眼轴长度的延长,可能引起视网膜和脉络膜的病理改变。随着近视屈光度的增加,高度近视将发展为病理性近视,其特点是病理改变的形成:(1)后极,包括镶嵌型眼底、后葡萄肿、视网膜脉络膜变性等;(2)视盘,包括乳头旁萎缩、倾斜等;(3)近视性黄斑,包括漆裂、福氏斑、CNV等。病理性近视对患者造成不可逆的视力损害。因此,早期诊断和定期随访非常重要。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
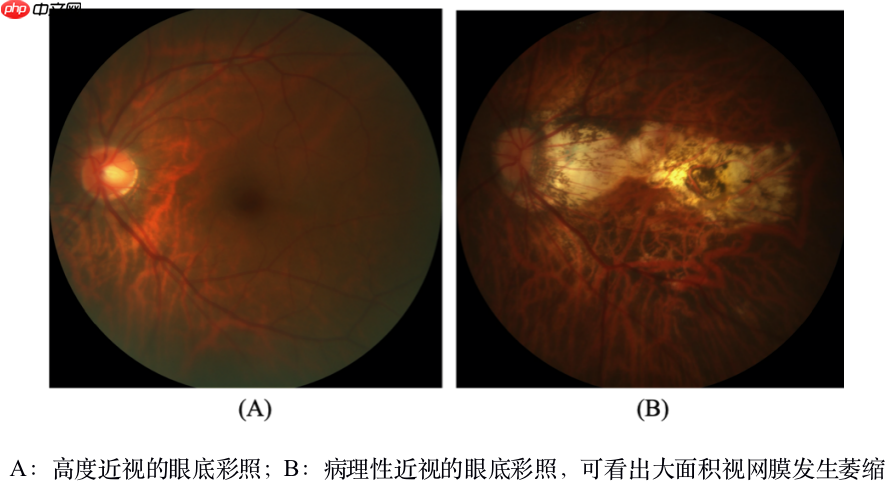
视网膜由黄斑向鼻侧约3mm处有一直径约1.5mm、境界清楚的淡红色圆盘状结构,称为视神经盘,简称视盘。视盘是眼底图像的一个重要特征,对其进行准确、快速地定位与分割对利用眼底图像进行疾病辅助诊断具有重要意义。
比赛任务
该任务目的是对眼底图像的视盘进行检测,若存在视盘结构,需从眼底图像中分割出视盘区域;若无视盘结构,分割结果直接置全背景。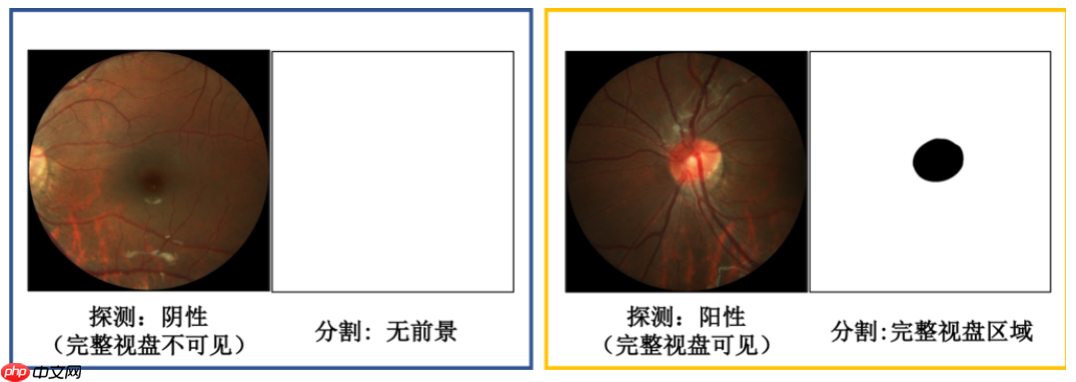
数据集介绍
本次常规赛提供的金标准由中山大学中山眼科中心的7名眼科医生手工进行视盘像素级标注,之后由另一位高级专家将它们融合为最终的标注结果。存储为BMP图像,与对应的眼底图像大小相同,标签为0代表视盘(黑色区域);标签为255代表其他(白色区域)。
训练数据集
文件名称:Train Train文件夹里有fundus_images文件夹和Disc_Masks文件夹。
fundus_images文件夹内包含800张眼底彩照,分辨率为1444×1444,或2124124×2056。命名形如H0001.jpg、N0001.jpg、P0001.jpg和V0001.jpg。
Disc_Masks文件夹内包含fundus_images里眼底彩照的视盘分割金标准,大小与对应的眼底彩照一致。命名前缀和对应的fundus_images文件夹里的图像命名一致,后缀为bmp。
测试数据集
文件名称:PALM-Testing400-Images
包含400张眼底彩照,命名形如T0001.jpg。
数据集下载:
常规赛:PALM眼底彩照视盘探测与分割数据集

比赛思路
看到语义分割就应该想到PaddleSeg套件啦!可对照PaddleSeg代码解读项目搭建自己的项目
先用Unet进行分割。对预测结果进行处理。
进行分割结果孔洞填充
假如某一张图片预测的结果出现多个不连通的区域,通过面积筛选,只保留最大的面积。(可提升一点dice)
PLAM_model_4成绩为:0.94979
一、数据准备
1.11、解压数据集
#解压数据!unzip -o data/data86770/seg.zip -d /home/aistudio/work
1.2、划分数据集
import randomimport os
random.seed(2021)
mask_dir = '/home/aistudio/work/seg/Train/masks'img_dir = '/home/aistudio/work/seg/Train/fundus_image'path_list = list()for img in os.listdir(img_dir):
img_path = os.path.join(img_dir,img)
mask_path = os.path.join(mask_dir,img.replace('jpg', 'png'))
path_list.append((img_path, mask_path))
random.shuffle(path_list)
ratio = 0.8train_f = open('/home/aistudio/work/seg/Train/train.txt','w')
val_f = open('/home/aistudio/work/seg/Train/val.txt' ,'w')for i ,content in enumerate(path_list):
img, mask = content
text = img + ' ' + mask + '\n'
if i < len(path_list) * ratio:
train_f.write(text) else:
val_f.write(text)
train_f.close()
val_f.close()
1.3、导入依赖项
!pip install paddleseg
#导入常用的库import osimport randomimport numpy as npfrom random import shuffleimport cv2import paddlefrom PIL import Imageimport shutilimport refrom paddle.vision.transforms import functional as Fimport os.path
二、网络训练
2.1 数据增强
import paddleseg.transforms as Tfrom paddleseg.datasets import OpticDiscSeg,Dataset
train_transforms = [
T.RandomHorizontalFlip(),# 水平翻转
T.RandomVerticalFlip(),# 垂直翻转
T.RandomDistort(0.4),# 随机扭曲
T.RandomBlur(0.3),# 高斯模糊
T.RandomScaleAspect(min_scale=0.5,aspect_ratio=0.5),# 随机缩放
T.Resize(target_size=(512,512)),
T.Normalize() # 图像标准化]
val_transforms = [
T.Resize(target_size=(512,512)),
T.Normalize()
]
2.2 构建训练集与验证集
dataset_root = '/home/aistudio/work/seg/Train'train_path = '/home/aistudio/work/seg/Train/train.txt'val_path = '/home/aistudio/work/seg/Train/val.txt'# 构建训练集train_dataset = Dataset(
dataset_root=dataset_root,
train_path=train_path,
transforms=train_transforms,
num_classes=2,
mode='train'
)#验证集val_dataset = Dataset(
dataset_root=dataset_root,
val_path=val_path,
transforms=val_transforms,
num_classes=2,
mode='val'
)
2.3 训练配置
学习率:余弦退火策略(CosineAnnealingDecay)
class paddle.optimizer.lr. CosineAnnealingDecay ( learning_rate, T_max, eta_min=0, last_epoch=- 1, verbose=False )
参数:
- learning_rate (float) - 初始学习率。
- T_max (float|int) - 训练的上限轮数,是余弦衰减周期的一半。
- eta_min (float|int, 可选) - 学习率的最小值。默认值为0。
- last_epoch (int,可选) - 上一轮的轮数,重启训练时设置为上一轮的epoch数。默认值为 -1,则为初始学习率。
- verbose (bool,可选) - 如果是 True ,则在每一轮更新时在标准输出 stdout 输出一条信息。默认值为 False 。
返回:用于调整学习率的 CosineAnnealingDecay 实例对象。
优化器:Adam
class paddle.optimizer. Adam ( learning_rate=0.001, beta1=0.9, beta2=0.999, epsilon=1e-08, parameters=None, weight_decay=None, grad_clip=None, name=None, lazy_mode=False )
参数:
- learning_rate (float|_LRScheduler) - 学习率,用于参数更新的计算。可以是一个浮点型值或者一个_LRScheduler类,默认值为0.001
- beta1 (float|Tensor, 可选) - 一阶矩估计的指数衰减率,是一个float类型或者一个shape为[1],数据类型为float32的Tensor类型。默认值为0.9
- beta2 (float|Tensor, 可选) - 二阶矩估计的指数衰减率,是一个float类型或者一个shape为[1],数据类型为float32的Tensor类型。默认值为0.999
- epsilon (float, 可选) - 保持数值稳定性的短浮点类型值,默认值为1e-08
- parameters (list, 可选) - 指定优化器需要优化的参数。在动态图模式下必须提供该参数;在静态图模式下默认值为None,这时所有的参数都将被优化。
- weight_decay (float|WeightDecayRegularizer,可选) - 正则化方法。可以是float类型的L2正则化系数或者正则化策略: cn_api_fluid_regularizer_L1Decay 、 cn_api_fluid_regularizer_L2Decay 。如果一个参数已经在 ParamAttr 中设置了正则化,这里的正则化设置将被忽略; 如果没有在 ParamAttr 中设置正则化,这里的设置才会生效。默认值为None,表示没有正则化。
- grad_clip (GradientClipBase, 可选) – 梯度裁剪的策略,支持三种裁剪策略: paddle.nn.ClipGradByGlobalNorm 、 paddle.nn.ClipGradByNorm 、 paddle.nn.ClipGradByValue 。 默认值为None,此时将不进行梯度裁剪。
- name (str, 可选)- 该参数供开发人员打印调试信息时使用,具体用法请参见 Name ,默认值为None
- lazy_mode (bool, 可选) - 设为True时,仅更新当前具有梯度的元素。官方Adam算法有两个移动平均累加器(moving-average accumulators)。累加器在每一步都会更新。在密集模式和稀疏模式下,两条移动平均线的每个元素都会更新。如果参数非常大,那么更新可能很慢。 lazy mode仅更新当前具有梯度的元素,所以它会更快。但是这种模式与原始的算法有不同的描述,可能会导致不同的结果,默认为False
import paddlefrom paddleseg.models import UNetfrom paddleseg.models import OCRNetfrom paddleseg.models.losses import CrossEntropyLoss,DiceLoss, MixedLoss
base_lr =0.001iters = 16000 unet_model = UNet(num_classes=2,pretrained='/home/aistudio/output/PLAM_model_3/best_model/model.pdparams')#使用预训练模型unet进行训练# unet_model = UNet(num_classes=2)#使用unet进行训练#自动调整学习率lr =paddle.optimizer.lr.CosineAnnealingDecay(base_lr, T_max=(iters // 3), last_epoch=0.5)
u_optimizer = paddle.optimizer.Adam(lr, parameters=unet_model.parameters())
mixtureLosses = [CrossEntropyLoss(),DiceLoss() ]
mixtureCoef = [0.7,0.3]
losses = {}
losses['types'] = [MixedLoss(mixtureLosses, mixtureCoef)]
losses['coef'] = [1]
2.4 开始训练
#进行训练from paddleseg.core import train
train(
model = unet_model,
train_dataset=train_dataset,
val_dataset=val_dataset,
optimizer=u_optimizer,
save_dir='output/PLAM_model_4',
iters=iters,
batch_size=4,
save_interval=480,
log_iters=10,
num_workers=0,
losses=losses,
use_vdl=True
)
2.5 模型验证
from paddleseg.core import evaluate model = UNet(num_classes=2)#换自己保存的模型文件model_path = 'output/PLAM_model_4/best_model/model.pdparams'para_state_dict = paddle.load(model_path) model.set_dict(para_state_dict) evaluate(model,val_dataset)
三、结果预测
3.1 生成test.txt文件
%cd ~import randomimport os
test_path = r"work/seg/test"test_lst=[]for test in os.listdir(test_path):
test_lst.append(test)
with open('work/seg/test.txt', 'w') as f: for line in test_lst:
f.write(line)
f.write('\n')
3.2 预测分割
PLAM_model_2、PLAM_model_3、PLAM_model_4这三个模型皆可达到0.94+
from paddleseg.core import predictimport paddleseg.transforms as pt
transforms = pt.Compose([
pt.Resize(target_size=(512, 512)),
pt.Normalize()
])
model = UNet(num_classes=2)#生成图片列表image_list = []with open('work/seg/test.txt' ,'r') as f: for line in f.readlines():
image_list.append(os.path.join('work/seg/test/',line.split()[0]))
predict(
model, #换自己保存的模型文件
model_path = 'output/PLAM_model_4/best_model/model.pdparams',
transforms=transforms,
image_list=image_list,
save_dir='results',
)
3.3 生成结果
- 将分割结果二值化,超过127则为255(白色区域),小于 127则为0(黑色区域)
!mkdir /home/aistudio/newimport os
import cv2
result_path = '/home/aistudio/results/pseudo_color_prediction'dist_path = '/home/aistudio/new'for img_name in os.listdir(result_path):
img_path = os.path.join(result_path, img_name)
img = cv2.imread(img_path)
g = img[:,:,1]
ret, result = cv2.threshold(g, 127,255, cv2.THRESH_BINARY_INV)
cv2.imwrite(os.path.join(dist_path,img_name), result)
- 将分割结果0-255翻转,并填充孔洞
import cv2import osimport numpy as np'''
图像说明:
图像为二值化图像,255白色为目标物,0黑色为背景
要填充白色目标物中的黑色孔洞
'''def FillHole_1(imgPath,SavePath):
im_in = cv2.imread(imgPath, cv2.IMREAD_GRAYSCALE);
th, im_th = cv2.threshold(im_in, 220, 255, cv2.THRESH_BINARY_INV);
im_floodfill = im_th.copy()
h, w = im_th.shape[:2]
mask = np.zeros((h+2, w+2), np.uint8)
cv2.floodFill(im_floodfill, mask, (0,0), 255);
im_floodfill_inv = cv2.bitwise_not(im_floodfill)
im_out = im_th | im_floodfill_inv
cv2.imwrite(SavePath, im_out)def FillHole_2(imgPath,SavePath):
im_in = cv2.imread(imgPath, cv2.IMREAD_GRAYSCALE); # 复制 im_in 图像
im_floodfill = im_in.copy() # Mask 用于 floodFill,官方要求长宽+2
h, w = im_in.shape[:2]
mask = np.zeros((h+2, w+2), np.uint8) # floodFill函数中的seedPoint必须是背景
isbreak = False
for i in range(im_floodfill.shape[0]): for j in range(im_floodfill.shape[1]): if(im_floodfill[i][j]==255):
seedPoint=(i,j)
isbreak = True
break
if(isbreak): break
# 得到im_floodfill
cv2.floodFill(im_floodfill, mask, seedPoint, 0); # 得到im_floodfill的逆im_floodfill_inv
im_floodfill_inv = cv2.bitwise_not(im_floodfill) # 把im_in、im_floodfill_inv这两幅图像结合起来得到前景
im_out = im_in | im_floodfill
cv2.imwrite(SavePath, im_out)
result_path = 'new'dist_path = 'new'for img_name in os.listdir(result_path):
img_path = os.path.join(result_path, img_name)
SavePath = os.path.join(dist_path, img_name)
FillHole_1(img_path,SavePath)
FillHole_2(img_path,SavePath)
假如预测中出现多个不连通的区域,只保留最大的区域
参考吖吖查大佬的:飞桨常规赛:PALM眼底彩照视盘探测与分割 2021 5月第1名方案
!mkdir /home/aistudio/Disc_Segmentationimport os
import cv2import matplotlib.pyplot as pltdef cnt_area(cnt):
area = cv2.contourArea(cnt) return area
result_path = '/home/aistudio/new'dist_path = '/home/aistudio/Disc_Segmentation'for img_name in os.listdir(result_path):
img_path = os.path.join(result_path, img_name)
img = cv2.imread(img_path)
g = img[:,:,1]
ret, threshold = cv2.threshold(g, 127,255, cv2.THRESH_BINARY)
contours, hierarch = cv2.findContours(threshold, cv2.RETR_LIST, cv2.CHAIN_APPROX_NONE)
contours.sort(key=cnt_area, reverse=True) if len(contours) > 1: for i in range(1,len(contours)):
cv2.drawContours(threshold, [contours[i]], 0, 0, -1)
_,result = cv2.threshold(threshold, 127, 255, cv2.THRESH_BINARY_INV)
cv2.imwrite(os.path.join(dist_path, img_name), result)
结果打包
将结果打包,下载皆可提交:提交
# 压缩当前路径所有文件,输出zip文件path='Disc_Segmentation'import zipfile,os
zipName = 'Disc_Segmentation.zip' #压缩后文件的位置及名称f = zipfile.ZipFile( zipName, 'w', zipfile.ZIP_DEFLATED )for dirpath, dirnames, filenames in os.walk(path): for filename in filenames: print(filename)
f.write(os.path.join(dirpath,filename))
f.close()




























