






ActiveMLP提出主动Token混合器(ATM),能主动选择各通道Token,灵活合并跨通道上下文信息,在有限计算下扩展Token混合空间范围至全局。以ATM为核心组成ATMNet,在视觉识别等任务中全面超越现有SOTA骨干。文中展示了其架构(含ATM层、Block等),在CIFAR10上训练,ActivexTiny等模型表现出良好准确率与吞吐量。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

ActiveMLP:使用主动Token混合的MLP架构
摘要
现有的三个主流网络家族,即CNNS、Transformers和MLPs,主要在融合空间上下文信息的方式上存在差异,使得设计更有效的令牌混合机制成为骨干架构开发的核心。 在这项工作中,我们创新性地提出了一个Token混合器,称为主动Token混合器(ATM),它可以主动地将来自其他令牌的跨不同通道分布的上下文信息灵活地合并到给定的查询Token中。 这个基本运算符主动预测在哪里捕获有用的上下文,并学习如何将捕获的上下文与通道级别的查询Token融合。 这样,在有限的计算复杂度下,可以将Token混合的空间范围扩展到全局范围,从而对Token混合的方式进行了改革。 我们以ATM为主要算子,将ATM组装成一个级联架构,称为ATMNet。 大量的实验表明,ATMNet是普遍适用的,在包括视觉识别和密集预测任务在内的多种视觉任务中,它以明显的优势全面超越了不同种类的SOTA视觉骨干。
1. ActiveMLP
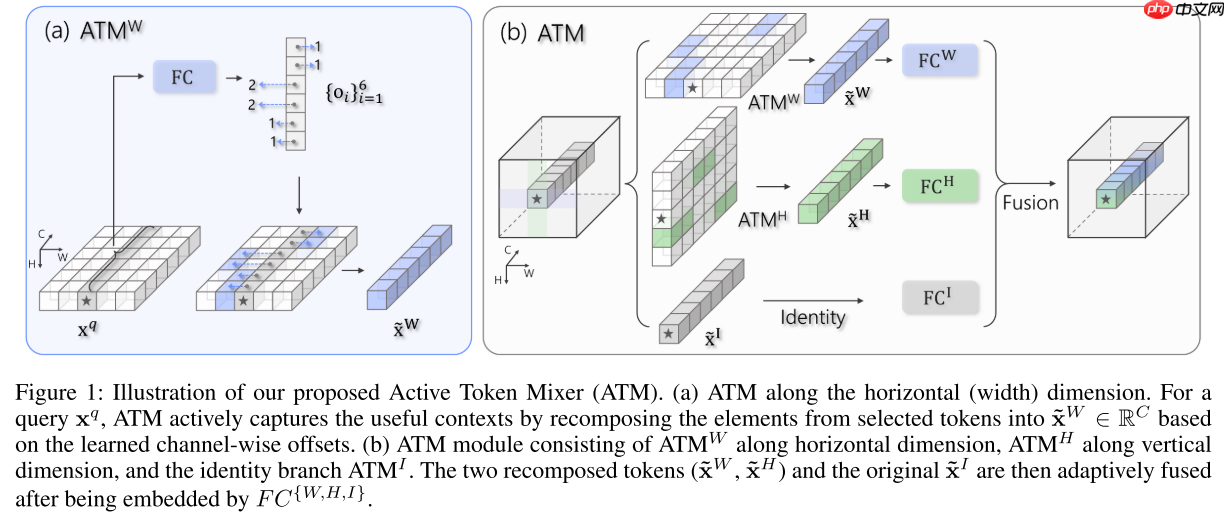
现有的三个主流网络家族(CNN、Transformer、MLP)可以统一地表示为如下公式:
f(X)∣xq=k∈N(xq)∑ωk→q∗g(xk)

其中 xq 表示查询Token, N(xq) 表示查询Token的上下文, ωk→q 表示从 xk 到 xq 的信息传播程度。
对于网络架构设计,本文提出了如下两个关键见解:
- 对于空间维度,视觉对象/东西呈现出不同的形状和变形。 因此,在固定范围 N(⋅) 内的信息混合是低效和不充分的。 信息传递的自适应 ωk→q 和 N(⋅) 是提取可视表示的理想选择
- 对于通道维度,一个令牌中携带的多个语义属性分布于其不同的通道,在所有通道上共享 ωk→q∈R 的Token级消息传递不能自适应地处理不同语义,限制了它们的充分利用,因而效率较低。
为此本文提出了一种新的算子ATM,如图1所示,该算子的主要思想是通过输入自适应地选择各个通道的Token,然后使用一个MLP进行聚合信息,为了减少计算量,本文分别在H、W、C三个维度进行该操作,然后使用Split Attention进行聚合。
2. 代码复现
2.1 下载并导入所需的库
%matplotlib inlineimport paddleimport numpy as npimport matplotlib.pyplot as pltfrom paddle.vision.datasets import Cifar10from paddle.vision.transforms import Transposefrom paddle.io import Dataset, DataLoaderfrom paddle import nnimport paddle.nn.functional as Fimport paddle.vision.transforms as transformsimport osimport matplotlib.pyplot as pltfrom matplotlib.pyplot import figureimport itertoolsfrom functools import partialfrom paddle.vision.ops import deform_conv2d
2.2 创建数据集
train_tfm = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.ColorJitter(brightness=0.2,contrast=0.2, saturation=0.2),
transforms.RandomHorizontalFlip(0.5),
transforms.RandomRotation(20),
transforms.ToTensor(),
transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
])
test_tfm = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
])
paddle.vision.set_image_backend('cv2')# 使用Cifar10数据集train_dataset = Cifar10(data_file='data/data152754/cifar-10-python.tar.gz', mode='train', transform = train_tfm, )
val_dataset = Cifar10(data_file='data/data152754/cifar-10-python.tar.gz', mode='test',transform = test_tfm)print("train_dataset: %d" % len(train_dataset))print("val_dataset: %d" % len(val_dataset))
train_dataset: 50000 val_dataset: 10000
batch_size=256
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, drop_last=True, num_workers=4) val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, drop_last=False, num_workers=4)
2.3 模型的创建
2.3.1 标签平滑
class LabelSmoothingCrossEntropy(nn.Layer):
def __init__(self, smoothing=0.1):
super().__init__()
self.smoothing = smoothing def forward(self, pred, target):
confidence = 1. - self.smoothing
log_probs = F.log_softmax(pred, axis=-1)
idx = paddle.stack([paddle.arange(log_probs.shape[0]), target], axis=1)
nll_loss = paddle.gather_nd(-log_probs, index=idx)
smooth_loss = paddle.mean(-log_probs, axis=-1)
loss = confidence * nll_loss + self.smoothing * smooth_loss return loss.mean()
2.3.2 DropPath
def drop_path(x, drop_prob=0.0, training=False):
"""
Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...
See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ...
"""
if drop_prob == 0.0 or not training: return x
keep_prob = paddle.to_tensor(1 - drop_prob)
shape = (paddle.shape(x)[0],) + (1,) * (x.ndim - 1)
random_tensor = keep_prob + paddle.rand(shape, dtype=x.dtype)
random_tensor = paddle.floor(random_tensor) # binarize
output = x.divide(keep_prob) * random_tensor return outputclass DropPath(nn.Layer):
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob def forward(self, x):
return drop_path(x, self.drop_prob, self.training)
2.3.3 ATMNet模型的创建
2.3.3.1 FFN
class Mlp(nn.Layer):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop) def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x) return x
2.3.3.2 ATM操作符
class ATMOp(nn.Layer):
def __init__(self, in_chans, out_chans, stride=1, padding=0, dilation=1, bias=True, dimension=''):
super().__init__()
self.in_chans = in_chans
self.out_chans = out_chans
self.stride = stride
self.padding = padding
self.dilation = dilation
self.dimension = dimension
self.weight = self.create_parameter([out_chans, in_chans, 1, 1]) if bias:
self.bias = self.create_parameter([out_chans]) else:
self.bias = None
def forward(self, x, offset):
B, C, H, W = x.shape
offset_t = paddle.zeros((B, 2 * C * 1 * 1, H, W)) if self.dimension == 'w':
offset_t[:, 1::2, :, :] += offset elif self.dimension == 'h':
offset_t[:, 0::2, :, :] += offset else: raise NotImplementedError(f"{self.dimension} dimension not implemented") return deform_conv2d(x, offset_t, self.weight, self.bias, self.stride, self.padding, self.dilation, deformable_groups=C)
2.3.3.3 ATM层
class ATMLayer(nn.Layer):
def __init__(self, dim, proj_drop=0.):
super().__init__()
self.dim = dim
self.atm_c = nn.Linear(dim, dim, bias_attr=False)
self.atm_h = ATMOp(dim, dim, dimension='h')
self.atm_w = ATMOp(dim, dim, dimension='w')
self.fusion = Mlp(dim, dim // 4, dim * 3)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop) def forward(self, x, offset):
"""
x: [B, H, W, C]
offsets: [B, 2C, H, W]
"""
B, H, W, C = x.shape # assert offset.shape == (B, 2 * C, H, W), f"offset shape not match, got {offset.shape}"
w = self.atm_w(x.transpose([0, 3, 1, 2]), offset[:, :C, :, :]).transpose([0, 2, 3, 1])
h = self.atm_h(x.transpose([0, 3, 1, 2]), offset[:, C:, :, :]).transpose([0, 2, 3, 1])
c = self.atm_c(x)
a = (w + h + c).transpose([0, 3, 1, 2]).flatten(2).mean(2)
a = self.fusion(a).reshape((B, C, 3)).transpose([2, 0, 1])
a = F.softmax(a, axis=0).unsqueeze(2).unsqueeze(2)
x = w * a[0] + h * a[1] + c * a[2]
x = self.proj(x)
x = self.proj_drop(x) return x
2.3.3.4 ATM Block
class ActiveBlock(nn.Layer):
def __init__(self, dim, mlp_ratio=4., drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm,
share_dim=1, downsample=None, new_offset=False, ):
super().__init__()
self.norm1 = norm_layer(dim)
self.atm = ATMLayer(dim)
self.norm2 = norm_layer(dim)
self.mlp = Mlp(in_features=dim, hidden_features=int(dim * mlp_ratio), act_layer=act_layer)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.downsample = downsample
self.new_offset = new_offset
self.share_dim = share_dim if new_offset:
self.offset_layer = nn.Sequential(
norm_layer(dim),
nn.Linear(dim, dim * 2 // self.share_dim)
) else:
self.offset_layer = None
def forward(self, x, offset=None):
"""
:param x: [B, H, W, C]
:param offset: [B, 2C, H, W]
"""
if self.offset_layer and offset is None:
offset = self.offset_layer(x)
offset = paddle.repeat_interleave(offset, self.share_dim, axis=3).transpose([0, 3, 1, 2])
x = x + self.drop_path(self.atm(self.norm1(x), offset))
x = x + self.drop_path(self.mlp(self.norm2(x))) if self.downsample is not None:
x = self.downsample(x) if self.offset_layer: return x, offset else: return x
2.3.3.5 Downsample
class Downsample(nn.Layer):
def __init__(self, in_chans, out_chans):
super().__init__()
self.proj = nn.Conv2D(in_chans, out_chans, kernel_size=(3, 3), stride=(2, 2), padding=1) def forward(self, x):
"""
x: [B, H, W, C]
"""
x = x.transpose([0, 3, 1, 2])
x = self.proj(x)
x = x.transpose([0, 2, 3, 1]) return x
2.3.3.6 条件位置编码
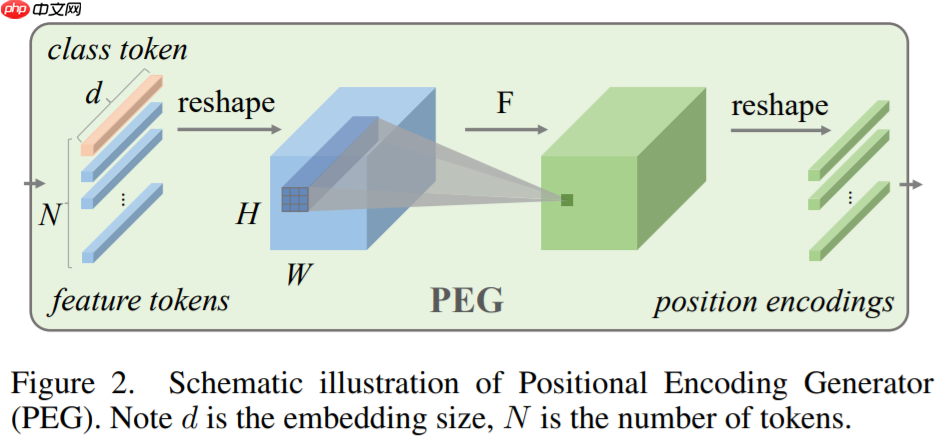
class PEG(nn.Layer):
"""
PEG
from https://arxiv.org/abs/2102.10882
"""
def __init__(self, in_chans, stride=1):
super().__init__() # depth conv
self.proj = nn.Conv2D(in_chans, in_chans, kernel_size=3, stride=stride, padding=1, bias_attr=True, groups=in_chans)
self.stride = stride def forward(self, x):
"""
x: [B, H, W, C]
"""
x_conv = x.transpose([0, 3, 1, 2]) if self.stride == 1:
x = self.proj(x_conv) + x_conv else:
x = self.proj(x_conv)
x = x.transpose([0, 2, 3, 1]) return x
2.3.3.7 Patch Embedding
class OverlapPatchEmbed(nn.Layer):
"""
Overlaped patch embedding, implemeted with 2D conv
"""
def __init__(self, in_chans=3, embed_dim=64, patch_size=7, stride=4, padding=2):
super().__init__()
self.proj = nn.Conv2D(in_chans, embed_dim, kernel_size=patch_size, stride=stride, padding=padding) def forward(self, x):
"""
x: [B, C, H, W]
return: [B, H, W, C]
"""
x = self.proj(x)
x = x.transpose([0, 2, 3, 1]) return x
2.3.3.8 ActiveMLP
class ActiveMLP(nn.Layer):
def __init__(
self,
img_size=224,
patch_size=4,
in_chans=3,
num_classes=1000,
depths=[2, 2, 4, 2],
embed_dims=[64, 128, 320, 512],
mlp_ratios=[4, 4, 4, 4],
share_dims=[1, 1, 1, 1], # how many channels share one offset
drop_path_rate=0.,
act_layer=nn.GELU,
norm_layer=nn.LayerNorm,
intv=2, # interval for generating new offset
):
super().__init__()
self.depths = depths
self.num_classes = num_classes
self.intv = intv
self.patch_embed = OverlapPatchEmbed(in_chans=3, embed_dim=embed_dims[0], patch_size=7, stride=4, padding=2)
dpr = [x.item() for x in paddle.linspace(0, drop_path_rate, sum(depths))]
ii = 0
self.blocks = nn.LayerList() for i in range(len(depths)):
_block = nn.LayerList([
ActiveBlock(embed_dims[i],
mlp_ratio=mlp_ratios[i],
drop_path=dpr[ii + j],
share_dim=share_dims[i],
act_layer=act_layer,
norm_layer=norm_layer,
downsample=Downsample(embed_dims[i], embed_dims[i + 1]) if i < len(depths) - 1 and j == depths[i] - 1 else None,
new_offset=(j % self.intv == 0 and j != depths[i] - 1),
) for j in range(depths[i])
])
self.blocks.append(_block)
ii += depths[i] # PEG for each resolution feature map
self.pos_blocks = nn.LayerList(
[PEG(ed) for ed in embed_dims]
)
self.norm = norm_layer(embed_dims[-1])
self.head = nn.Linear(embed_dims[-1], num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights) def _init_weights(self, m):
tn = nn.initializer.TruncatedNormal(std=.02)
ones = nn.initializer.Constant(1.0)
zeros = nn.initializer.Constant(0.0)
kaiming = nn.initializer.KaimingNormal() if isinstance(m, nn.Linear):
tn(m.weight) if m.bias is not None:
zeros(m.bias) elif isinstance(m, (nn.LayerNorm, nn.BatchNorm2D)):
zeros(m.bias)
ones(m.weight) elif isinstance(m, nn.Conv2D):
kaiming(m.weight) if m.bias is not None:
zeros(m.bias) def forward_blocks(self, x):
for i in range(len(self.depths)): for j, blk in enumerate(self.blocks[i]): if j % self.intv == 0 and j != len(self.blocks[i]) - 1: # generate new offset
x = self.pos_blocks[i](x)
x, offset = blk(x) else: # forward with old offset
x = blk(x, offset)
B, H, W, C = x.shape
x = x.reshape((B, -1, C)) return x def forward(self, x):
"""
x: [B, 3, H, W]
"""
x = self.patch_embed(x)
x = self.forward_blocks(x)
x = self.norm(x)
y = self.head(x.mean(1)) return y
num_classes = 10def ActivexTiny():
depths = [2, 2, 4, 2]
mlp_ratios = [4, 4, 4, 4]
embed_dims = [64, 128, 320, 512]
share_dims = [2, 4, 4, 8]
model = ActiveMLP(depths=depths, embed_dims=embed_dims, mlp_ratios=mlp_ratios, share_dims=share_dims, intv=2, num_classes=num_classes) return modeldef ActiveTiny():
depths = [2, 3, 10, 3]
mlp_ratios = [4, 4, 4, 4]
embed_dims = [64, 128, 320, 512]
share_dims = [2, 4, 4, 8]
model = ActiveMLP(depths=depths, embed_dims=embed_dims, mlp_ratios=mlp_ratios, share_dims=share_dims, intv=2, num_classes=num_classes) return modeldef ActiveSmall():
depths = [3, 4, 18, 3]
mlp_ratios = [8, 8, 4, 4]
embed_dims = [64, 128, 320, 512]
share_dims = [2, 4, 4, 8]
model = ActiveMLP(depths=depths, embed_dims=embed_dims, mlp_ratios=mlp_ratios, share_dims=share_dims, intv=6, num_classes=num_classes) return modeldef ActiveBase():
depths = [3, 8, 27, 3]
mlp_ratios = [8, 8, 4, 4]
embed_dims = [64, 128, 320, 512]
share_dims = [2, 4, 4, 8]
model = ActiveMLP(depths=depths, embed_dims=embed_dims, mlp_ratios=mlp_ratios, share_dims=share_dims, intv=6, num_classes=num_classes) return modeldef ActiveLarge():
depths = [3, 4, 24, 3]
mlp_ratios = [4, 4, 4, 4]
embed_dims = [96, 192, 384, 768]
share_dims = [2, 4, 4, 8]
model = ActiveMLP(depths=depths, embed_dims=embed_dims, mlp_ratios=mlp_ratios, share_dims=share_dims, intv=6, num_classes=num_classes) return model
2.3.4 模型的参数
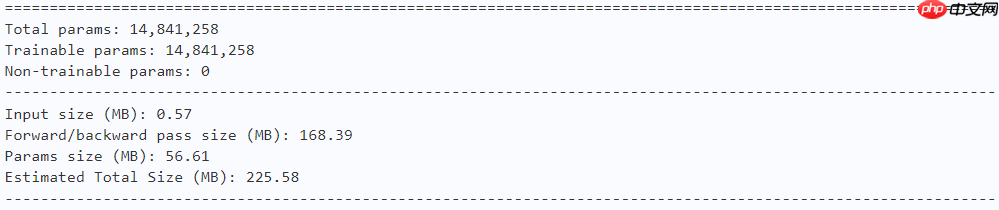
model = ActivexTiny() paddle.summary(model, (1, 3, 224, 224))
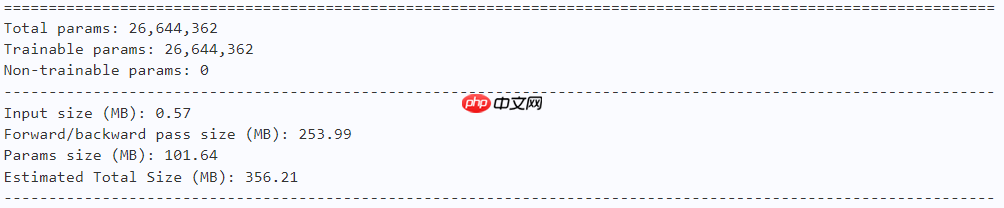
model = ActiveTiny() paddle.summary(model, (1, 3, 224, 224))
model = ActiveSmall() paddle.summary(model, (1, 3, 224, 224))
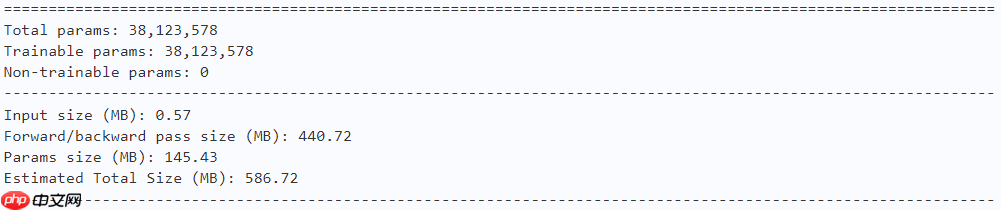
model = ActiveBase() paddle.summary(model, (1, 3, 224, 224))

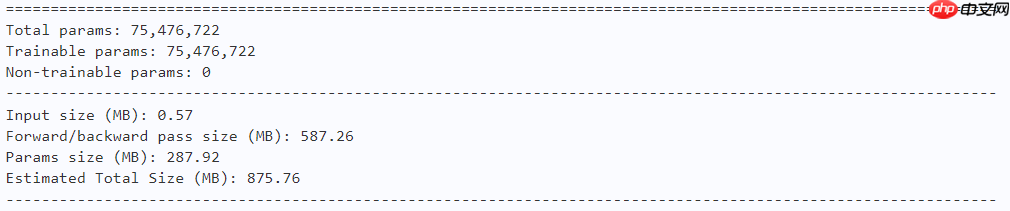
model = ActiveLarge() paddle.summary(model, (1, 3, 224, 224))
2.4 训练
learning_rate = 0.001n_epochs = 100paddle.seed(42) np.random.seed(42)
work_path = 'work/model'# ActiveMLP-xTinymodel = ActivexTiny()
criterion = LabelSmoothingCrossEntropy()
scheduler = paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=learning_rate, T_max=50000 // batch_size * n_epochs, verbose=False)
optimizer = paddle.optimizer.Adam(parameters=model.parameters(), learning_rate=scheduler, weight_decay=1e-5)
gate = 0.0threshold = 0.0best_acc = 0.0val_acc = 0.0loss_record = {'train': {'loss': [], 'iter': []}, 'val': {'loss': [], 'iter': []}} # for recording lossacc_record = {'train': {'acc': [], 'iter': []}, 'val': {'acc': [], 'iter': []}} # for recording accuracyloss_iter = 0acc_iter = 0for epoch in range(n_epochs): # ---------- Training ----------
model.train()
train_num = 0.0
train_loss = 0.0
val_num = 0.0
val_loss = 0.0
accuracy_manager = paddle.metric.Accuracy()
val_accuracy_manager = paddle.metric.Accuracy() print("#===epoch: {}, lr={:.10f}===#".format(epoch, optimizer.get_lr())) for batch_id, data in enumerate(train_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
logits = model(x_data)
loss = criterion(logits, y_data)
acc = accuracy_manager.compute(logits, labels)
accuracy_manager.update(acc) if batch_id % 10 == 0:
loss_record['train']['loss'].append(loss.numpy())
loss_record['train']['iter'].append(loss_iter)
loss_iter += 1
loss.backward()
optimizer.step()
scheduler.step()
optimizer.clear_grad()
train_loss += loss
train_num += len(y_data)
total_train_loss = (train_loss / train_num) * batch_size
train_acc = accuracy_manager.accumulate()
acc_record['train']['acc'].append(train_acc)
acc_record['train']['iter'].append(acc_iter)
acc_iter += 1
# Print the information.
print("#===epoch: {}, train loss is: {}, train acc is: {:2.2f}%===#".format(epoch, total_train_loss.numpy(), train_acc*100)) # ---------- Validation ----------
model.eval() for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1) with paddle.no_grad():
logits = model(x_data)
loss = criterion(logits, y_data)
acc = val_accuracy_manager.compute(logits, labels)
val_accuracy_manager.update(acc)
val_loss += loss
val_num += len(y_data)
total_val_loss = (val_loss / val_num) * batch_size
loss_record['val']['loss'].append(total_val_loss.numpy())
loss_record['val']['iter'].append(loss_iter)
val_acc = val_accuracy_manager.accumulate()
acc_record['val']['acc'].append(val_acc)
acc_record['val']['iter'].append(acc_iter) print("#===epoch: {}, val loss is: {}, val acc is: {:2.2f}%===#".format(epoch, total_val_loss.numpy(), val_acc*100)) # ===================save====================
if val_acc > best_acc:
best_acc = val_acc
paddle.save(model.state_dict(), os.path.join(work_path, 'best_model.pdparams'))
paddle.save(optimizer.state_dict(), os.path.join(work_path, 'best_optimizer.pdopt'))print(best_acc)
paddle.save(model.state_dict(), os.path.join(work_path, 'final_model.pdparams'))
paddle.save(optimizer.state_dict(), os.path.join(work_path, 'final_optimizer.pdopt'))
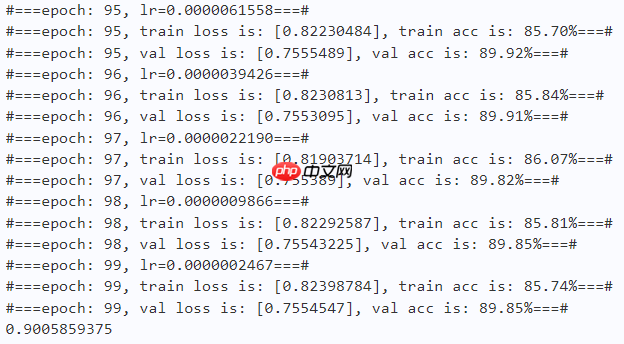
2.5 结果分析
def plot_learning_curve(record, title='loss', ylabel='CE Loss'):
''' Plot learning curve of your CNN '''
maxtrain = max(map(float, record['train'][title]))
maxval = max(map(float, record['val'][title]))
ymax = max(maxtrain, maxval) * 1.1
mintrain = min(map(float, record['train'][title]))
minval = min(map(float, record['val'][title]))
ymin = min(mintrain, minval) * 0.9
total_steps = len(record['train'][title])
x_1 = list(map(int, record['train']['iter']))
x_2 = list(map(int, record['val']['iter']))
figure(figsize=(10, 6))
plt.plot(x_1, record['train'][title], c='tab:red', label='train')
plt.plot(x_2, record['val'][title], c='tab:cyan', label='val')
plt.ylim(ymin, ymax)
plt.xlabel('Training steps')
plt.ylabel(ylabel)
plt.title('Learning curve of {}'.format(title))
plt.legend()
plt.show()
plot_learning_curve(loss_record, title='loss', ylabel='CE Loss')
plot_learning_curve(acc_record, title='acc', ylabel='Accuracy')
import time
work_path = 'work/model'model = ActivexTiny()
model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams'))
model.set_state_dict(model_state_dict)
model.eval()
aa = time.time()for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1) with paddle.no_grad():
logits = model(x_data)
bb = time.time()print("Throughout:{}".format(int(len(val_dataset)//(bb - aa))))
Throughout:615
def get_cifar10_labels(labels):
"""返回CIFAR10数据集的文本标签。"""
text_labels = [ 'airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck'] return [text_labels[int(i)] for i in labels]
def show_images(imgs, num_rows, num_cols, pred=None, gt=None, scale=1.5):
"""Plot a list of images."""
figsize = (num_cols * scale, num_rows * scale)
_, axes = plt.subplots(num_rows, num_cols, figsize=figsize)
axes = axes.flatten() for i, (ax, img) in enumerate(zip(axes, imgs)): if paddle.is_tensor(img):
ax.imshow(img.numpy()) else:
ax.imshow(img)
ax.axes.get_xaxis().set_visible(False)
ax.axes.get_yaxis().set_visible(False) if pred or gt:
ax.set_title("pt: " + pred[i] + "\ngt: " + gt[i]) return axes
work_path = 'work/model'X, y = next(iter(DataLoader(val_dataset, batch_size=18))) model = ActivexTiny() model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams')) model.set_state_dict(model_state_dict) model.eval() logits = model(X) y_pred = paddle.argmax(logits, -1) X = paddle.transpose(X, [0, 2, 3, 1]) axes = show_images(X.reshape((18, 224, 224, 3)), 1, 18, pred=get_cifar10_labels(y_pred), gt=get_cifar10_labels(y)) plt.show()
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).




























