该论文提出PAN网络,以ResNet-18为骨干,结合FPEM、FFM和像素聚合法,平衡场景文本检测的精度与速度。基于Paddle的复现项目,部分数据集F-measure达81.46%,超验收标准。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

Wenhai Wang, Enze Xie, Xiaoge Song, Yuhang Zang, Wenjia Wang, Tong Lu, Gang Yu, Chunhua Shen
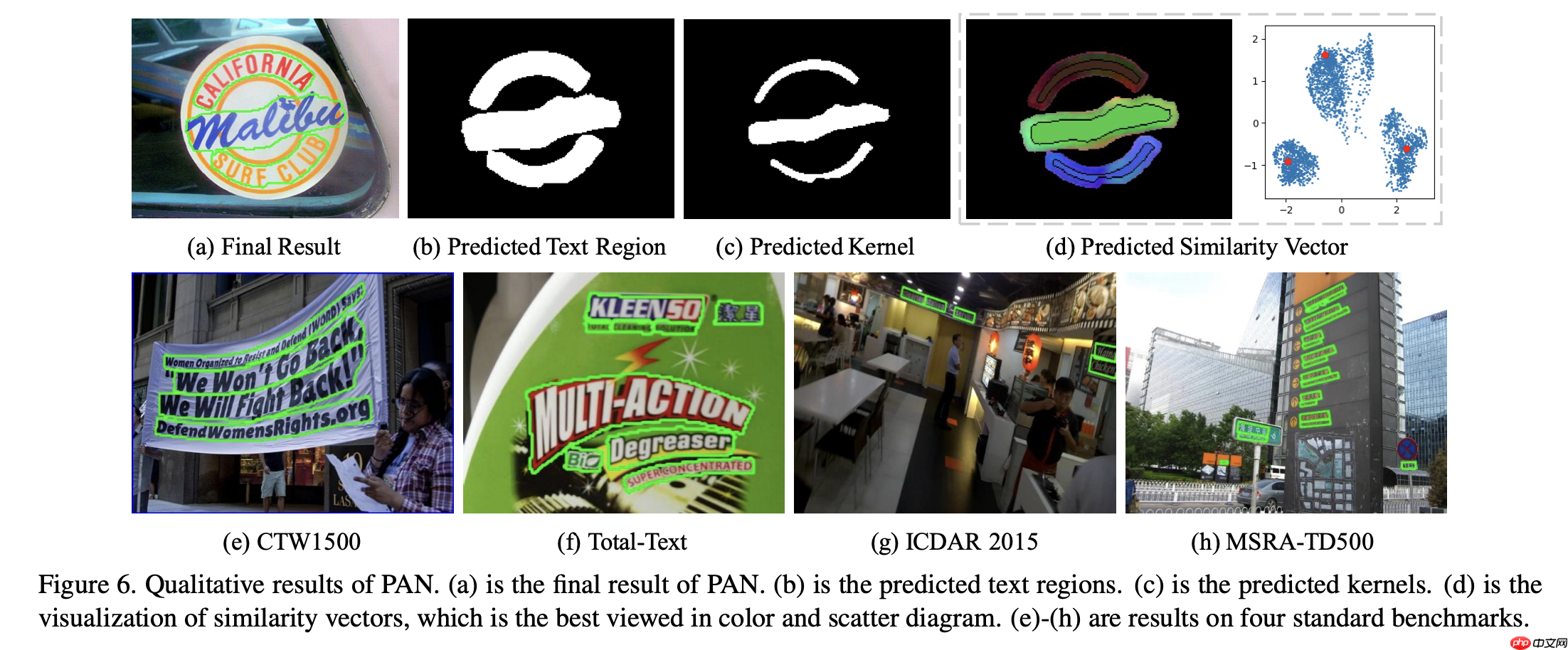
场景文本检测是场景文本阅读系统的重要一步,随着卷积神经网络的快速发展,场景文字检测也取得了巨大的进步。尽管如此,仍存在两个主要挑战,它们阻碍文字检测部署到现实世界的应用中。第一个问题是速度和准确性之间的平衡。第二个是对任意形状的文本实例进行建模。最近,已经提出了一些方法来处理任意形状的文本检测,但是它们很少去考虑算法的运行时间和效率,这可能在实际应用环境中受到限制。
之前在CVPR 2019上发的PSENet是效果非常好的文本检测算法,处理速度很快,准确度很高,但后处理过程繁琐,而且没办法和网络模型融合在一起,实现训练,导致其整体运行速度很慢。于是PSENet算法的原班作者提出了PAN网络,使其在不损失精度的情况下,极大加快了网络inference的速度,因此也可以把PAN看做是PSENet V2版本。
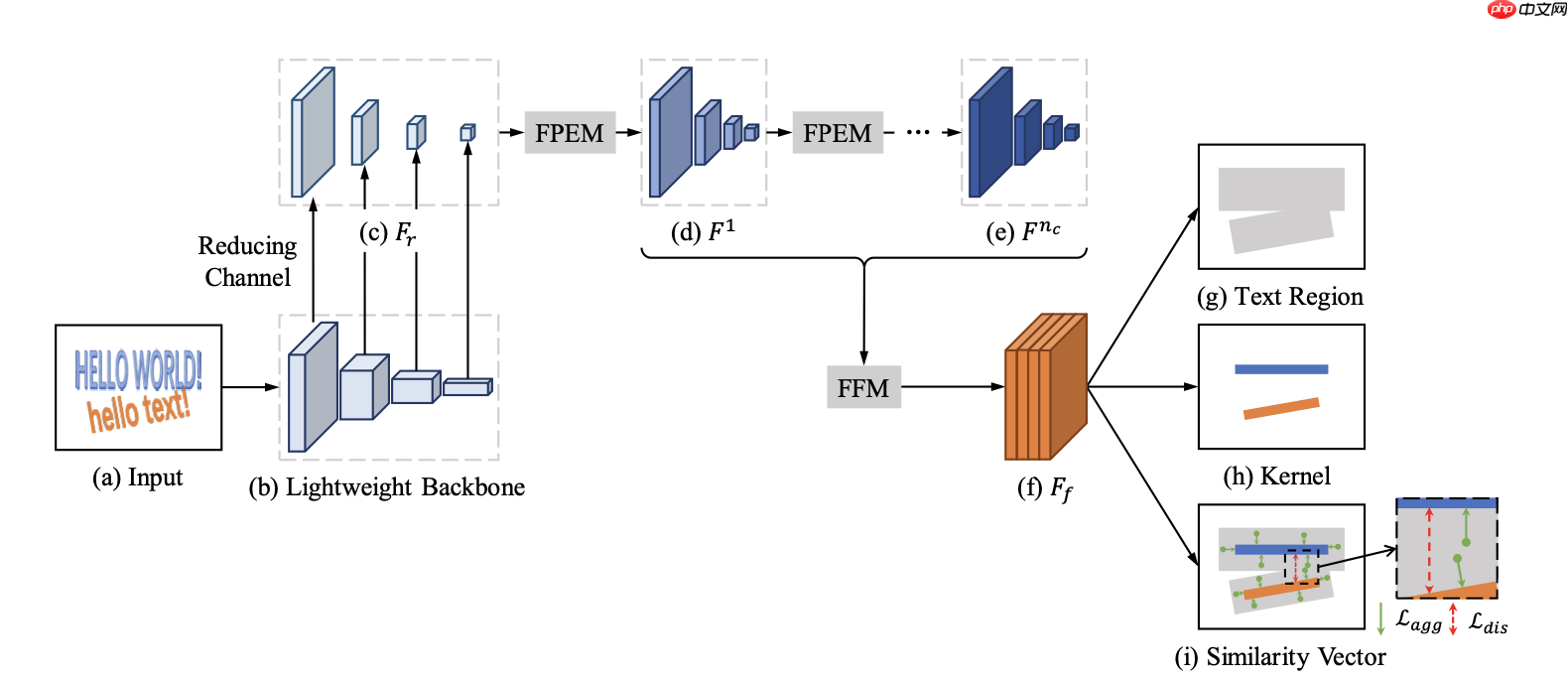
上图为PAN的整个网络结构,网络主要由Backbone + Segmentation Head(FPEM + FFM) + Output(Text Region、Kernel、Similarity Vector)组成。
本文使用ResNet-18作为PAN的默认Backbone,并提出了低计算量的Segmentation Head(FPFE + FFM)以解决因为使用ResNet-18而导致的特征提取能力较弱,特征感受野较小且表征能力不足的缺点。
此外,为了精准地重建完整的文字实例(text instance),提出了一个可学习的后处理方法——像素聚合法(PA),它能够通过预测出的相似向量来引导文字像素聚合到正确的kernel上去。
下面将详细介绍一下上面的各个部分。
Backbone选择的是resnet18, 提取stride为4,8,16,32的conv2,conv3,conv4,conv5的输出作为高低层特征。每层的特征图的通道数都使用1*1卷积降维至128得到轻量级的特征图Fr。
PAN使用resNet-18作为网络的默认backbone,虽减少了计算量,但是backbone层数的减少势必会带来模型学习能力的下降。为了提高效率,作者在 resNet-18基础上提出了一个低计算量但可高效增强特征的分割头Segmentation Head。它由两个关键模块组成:特征金字塔增强模块(Feature Pyramid Enhancement Module,FPEM)、特征融合模块(Feature Fusion Module,FFM)。
Feature Pyramid Enhancement Module(FPEM),即特征金字塔增强模块。FPEM呈级联结构且计算量小,可以连接在backbone后面让不同尺寸的特征更深、更具表征能力,结构如下:
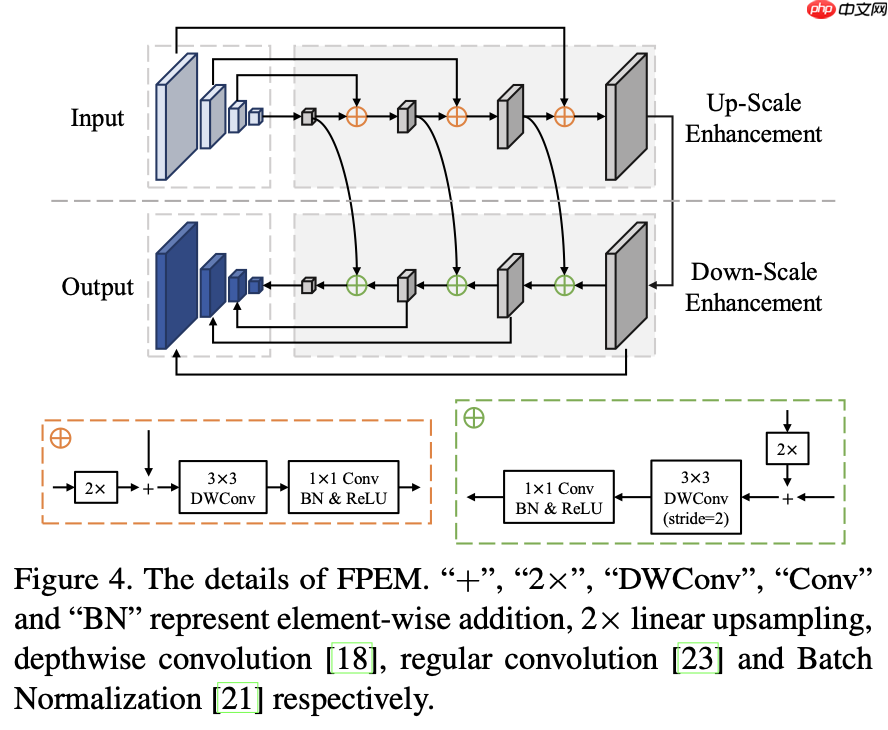
FPEM是一个U形模组,由两个阶段组成,up-scale增强、down-scale增强。up-scale增强作用于输入的特征金字塔,它以步长32,16,8,4像素在特征图上迭代增强。在down-scale阶段,输入的是由up-scale增强生成的特征金字塔,增强的步长从4到32,同时,down-scale增强输出的的特征金字塔就是最终FPEM的输出。 FPEM模块可以看成是一个轻量级的FPN,只不过这个FPEM计算量不大,可以不停级联以达到不停增强特征的作用。
Feature Fusion Module(FFM)模块用于融合不同尺度的特征,其结构如下:

最后通过上采样将它们Concatenate到一起。
模型最后预测三种信息: 1、文字区域 2、文字kernel 3、文字kernel的相似向量
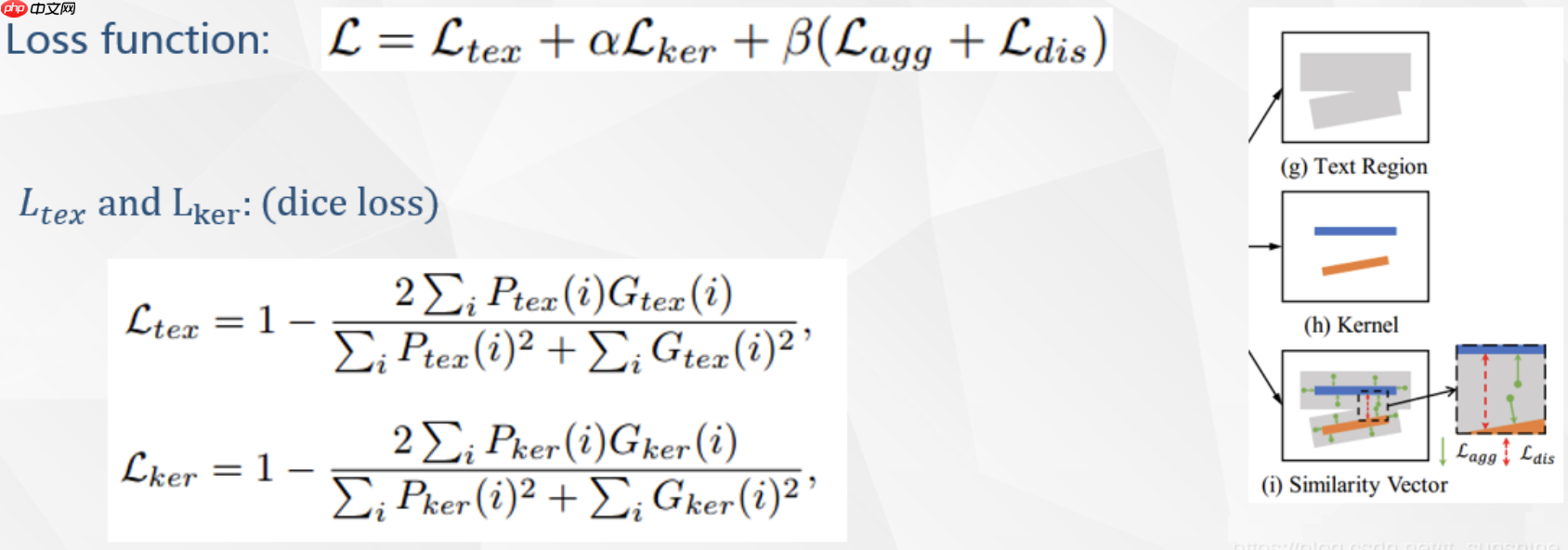
总的loss如上,其中Ltex和Lker分别是文本实例和kernel的分割loss,Lagg是衡量文本实例和其对应kernel的loss,Ldis是不同文本实例的kernel的loss。α和β是平衡各个loss的值,设为0.5和0.25。
如上图所示,Ltex和Lker的公式和psenet一致,使用dice loss。论文的重点在于Lagg和Ldis,下面分别描述。

Lagg用于衡量文本实例和其对应kernel的loss,其作用是保证同一文本实例的kernel和文本实例内其他像素点之间的距离小于δagg。
其中,N是图像中文本实例的数量,Ti表示第i个文本实例,Ki是文本实例对应的kernel。D(p,ki)定义的了文本实例Ti内的像素p和 Ki之间的距离。δagg是一个常量,默认0.5,Fp是网络在像素p处输出的相似度向量,G(.)是Ki的相似度向量。
G(.)的计算就是对于Ki里的每一个像素q,网络在像素q处输出的相似度向量Ki的像素点数量,∣Ki∣指Ki的L1范数,这里代表的就是Ki里像素点的数量。
D(p,ki)里的∣∣F(p)−G(Ki)∣∣表示F(p)−G(Ki)的L2范数,是一个用于衡量像素点到Ki距离的值,值越小表示相似度越大,公式中距离小于 δagg的像素点就没必要参与loss计算了,关注那些距离远的值即可。
支持模板化设计,基于标签调用数据 支持N国语言,并能根据客户端自动识别当前语言 支持扩展现有的分类类型,并可修改当前主要分类的字段 支持静态化和伪静态 会员管理功能,询价、订单、收藏、短消息功能 基于组的管理员权限设置 支持在线新建、修改、删除模板 支持在线管理上传文件 使用最新的CKEditor作为后台可视化编辑器 支持无限级分类及分类的移动、合并、排序 专题管理、自定义模块管理 支持缩略图和图
 0
0


Ldis用于是不同文本实例的kernel的loss,其作用是保证任意两个kernel之间的距离> δdis。即对于每一个文本实例kernel,分别计算和其他kernel的距离,公式如上所示。
其中,δdis是一个常量,默认3。当两个kernel之间的距离∣∣G(Ki)−G(Kj)∣∣> δdis时,就表示这两个kernel的距离已经足够远了。
另外,在训练过程中,Ltex的计算使用的OHEM,正负像素之比是1:3,计算Lker,Lagg和Ldis时均只考虑ground truth内的文本像素。
项目为百度飞桨起航菁英计划团队赛中复现的论文。项目基于 Paddle 2.1.2 与 Python 3.7 进行开发并实现论文精度,十分感谢百度提供比赛平台和 GPU 资源!
正所谓“磨刀不误砍柴工”,复现论文前,如果对论文的整体结构有所把握,接下来的复现过程中可能会省力很多。以复现PANet为例,当了解到PANet是PSENet的改进后,我们学习参考了PSENet的复现,少走了不少弯路。此外,PaddlePaddle与Pytorch的函数并非完全对应,有部分函数需要自己实现。在了解了论文细节后,实现函数能够更加轻松。
在复现过程中,主要参考PaddlePaddle的API文档与Pytorch的API文档,需要耐心与细心。比如PaddlePaddle中Softmax包含参数axis,而Pytorch中Softmax对应参数为dim。
除此以外,遵循PaddlePaddle官方提供的论文复现步骤,可以及时找到问题所在环节,减少后期的debug的时间,提升论文复现效率。
论文复现指南
Paddle API 文档
PyTorch-PaddlePaddle API映射表
数据集推荐按照$Paddle-PANet-main/data进行设置。如果您的文件结构不同,则可能需要修改dataloader中相应的内容。
Paddle-PANet-main
└── data
└── CTW1500
├── train
│ ├── text_image
│ └── text_label_curve
└── test
├── text_image
└── text_label_curve!mkdir Paddle-PANet-main/data !unzip -q /home/aistudio/data/data113487/ctw1500.zip -d Paddle-PANet-main/data
下载resent18预训练模型:pretrain_resnet18
密码: j5g3
在正式开始训练前,请将resnet18预训练模型放置到$Paddle-PANet-main/pretrained/文件夹下。如果不使用预训练模型,则需要修改config中的设置。
!mkdir Paddle-PANet-main/pretrained !mv /home/aistudio/data/data113510/resnet18.pdparams Paddle-PANet-main/pretrained
Python 3.6+paddlepaddle-gpu 2.0.2nccl 2.0+mmcv 0.2.12editdistancePolygon3pyclipperopencv-python 3.4.2.17Cython
项目的环境准备、启动命令已经写入train.sh中,执行train.sh即可完成环境所需依赖的安装,并启动训练。
%cd Paddle-PANet-main/ sh train.sh
如果需要恢复训练,则执行如下命令:
python train.py ${CONFIG_FILE} --resume ${CHECKPOINTS_STORE_PATH}例如:
python train.py config/pan/pan_r18_ctw_train.py --resume checkpoints/pan_r18_ctw_train
CTW数据集地址:CTW 执行test.sh进行评估,评估结束后生成res.txt,存储模型的评估结果。
sh test.sh
| Method | Backbone | Fine-tuning | Config | Precision (%) | Recall (%) | F-measure (%) | Model | Log |
|---|---|---|---|---|---|---|---|---|
| mmocr_PANet | Resnet18 | N | ctw_config | 77.6 | 83.8 | 80.6 | -- | -- |
| PAN (paper) | ResNet18 | N | config | 84.6 | 77.7 | 81.0 | - | - |
| PaddlePaddle_PANet | ResNet18 | N | panet_r18_ctw.py | 84.51 | 78.62 | 81.46 | Model | Log |
从第500轮开始,每十轮保存一次模型。最终根据F-measure选择了第570轮保存的模型参数,F-measure为81.46,超过验收标准80.6。
以上就是文字识别:基于PaddlePaddle复现PANet的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号





 903
903























