本文介绍了2017-2021年深度学习在端到端文本识别的代表性方法,分端到端规则文本识别与任意形状文本识别两类。前者如FOTS、TextSpotter,解决平直或倾斜文本问题;后者如Mask TextSpotter系列、ABCNet等,可处理弯曲等任意形状文本,还总结了各类算法的结构与效果。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

OCR算法可以分为两阶段算法和端到端的算法。两阶段OCR算法一般分为两个部分,文本检测和识别算法,文本检测算法从图像中得到文本行的检测框,然后识别算法识别文本框中的内容。端对端OCR算法使用一个模型同时完成文字检测和文字识别,其基本思想是共享同一个Backbone网络,并设计不同的检测模块和识别模块,可以同时训练文本检测和文本识别。由于一个模型即可完成文字识别,因此端对端模型更小,速度更快。
在本节中,将介绍近几年来深度学习技术在端到端文本识别方向具有代表性的方法。这些方法大致可以分为两类:
1)端到端规则文本识别;
2)端到端任意形状文本识别。
端到端规则文本识别主要是解决平直文或着倾斜文本的检测和识别,然而弯曲、变形等文本在自然场景中大量出现,如印章等,在检测和识别这些文本需要使用端到端任意形状文本识别算法,与此同时这些算法也可以检测和识别平直和倾斜的文本。
本节筛选了2017~2021年一些具有代表性的端到端识别方法,按照如上两类方法分类如下表格所示。
| 类别 | 主要论文 |
|---|---|
| 端到端规则文本识别 | FOTS、TextSpotter |
| 端到端任意形状文本识别 | Mask TextSpotterv1、Mask TextSpotter2、Mask TextSpotterv3、TextDragon、CharNet、TUTS、ABCNet、ABCNetV2、Text Perceptron、PGNet、PAN++ |
注:表格中文章统计或有遗漏,如有疑问,请在链接中联系我们
Xuebo Liu和Ding Liang等人(2018)[1]提出了一种端到端可训练的算法FOTS(Fast Oriented Text Spotting),同时进行文本检测和识别,其网络结构如 图1 所示。FOTS算法由四个部分组成:共享卷积、文本检测分支、ROIRotate操作和文本识别分支。
1)首先使用共享卷积(shared convolutions)提取特征图,通过共享卷积特征,网络可以以很小的计算开销同时检测和识别文本,从而达到实时速度;
2)然后在提取的特征图基础上,构建基于全卷积神经网络(fully convolutional network,FCN)的文本检测分支,用于预测文本检测框;
3)接着使用RoIRotate算法从特征图中提取与检测结果对应的文本候选特征,该操作将文本检测和识别统一到端到端的训练流程中;
4)最后将文本候选特征输入到递归神经网络(Recurrent Neural Network,RNN)编码器和连接时序分类(Connectionist Temporal Classification,CTC)解码器中,进行文本识别。
由于网络中的所有模块都是可微的,因此整个模型可以进行端到端的训练,且不需要复杂的后处理和超参数调整。

为了验证FOTS方法的有效性,作者在ICDAR 2015、ICDAR 2017 MLT和ICDAR 2013数据集上进行实验,可视化结果如 图2 所示。

注:由于ICDAR 2017 MLT没有文本识别任务,只显示了文本检测结果。
Tong He等人(2018)[2]提出了一种简单有效的模型TextSpotter,网络结构如 图3 所示。TextSpotter检测分支使用PVANet模型作为backbone,识别分支使用RNN模型,该模型将检测和识别统一到一个网络中进行训练。RNN分支由本文提出的text-aligment层和LSTM组成,其中text-aligment层通过引入网格采样来代替RoI池化层,它计算固定长度的卷积特征,这些特征能够精确地对齐检测到的任意方向的文本区域。还引入字符注意力机制,使用字符的空间信息作为额外的监督,使RNN在解码时聚焦于当前的注意力特征。最后提出了一种学习策略,它允许两个任务共享卷积特征来有效地训练模型。
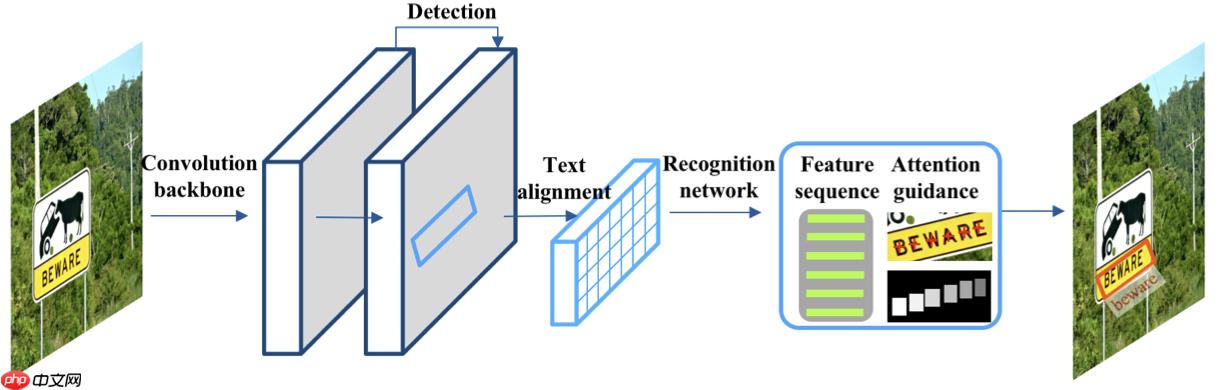
为了验证TextSpotter方法的有效性,作者在ICDAR2013和ICDAR2015数据集上进行实验,可视化结果如 图4 所示。

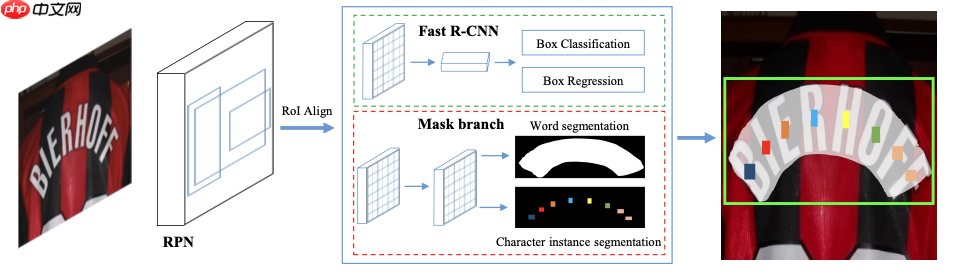
Pengyuan Lyu和Minghui Liao等人(2018)[3]提出了一种端到端可训练的场景文本识别模型Mask TextSpotter。相比于一些只能定位水平文本(图5左)或多方向文本的算法(图5中),它可以检测和识别任意形状(水平、多方向、弯曲)的文本(图5右):

受Mask R-CNN的启发,Mask TextSpotter通过语义分割解决文本检测问题,使其能够检测任意形状的文本。同时通过基于字符的语义分割来识别文本,以解决阅读不规则文本的问题。Mask TextSpotter网络结构如 图6 所示。
为了验证Mask TextSpotter方法的有效性,作者在ICDAR2013、ICDAR2015和Total-Text数据集上进行实验,数据集上可视化结果如 图7 所示。

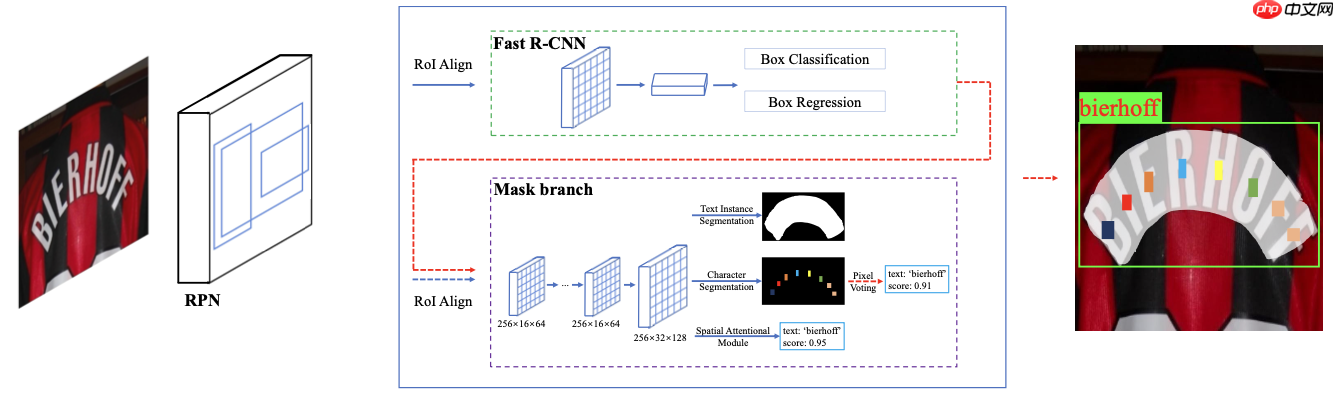
Minghui Liao等人(2019)[4]在Mask TextSpotter基础上提出了Mask TextSpotter V2。Mask TextSpotter对单字符进行识别,训练时需要字符的位置以及通过后处理将字符组合为最终文本识别结果。为了缓解上述问题,Mask TextSpotter V2提出了空间注意力机制(spatial attention module,SAM)。文本识别部分利用SAM预测文本序列,且在训练时只需要单词级的标注,这大大减少了训练时对字符级标注的需求。Mask TextSpotter V2网络结构如 图8 所示。
为了验证Mask TextSpotter V2方法的有效性,作者在ICDAR2013、ICDAR2015、COCO-Text、Total-Text、MIT 5个数据集上进行实验。在ICDAR 2013(第一列)、ICDAR 2015(第二列)和Total-Text(最后两列)数据集上可视化结果如 图9 所示。

Minghui Liao等人(2020)[5]又在Mask TextSpotter V1和V2两个版本的基础提出了Mask TextSpotter V3,前两个版本都是基于Mask R-CNN进行文本检测,受RPN的限制,它们检测长文本效果不好。作者在V3中不再使用RPN,而是采用Segmentation Proposal Network(SPN),克服了极端长宽比、不规则形状文本识别的局限性。同时作者提出了hard RoI masking,能够有效地抑制背景噪声或相近文本实例。Mask TextSpotter V3网络结构如 图10 所示。

为了验证Mask TextSpotter V3方法的有效性,作者在Rotated ICDAR 2013、Total-Text和MSRA-TD500数据集上进行实验,在Total-Text数据集上可视化结果如 图11 所示,只有不准确的识别结果才会被可视化。

Wei Feng等人(2019)[6]提出了一个新颖的文本定位框架TextDragon,仅使用字/行级注释进行训练,网络结构如 图12 所示。在TextDragon中,设计了一个文本检测器,通过一系列四边形来描述文本的形状,从而处理任意形状的文本。为了从特征图中提取任意文本区域,TextDragon设计了一种新的可微算子RoISlide,它将任意形状的文本检测和识别模块统一到端到端的系统中。在RoISlide提取特征的基础上,TextDragon引入了一种基于卷积神经网络(CNN)和连接时序分类(CTC)的文本识别器,生成最终识别的结果,使框架不需要标注字符的位置,只需要标注字/行级注释,提高了模型的实用性。
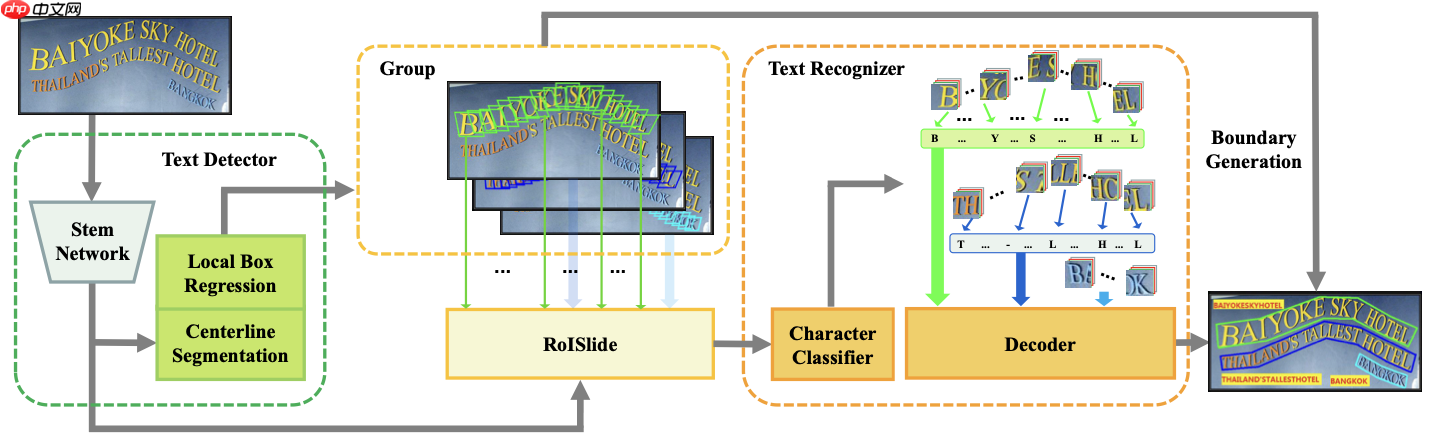
为了验证TextDragon方法的有效性,作者在两种曲面文本基准CTW1500和Total-Tex数据集、以及ICDAR 2015数据集上进行实验,可视化结果如 图13 所示。

Linjie Xing等人(2019)[7]提出了卷积字符网络(Convolutional Character Networks,CharNet),用于端到端的文字检测与识别,其网络结构如 图14 所示。CharNet引入新的字符检测和识别的分支,这个分支可以被无缝整合进当前的文本检测模型中。作者还将单个字符作为基本单元,能够避免RoI Pooling以及RNN识别模块带来影响,这两个因素是当前两阶段模型的主要局限性。此外,论文中还提出了一种迭代字符的检测方法,该方法使得CharNet能够把从合成数据学习到的字符检测能力迁移到真实数据上,从而生成真实数据上的字符标注。这使得在真实图像上训练CharNet成为可能,而不需要额外字符级的框标注。
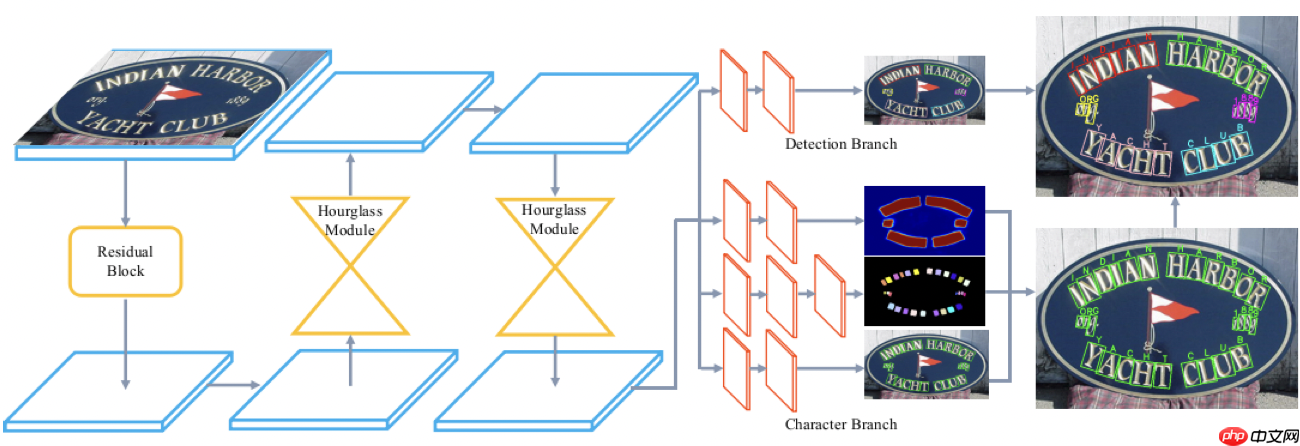
为了验证CharNet方法的有效性,作者在基准数据集ICDAR2015、Total-Text和ICDAR MLT 2017上进行实验,可视化结果如 图15 所示。

Siyang Qin等人(2019)[8]提出了一种端到端可训练的模型TUTS,其网络结构如 图16 所示。TUTS是一种简单灵活的基于Mask R-CNN检测器和seq2seq注意力解码器的OCR模型,能够检测和识别任意形状的文本。该方法提出了一种简单有效的RoI masking机制,目的是从图像尺度特征(image scale features)获取有用的不规则文本特征。此外,从现有多阶段OCR引擎的预测结果获取半标注的训练数据,能够大大提升了模型检测和识别效果。
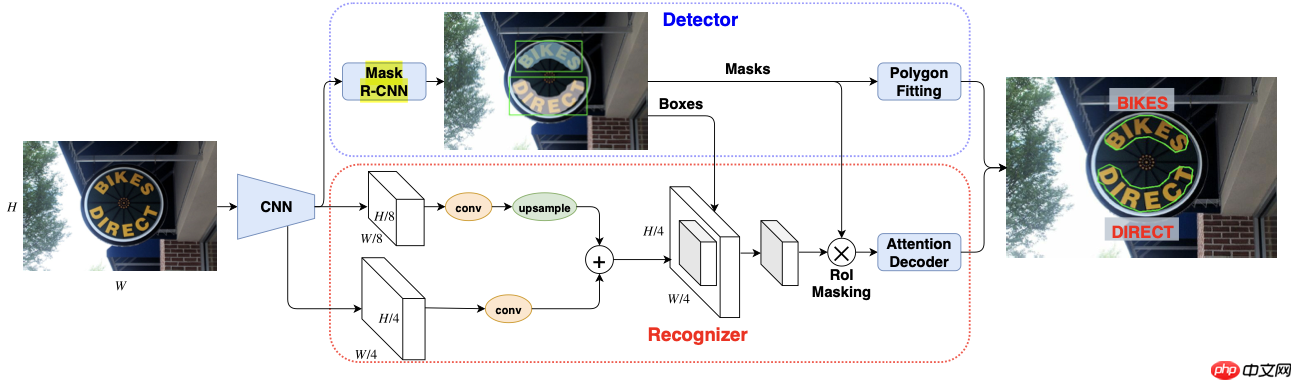
为了验证TUTS方法的有效性,作者在基准数据集ICDAR2015、Total-Text上进行实验,可视化结果如 图17 所示,左边两列为ICDAR2015结果,右边两列为Total-Text结果。

其中,右下角图片中的蓝色表示预测错误的文字。
Yuliang Liu等人(2020)[9]提出了端到端可训练任意形状文本的模型自适应贝塞尔曲线网络(Adaptive Bezier-Curve Network,ABCNet),网络结构如 图18 所示。作者首次使用参数化的贝塞尔曲线自适应拟合任意形状的文本;同时设计了一种新颖的BezierAlign层,用于精准地提取任意形状文本的卷积特征;与之前标准的检测方法相比,所提出的贝塞尔曲线检测方法引入的计算开销可忽略不计;最后通过共享主干特征,可以将识别分支设计为轻量结构。ABCNet分为两个部分:1)Bezier曲线检测; 2)Bezier-Align和识别分支,网络结构在效率和精度上都有优势。
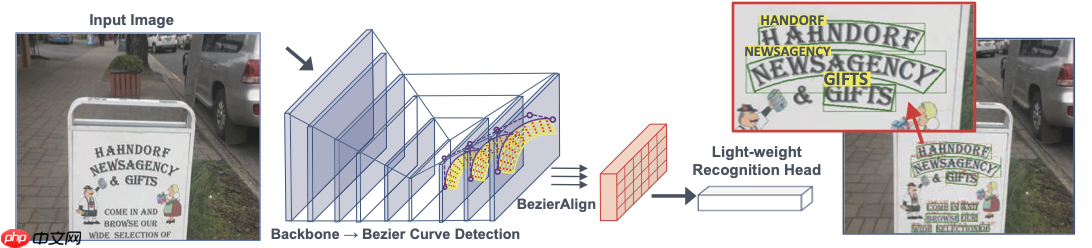
为了验证ABCNet方法的有效性,作者在任意形状的基准数据集Total-Text和CTW1500上进行实验,在Total-Text数据集上的可视化结果如 图19 所示。

Yuliang Liu等人(2021)[10]在ABCNet的基础上提出了ABCNet v2,在四个方面进行了改进:特征提取器、检测分支、识别分支和端到端训练,在保持非常高的效率的同时实现最先进的性能。ABCNet v2的检测模型通过考虑双向多尺度金字塔全局文本特征,使得在处理多尺度文本时更加通用。作者观察到检测分支中的特征对齐对后续文本识别至关重要,因此提出了一种坐标卷积来对卷积滤波器的位置进行编码,大大提高了精度,而计算开销却可以忽略。在识别分支,集成了一个字符注意力模块,该模块可以递归地预测每个单词的字符,从而不需要使用字符级注释。最后为了实现有效的端到端训练,作者进一步提出了自适应端到端训练(Adaptive end-to-end training,AET)来匹配端到端训练的检测。ABCNet v2网络结构如 图20 所示。

为了验证ABCNet v2方法的有效性,作者在ICDAR 2015、MSRA-TD500、ReCTS、Total-Text和SCUT-CTW1500,部分可视化结果如 图21 所示。

Liang Qiao等人(2020)[11]提出了一种端到端可训练任意形状的文本识别方法Text Perceptron,其网络结构如 图22 所示。Text Perceptron包含三个部分:1)基于分割的高效检测模块,采用ResNet和FPN作为骨干网络,它将文本区域描述为四个子区域:中心区域、头部、尾部、顶部和底部边界区域。边界信息不仅有助于区分距离非常近的文本区域,而且有助于学习潜在的阅读顺序;2)设计了一种新颖的Shape Transform Module (STM)模块,将检测到的特征区域转换为规则的无附加参数的形式,致力于通过端到端可训练的方式优化检测和识别;3)基于序列的识别模块,用于最终生成字符序列。
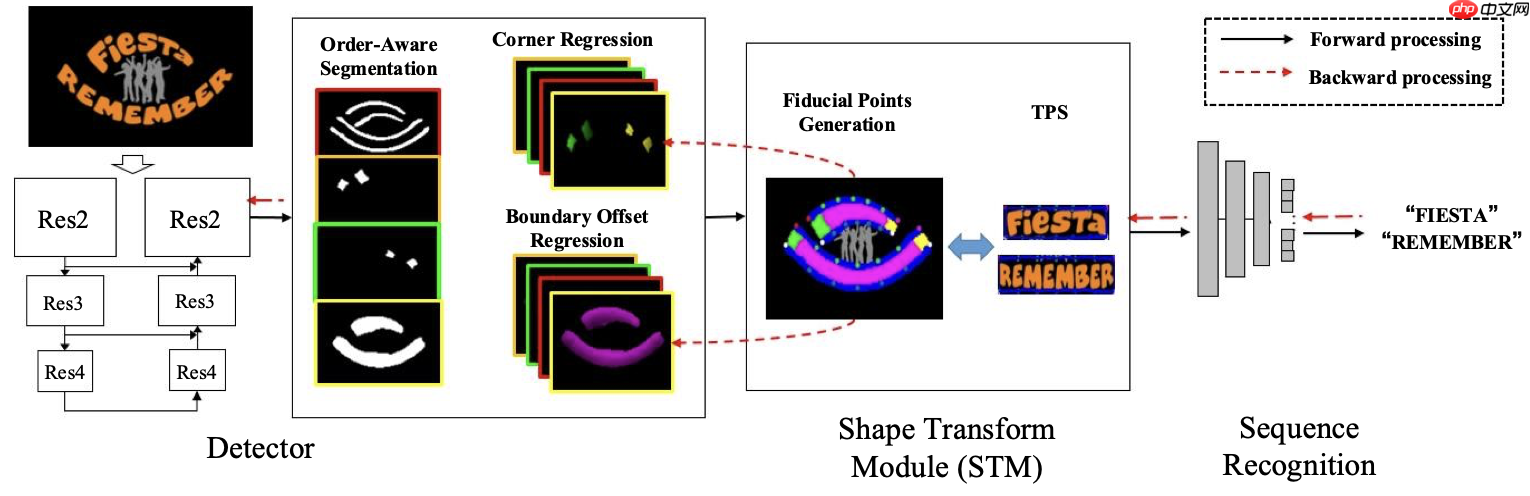
为了验证Text Perceptron方法的有效性,作者在SynthText 800k 、ICDAR2013、ICDAR2015、Total-Text和CTW1500上进行实验,在Total-Text和CTW1500数据集上的可视化结果如 图23 所示。
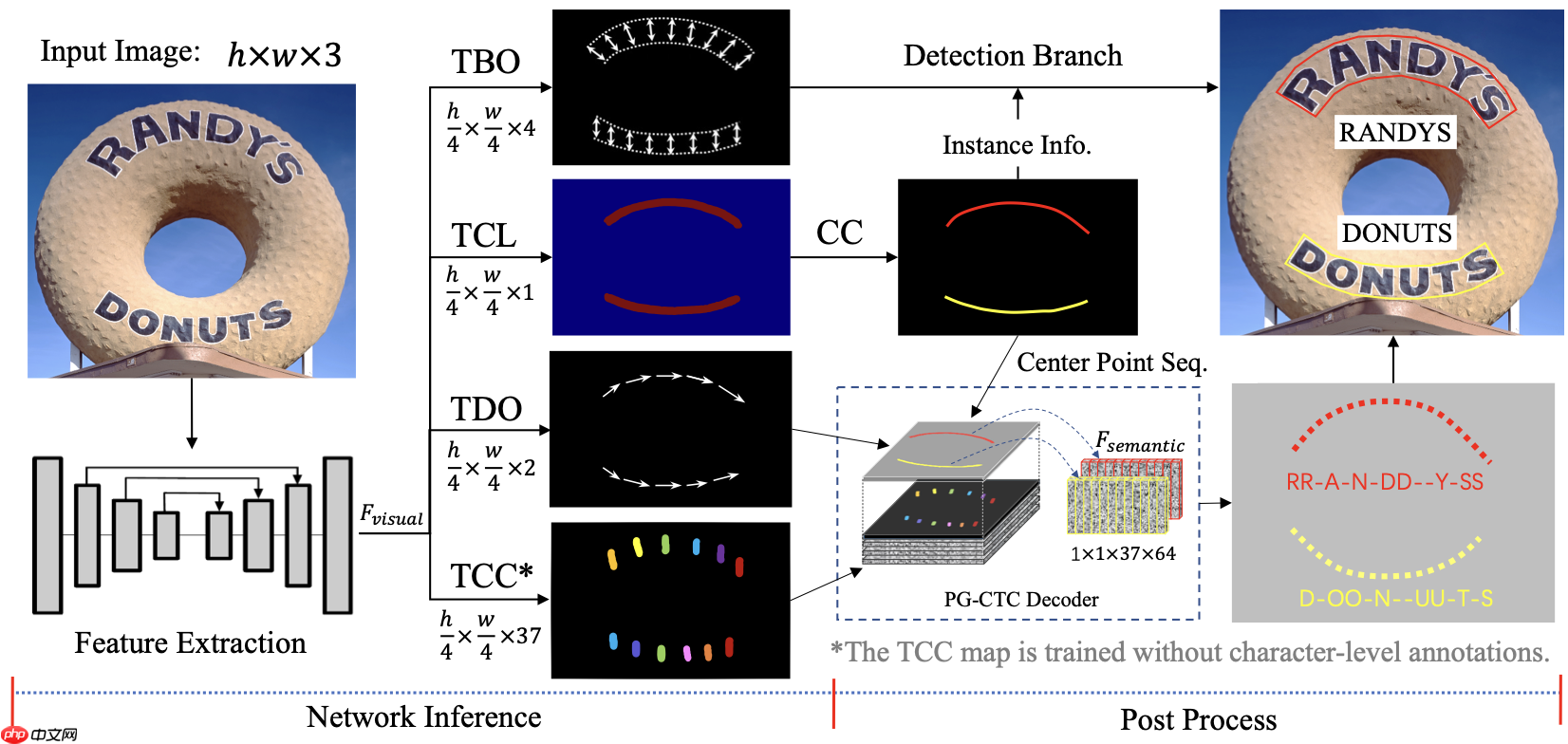
Pengfei Wang等人(2021)[12]提出了一种全卷积Point Gathering Network (PGNet)模型,其网络结构如 图24 所示。PGNet模型输入图像经过特征提取送入四个分支,分别是:文本边缘偏移量预测TBO模块、文本中心线预测TCL模块、文本方向偏移量预测TDO模块以及文本字符分类图预测TCC模块。 其中TBO以及TCL的输出经过后处理后可以得到文本的检测结果,TCL、TDO、TCC负责文本识别。PGNet算法具备其他算法不具备的优势,包括:设计PGNet loss指导训练,不需要字符级别的标注;不需要NMS和ROI相关操作,加速预测;提出预测文本行内的阅读顺序模块;提出基于图的修正模块(GRM)来进一步提高模型识别性能;精度更高,预测速度更快。
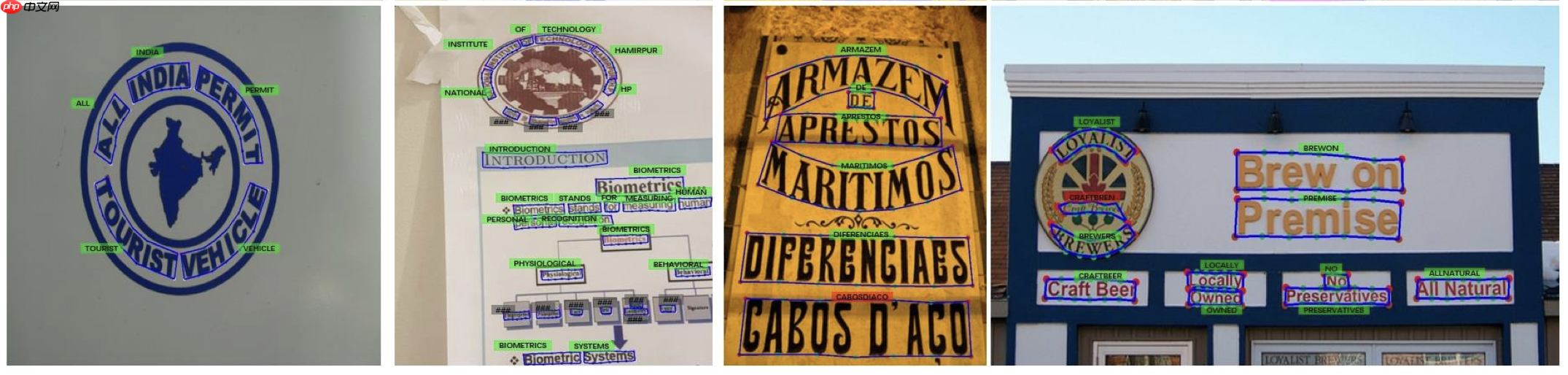
为了验证PGNet方法的有效性,作者在ICDAR2015和Total-Text数据集上进行实验,可视化结果如 图25 所示,左边两列为Total-Text结果,右边两列为ICDAR2015结果。

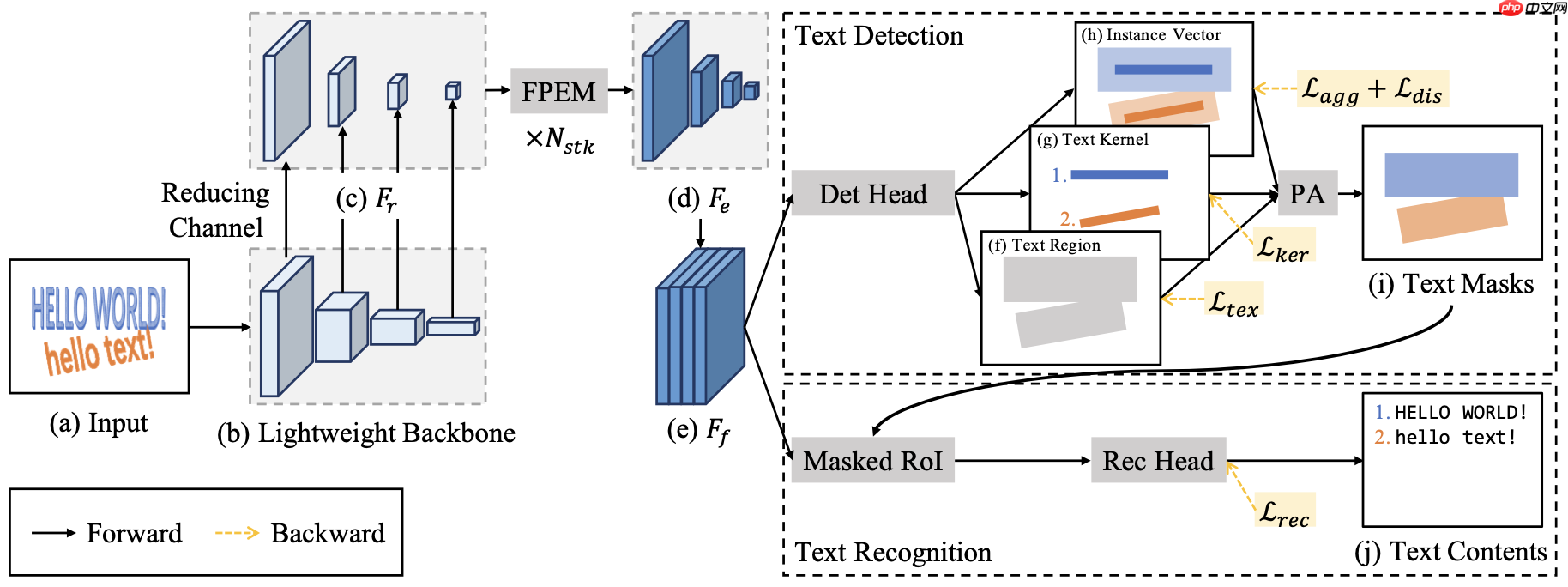
Wenhai Wang等人(2021)[13]提出了一种端到端的文本识别算法PAN++,可以有效识别检测和识别自然场景中的任意形状的文本,其整体架构图如 图26 所示。PAN++是一种基于文本内核(中心区域)的任意形状文本描述的模型,而且可以很好地区分相邻文本。此外,作为一种基于像素的表示,内核表示可以通过单个全卷积网络进行预测,这对实时应用的场景非常友好。利用核表示法的优点,作者设计了一系列的组件:1)包括一个由堆叠的特征金字塔增强模块(FPEMs)组成的计算高效的特征增强网络;2)一个具有像素聚合(Pixel Aggregation, PA)的轻量化检测头;3)以及一个高效的基于Mask RoI的注意力识别头。
为了验证PAN++方法的有效性,作者在Total-Text、CTW1500、ICDAR2015、MSRA-TD500和RCTW-17数据集上进行实验,其中在Total-Text、ICDAR2015和RCTW-17数据集上的可视化结果如 图27 所示。

OCR文本检测与识别是文本检索、自动化办公等众多应用的一项基本任务,现有大多数工作都是将文本检测和识别作为单独的任务处理。训练两个模型比较耗时,而且两个任务之间没有共享特征。近些年的一些方法致力于端到端的文本识别方法,目的是在一个网络中同时检测和识别文本。我们总结了深度学习端到端文本识别方法,这些方法大致可以分为两类:1)端到端规则文本识别和2)端到端任意形状文本识别。其中端到端规则文本识别常用算法包含FOTS和TextSpotter,主要用于规则文本的检测和识别。端到端任意形状文本识别常用算法包含Mask TextSpotterv1、Mask TextSpotter2、Mask TextSpotterv3、TextDragon、CharNet、TUTS、ABCNet、ABCNetV2、PGNet、PAN++等方法,主要用于任意形状的文本检测和识别。
以上就是《动手学OCR》系列课程之:端到端算法的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 518
518

























