本文介绍通过PaddlePaddle复现VoVNet39、VoVNet57并加入PaddleClas,完成flowers102数据集全流程处理。VoVNet基于OSA模块,继承DenseNet多感受野优点,解决密集连接效率低问题,性能与速度优于DenseNet和ResNet。文中详述模型结构、复现代码及在PaddleClas中的训练、测试和评估过程。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

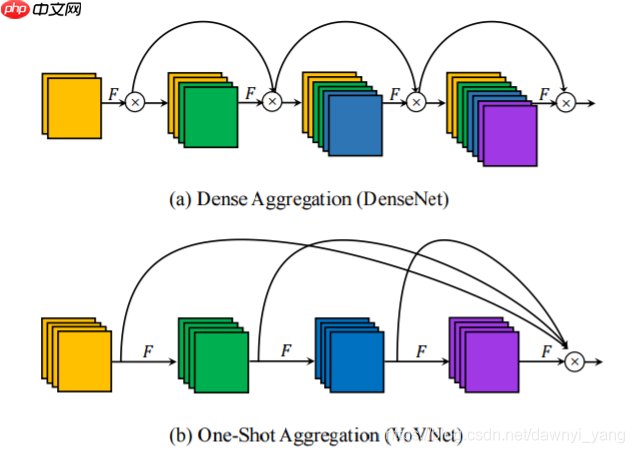
在目标检测中,DenseNet表现良好,通过聚合不同感受野特征层的方式,保留了中间特征层的信息。它通过feature reuse 使得模型的大小和flops大大降低,但是,实验证明,DenseNet backbone更加耗时也增加了能耗:dense connection架构使得输入channel线性递增,导致了更多的内存访问消耗,进而导致更多的计算消耗和能耗。因此文章介绍了一种由OSA(one-shot-aggregation)模块组成的叫做VoVNet的高效体系结构。该网络在继承DenseNet的多感受野表示多种特征的优点的情况下,同时解决了密集连接效率低的问题。该网络性能优于DenseNet,而且速度也比DenseNet快2倍。 此外,VoVNet网络速度和效率也都优于ResNet,而且对于小目标检测的性能有了显著提高。
在本文中将通过PaddlePaddle深度学习框架复现vovnet39、vovnet57,并添加至PaddleClas深度学习套件中,完成flowers102数据集的全流程训练、验证与测试。

实际上,DenseNet通过密集连接来交换特征数量和特征质量。尽管DenseNet的表现证明了这种交换是有益的,但从能源和时间的角度来看,这种交换还有其他一些缺点。
class _OSA_module(nn.Layer):
def __init__(self,
in_ch,
stage_ch,
concat_ch,
layer_per_block,
module_name,
identity=False):
super(_OSA_module, self).__init__()
self.identity = identity
self.layers = nn.LayerList()
in_channel = in_ch for i in range(layer_per_block):
self.layers.append(nn.Sequential(
*conv3x3(in_channel, stage_ch, module_name, i)))
in_channel = stage_ch # feature aggregation
in_channel = in_ch + layer_per_block * stage_ch
self.concat = nn.Sequential(
*(conv1x1(in_channel, concat_ch, module_name, 'concat'))) def forward(self, x):
identity_feat = x
output = []
output.append(x) for layer in self.layers:
x = layer(x)
output.append(x)
x = paddle.concat(output, axis=1)
xt = self.concat(x) if self.identity:
xt = xt + identity_feat return xtclass _OSA_stage(nn.Sequential):
def __init__(self,
in_ch,
stage_ch,
concat_ch,
block_per_stage,
layer_per_block,
stage_num):
super(_OSA_stage, self).__init__() if not stage_num == 2:
self.add_sublayer('Pooling',
nn.MaxPool2D(kernel_size=3, stride=2, ceil_mode=True))
module_name = f'OSA{stage_num}_1'
self.add_sublayer(module_name,
_OSA_module(in_ch,
stage_ch,
concat_ch,
layer_per_block,
module_name)) for i in range(block_per_stage-1):
module_name = f'OSA{stage_num}_{i+2}'
self.add_sublayer(module_name,
_OSA_module(concat_ch,
stage_ch,
concat_ch,
layer_per_block,
module_name,
identity=True))class VoVNet(nn.Layer):
def __init__(self,
config_stage_ch,
config_concat_ch,
block_per_stage,
layer_per_block,
class_num=1000):
super(VoVNet, self).__init__() # Stem module
stem = conv3x3(3, 64, 'stem', '1', 2)
stem += conv3x3(64, 64, 'stem', '2', 1)
stem += conv3x3(64, 128, 'stem', '3', 2)
self.add_sublayer('stem', nn.Sequential(*stem))
stem_out_ch = [128]
in_ch_list = stem_out_ch + config_concat_ch[:-1]
self.stage_names = [] for i in range(4): #num_stages
name = 'stage%d' % (i+2)
self.stage_names.append(name)
self.add_sublayer(name,
_OSA_stage(in_ch_list[i],
config_stage_ch[i],
config_concat_ch[i],
block_per_stage[i],
layer_per_block,
i+2))
self.classifier = nn.Linear(config_concat_ch[-1], class_num) for m in self.sublayers(): if isinstance(m, nn.Conv2D): # nn.init.kaiming_normal_(m.weight)
kaiming_normal_(m.weight) elif isinstance(m, (nn.BatchNorm2D, nn.GroupNorm)): # nn.init.constant_(m.weight, 1)
# nn.init.constant_(m.bias, 0)
ones_(m.weight)
zeros_(m.bias) elif isinstance(m, nn.Linear): # nn.init.constant_(m.bias, 0)
zeros_(m.bias) def forward(self, x):
x = self.stem(x) for name in self.stage_names:
x = getattr(self, name)(x)
x = F.adaptive_avg_pool2d(x, (1, 1)).flatten(1)
x = self.classifier(x) return xdef _load_pretrained(pretrained, model, model_url="", use_ssld=False):
if pretrained is False: pass
elif pretrained is True:
load_dygraph_pretrain_from_url(model, model_url, use_ssld=use_ssld) elif isinstance(pretrained, str):
load_dygraph_pretrain(model, pretrained) else: raise RuntimeError( "pretrained type is not available. Please use `string` or `boolean` type."
)def _vovnet(arch,
config_stage_ch,
config_concat_ch,
block_per_stage,
layer_per_block,
pretrained,
progress,
**kwargs):
model = VoVNet(config_stage_ch, config_concat_ch,
block_per_stage, layer_per_block,
**kwargs) if pretrained:
_load_pretrained(pretrained, model) return modeldef vovnet57(pretrained=False, progress=True, **kwargs):
r"""Constructs a VoVNet-57 model as described in
`"An Energy and GPU-Computation Efficient Backbone Networks"
<https://arxiv.org/abs/1904.09730>`_.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _vovnet('vovnet57', [128, 160, 192, 224], [256, 512, 768, 1024],
[1,1,4,3], 5, pretrained, progress, **kwargs)def vovnet39(pretrained=False, progress=True, **kwargs):
r"""Constructs a VoVNet-39 model as described in
`"An Energy and GPU-Computation Efficient Backbone Networks"
<https://arxiv.org/abs/1904.09730>`_.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _vovnet('vovnet39', [128, 160, 192, 224], [256, 512, 768, 1024],
[1,1,2,2], 5, pretrained, progress, **kwargs)def vovnet27_slim(pretrained=False, progress=True, **kwargs):
r"""Constructs a VoVNet-39 model as described in
`"An Energy and GPU-Computation Efficient Backbone Networks"
<https://arxiv.org/abs/1904.09730>`_.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _vovnet('vovnet27_slim', [64, 80, 96, 112], [128, 256, 384, 512],
[1,1,1,1], 5, pretrained, progress, **kwargs)# 1.查看飞桨版本import paddleprint(paddle.__version__)
添加了vovnet的PaddleClas已打包至PaddleClas.zip中,通过解压进行环境安装
参考文档:https://github.com/PaddlePaddle/PaddleClas/blob/release/2.2/docs/en/tutorials/install_en.md
# !git clone https://github.com/PaddlePaddle/PaddleClas.git!unzip PaddleClas.zip%cd ./PaddleClas/ !pip install --upgrade pip !pip3 install --upgrade -r requirements.txt -i https://mirror.baidu.com/pypi/simple
拥有图像识别、图像分类、特征学习等内容
| 参数名称 | 具体含义 | 默认值 |
|---|---|---|
| checkpoints | 断点模型路径,用于恢复训练 | null |
| pretrained_model | 预训练模型路径 | null |
| output_dir | 保存模型路径 | "./output/" |
| save_interval | 每隔多少个epoch保存模型 | 1 |
| eval_during_train | 是否在训练时进行评估 | True |
| eval_interval | 每隔多少个epoch进行模型评估 | 1 |
| epochs | 训练总epoch数 | 无 |
| print_batch_step | 每隔多少个mini-batch打印输出 | 10 |
| use_visualdl | 是否是用visualdl可视化训练过程 | False |
| image_shape | 图片大小 | [3,224,224] |
| save_inference_dir | inference模型的保存路径 | "./inference" |
| eval_mode | eval的模式 | "classification" |
注:image_shape值除了默认还可以选择list, shape: (3,)
eval_mode除了默认值还可以选择"retrieval"
参考文档:https://github.com/PaddlePaddle/PaddleClas/blob/release/2.2/docs/en/tutorials/config_description_en.md
训练集中有:
train_list.txt:训练集,1020张图
val_list.txt: 验证集,1020张图
train_extra_list.txt:大的训练集,7169张图
图片展示:

基于phpBIZ v2.0 中文自由版,主要实现的功能: 会员数据整合: 论坛的用户可无需注册即可以拥有自己在phpBIZ的帐号,注册一个论坛帐号即可同时拥有一个phpBIZ帐号,注册一个phpBIZ帐号同时也会开通一个相应的论坛帐号,因而避免了重复注册 新商品传送至论坛: 商家登陆的每件商品可以选择是否在论坛发帖通知。后台管理员设定传送论坛版块
 1
1


数据写入情况:
# 1.修改当前路径%cd ./dataset/# 2.下载数据集!wget https://paddle-imagenet-models-name.bj.bcebos.com/data/flowers102.zip# 3.解压数据!unzip flowers102.zip
我们要首先对配置文件进行修改。 AI Studio由于没有共享内存,所以需要修改num_workers: 0,其他的可以不修改。
查看自己的环境是否为CPU或者是GPU然后对device:进行修改
# 切换目录到PaddleClas下%cd /home/aistudio/PaddleClas# 开始训练!python tools/train.py -c ./ppcls/configs/ImageNet/VovNet/vovnet39_x1.0.yaml
-c为训练配置文件
-o Infer.infer_imgs=为预测的图片
-o Global.pretrained_model=为用于预测的模型
!python tools/infer.py -c ./ppcls/configs/ImageNet/VovNet/vovnet39_x1.0.yaml\
-o Infer.infer_imgs=dataset/flowers102/jpg/image_00001.jpg \
-o Global.pretrained_model=output_vov/vovnet39/latest[{'class_ids': [75, 45, 43, 18, 58], 'scores': [1.0, 0.0, 0.0, 0.0, 0.0], 'file_name': 'dataset/flowers102/jpg/image_00001.jpg', 'label_names': []}]
这里对75,45,43,18,58的比例进行了分析,最后以75为最后结果。
import paddle
!python -m paddle.distributed.launch \
tools/eval.py \
-c ./ppcls/configs/ImageNet/VovNet/vovnet39_x1.0.yaml \
-o Global.pretrained_model=output_vov/vovnet39/latest[Eval][Epoch 0][Avg]CELoss: 0.34251, loss: 0.34251, top1: 0.90885, top5: 0.99464
以上就是论文复现:基于PaddleClas复现VovNet的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号





 855
855























