该内容围绕PALM病理性近视病灶检测与分割赛题展开,介绍了利用PaddleSeg和patta工具的实现过程。包括克隆相关库、解压数据集、生成数据列表、构建数据集,选用SFNet模型,混合多种损失函数训练,最后进行模型预测并展示结果,以完成病灶分割任务。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

常规赛:PALM病理性近视病灶检测与分割由ISBI2019 PALM眼科挑战赛赛题再现,其中病理性近视病灶检测与分割的任务旨在对眼科图像进行判断,获取两种疾病的分割结果。
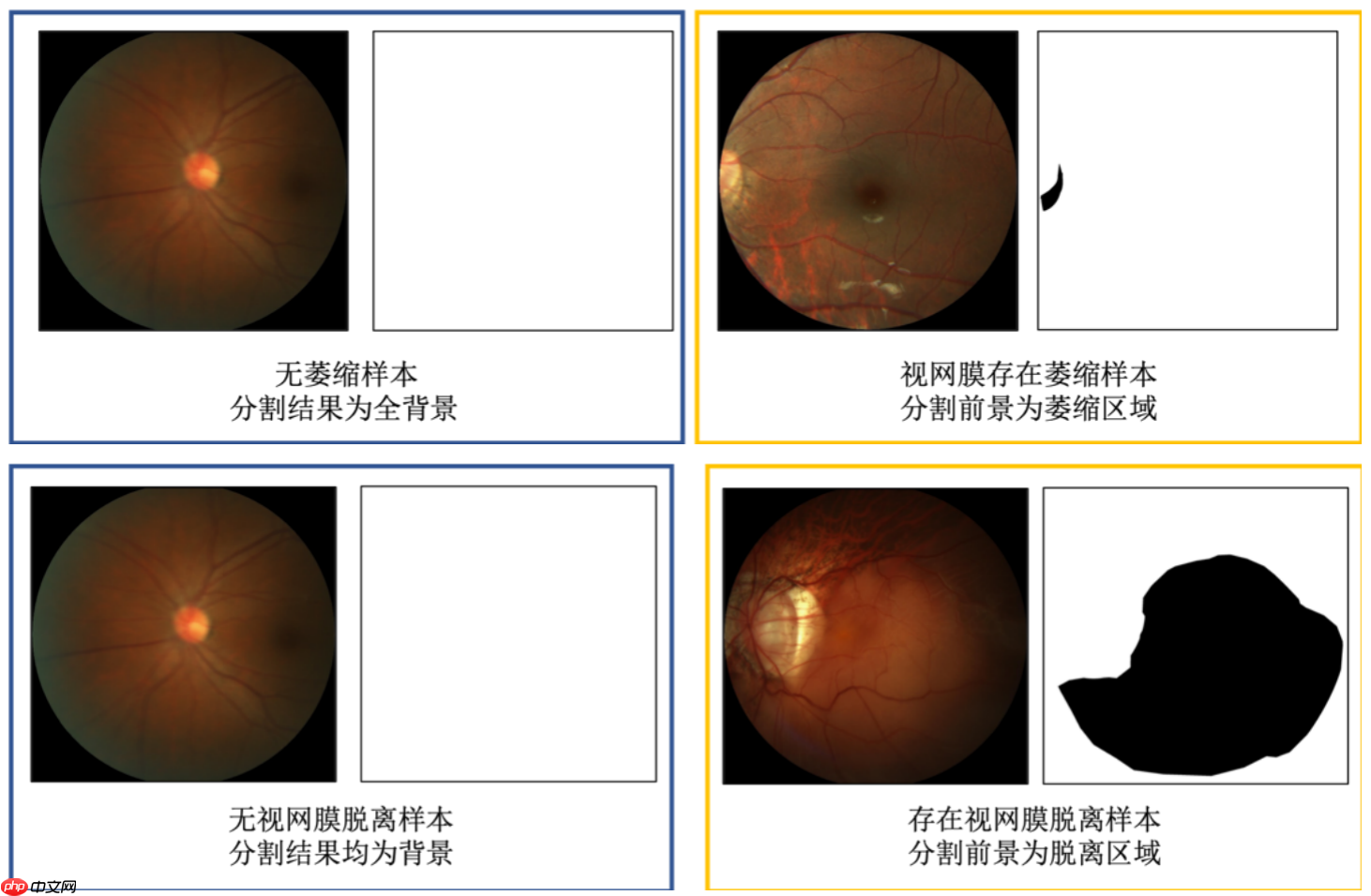
数据集由中山大学中山眼科中心提供800张带萎缩和脱离病变分割标注的眼底彩照供选手训练模型,另提供400张带标注数据供平台进行模型测试。图像分辨率为1444×1444,或2124124×2056。标注金标准存储为BMP图像。分割图像大小与对应的眼底图像大小相同,标签如下:
评价指标为:0.5 X F1分数 + 0.5 X Dice
比赛链接: 常规赛:PALM病理性近视病灶检测与分割
既然是分割任务,首先想到的是PaddleSeg。那就直接搞起来就对了。这里想到之前遥感分割中用到patta还挺不错的,这里也弄进来一起搅。
! git clone https://gitee.com/paddlepaddle/PaddleSeg.git
! pip -q install pattaimport sys
sys.path.append('PaddleSeg')这个没啥好写的。
! unzip -oq /home/aistudio/data/data85135/常规赛:PALM病理性近视病灶检测与分割.zip! rm -rf __MACOSX ! mv 常规赛:PALM病理性近视病灶检测与分割 dataset
老套路了,这里按0.9进行划分的,0.9的训练数据,0.1的验证数据。只是这里将两个数据分开进行处理,分别生成数据列表。这里我做点改变就是针对有一个任务标签很少的情况,每当读到它有标签的图像,就写50次进来,希望正负样本可以更加均衡。
import osimport randomdef create_list(lab_class='Detachment', s_rate=9, ex_num=50):
file_path = 'dataset/Train/fundus_image'
imgs_name = os.listdir(file_path)
random.shuffle(imgs_name) with open('dataset/Train/' + lab_class + '_train.txt', 'w') as tf: with open('dataset/Train/' + lab_class + '_val.txt', 'w') as ef: for idx, img_name in enumerate(imgs_name):
img_path = os.path.join('fundus_image', img_name)
lab_path = img_exist('dataset/Train', \
img_path.replace('fundus_image', ('Lesion_Masks/' + \
lab_class)).replace('jpg', 'bmp')) if (idx % 10 + 1) < s_rate: if lab_class == 'Detachment' and lab_path != 'None': for _ in range(ex_num):
tf.write(img_path + ' ' + lab_path + '\n') else:
tf.write(img_path + ' ' + lab_path + '\n') else:
ef.write(img_path + ' ' + lab_path + '\n')def img_exist(path, name):
p = os.path.join(path, name) if os.path.exists(p): return name else: return 'None'def shuffle_txt(path, save_path):
out = open(save_path,'w')
lines = [] with open(path, 'r') as infile: for line in infile:
lines.append(line)
random.shuffle(lines) for line in lines:
out.write(line)
out.close()
create_list('Detachment', s_rate=8)
create_list('Atrophy')
shuffle_txt('dataset/Train/Detachment_train.txt', \ 'dataset/Train/Detachment_train_shuffle.txt')构建数据集也是套路的seg的方案,只是也是分别进行了处理。
from paddleseg.datasets import Datasetimport paddleseg.transforms as T# 构建训练集train_transforms = [
T.RandomHorizontalFlip(), # 水平翻转
T.RandomRotation(), # detachment
T.Resize(target_size=(1024, 1024)), # 修改大小
T.Normalize() # 归一化]
d_train_dataset = Dataset(
transforms=train_transforms,
dataset_root='dataset/Train',
num_classes=2,
mode='train',
train_path='dataset/Train/Detachment_train_shuffle.txt',
separator=' ',
)
a_train_dataset = Dataset(
transforms=train_transforms,
dataset_root='dataset/Train',
num_classes=2,
mode='train',
train_path='dataset/Train/Atrophy_train.txt',
separator=' ',
)# 构建验证集val_transforms = [
T.Resize(target_size=(1024, 1024)),
T.Normalize()
]
d_val_dataset = Dataset(
transforms=val_transforms,
dataset_root='dataset/Train',
num_classes=2,
mode='val',
val_path='dataset/Train/Detachment_val.txt',
separator=' ',
)
a_val_dataset = Dataset(
transforms=val_transforms,
dataset_root='dataset/Train',
num_classes=2,
mode='val',
val_path='dataset/Train/Atrophy_val.txt',
separator=' ',
)这里也是输出测试一下,看看数据读取有没有什么问题。避免后面报一堆错不知道哪儿去找问题。还可以看看图像是否正确。
# import numpy as np# import matplotlib# import matplotlib.pyplot as plt# %matplotlib inline# for img, lab in d_train_dataset:# print(img.shape, lab.shape)# plt.subplot(121);plt.imshow(img.transpose((1, 2, 0)))# plt.subplot(122);plt.imshow(lab)# plt.show()# break
这里选了一个我从来没用过的网路SFNet,不过有一次就会有下一次,所以就尝试下没用过的。损失混合了三种损失,两个任务需要分别进行训练。
import paddlefrom paddleseg.models import SFNetfrom paddleseg.models.backbones import ResNet50_vdfrom paddleseg.models.losses import BCELoss, DiceLoss, LovaszHingeLoss, MixedLoss# 模型url = 'a_save_output/best_model/model.pdparams'model = SFNet(num_classes=2, backbone=ResNet50_vd(output_stride=8), \
backbone_indices=[0, 1, 2, 3], pretrained=url)# 训练参数epochs = 10batch_size = 4iters = epochs * len(d_train_dataset) // batch_size# 损失函数mix_losses = [BCELoss(), DiceLoss(), LovaszHingeLoss()]
mix_coef = [1, 1, 1]
mixloss = MixedLoss(mix_losses, mix_coef)
losses = {}
losses['types'] = [mixloss]
losses['coef'] = [1]# 学习率及优化器base_lr = 3e-4# lr = paddle.optimizer.lr.CosineAnnealingDecay(base_lr, T_max=(iters // 5))lr = paddle.optimizer.lr.PolynomialDecay(base_lr, 4277 // 2, end_lr=3e-8)
optimizer = paddle.optimizer.Adam(lr, parameters=model.parameters(), weight_decay=paddle.regularizer.L2Decay(1e-9))2021-05-24 18:50:46 [INFO] No pretrained model to load, ResNet_vd will be trained from scratch. 2021-05-24 18:50:46 [INFO] Loading pretrained model from a_save_output/best_model/model.pdparams 2021-05-24 18:50:47 [INFO] There are 354/354 variables loaded into SFNet.
分别调用train即可。
from paddleseg.core import train
train(
model=model,
train_dataset=d_train_dataset,
val_dataset=d_val_dataset,
optimizer=optimizer,
save_dir='d_save_output',
iters=iters,
batch_size=batch_size,
save_interval=int(iters / 10),
log_iters=10,
num_workers=0,
losses=losses,
use_vdl=True)预测这里主要是两个问题。
import paddlefrom paddleseg.models import SFNetfrom paddleseg.models.backbones import ResNet50_vdimport paddleseg.transforms as Tfrom paddleseg.core import inferimport osimport cv2from tqdm import tqdmfrom PIL import Imageimport numpy as npimport patta as ttadef nn_infer(model, model_path, imgs_path, class_name='Atrophy', is_tta=True):
params = paddle.load(model_path)
model.set_dict(params)
model.eval() if not os.path.exists('Lesion_Segmentation'):
os.mkdir('Lesion_Segmentation') if not os.path.exists(os.path.join('Lesion_Segmentation', class_name)):
os.mkdir(os.path.join('Lesion_Segmentation', class_name)) # 预测结果
transforms = T.Compose([
T.Resize(target_size=(1024, 1024)),
T.Normalize()
]) # 循环预测和保存
for img_path in tqdm(imgs_path):
H, W, _ = np.asarray(Image.open(img_path)).shape
img, _ = transforms(img_path) # 进行数据预处理
img = paddle.to_tensor(img[np.newaxis, :]) # C,H,W -> 1,C,H,W
# TTA
if is_tta == True:
tta_pres = paddle.zeros([1, 2, 1024, 1024]) for tta_transform in tta.aliases.flip_transform():
tta_img = tta_transform.augment_image(img) # TTA_transforms
tta_pre = infer.inference(model, tta_img) # 预测
deaug_pre = tta_transform.deaugment_mask(tta_pre)
tta_pres += deaug_pre
pre = tta_pres / 2.
else:
pre = infer.inference(model, img) # 预测
pred = paddle.argmax(pre, axis=1).numpy().reshape((1024, 1024)).astype('uint8') * 255
pred = cv2.resize(pred, (W, H), interpolation=cv2.INTER_NEAREST)
pil_img = Image.fromarray(pred)
pil_img.save(os.path.join(('Lesion_Segmentation/' + class_name), img_path.split('/')[-1].replace('jpg', 'png')), 'png')# 网络准备a_model_path='a_save_output/best_model/model.pdparams'd_model_path='d_save_output/best_model/model.pdparams'model = SFNet(num_classes=2, backbone=ResNet50_vd(output_stride=8), \
backbone_indices=[0, 1, 2, 3], pretrained=None)# 预测文件set_path = 'dataset/PALM-Testing400-Images'names = os.listdir(set_path)
imgs_path = []for name in names:
imgs_path.append(os.path.join(set_path, name))# 预测nn_infer(model, a_model_path, imgs_path, class_name='Atrophy', is_tta=False)
nn_infer(model, d_model_path, imgs_path, class_name='Detachment', is_tta=False)可以用matplotlib显示一下分割的结果看看。
import numpy as npfrom PIL import Imageimport matplotlib.pyplot as plt
%matplotlib inline
img_path = 'dataset/PALM-Testing400-Images/T0225.jpg'inf_a_path = 'Lesion_Segmentation/Atrophy/T0225.png'inf_d_path = 'Lesion_Segmentation/Detachment/T0225.png'img = Image.open(img_path)
inf_a = Image.open(inf_a_path)
inf_d = Image.open(inf_d_path)
plt.figure(figsize=(15, 5))
plt.subplot(131);plt.imshow(img);plt.title('img')
plt.subplot(132);plt.imshow(inf_a);plt.title('inf_a')
plt.subplot(133);plt.imshow(inf_d);plt.title('inf_d')
plt.show()<Figure size 1080x360 with 3 Axes>
以上就是飞桨常规赛:PALM病理性近视病灶检测与分割 - 5月第六名方案的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 846
846
























