本文聚焦语义多模态图像合成(SMIS)任务,旨在通过特定类控制器调整对应区域生成图像,且不影响其他部分。针对现有方法局限,提出GroupDNet,利用组卷积并逐步减少解码器组数,提升可控性与生成质量。实验表明其优越性,还能支持多种合成应用。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

PS:哪里觉得不理解大家可以一起探讨
相信看到这个题目大家有点懵逼,于是我打算让大家看看论文开始的摘要。
在本文中,我们着重于语义多模态图像合成(SMIS)任务,即在语义层次上生成多模态图像。以前的工作试图使用多个特定于类的生成器,限制其在具有少量类的数据集中的使用。相反,我们提出了一种新的群减少网络(GroupDNet),它利用生成器中的组卷积,并逐步减少解码器中卷积的组数。因此,GroupDNet在将语义标签转换为自然图像方面具有更多的可控性,并且对于具有许多类的数据集具有合理的高质量产量。在几个具有挑战性的数据集上进行的实验证明了GroupDNet在执行SMIS任务方面的优越性。我们还表明,GroupDNet能够执行广泛的有趣的合成应用程序。 在本文中,我们着重于语义多模态图像合成(SMIS)任务,即在语义层次上生成多模态图像。以前的工作试图使用多个特定于类的生成器,限制其在具有少量类的数据集中的使用。相反,我们提出了一种新的群减少网络(GroupDNet),它利用生成器中的组卷积,并逐步减少解码器中卷积的组数。因此,GroupDNet在将语义标签转换为自然图像方面具有更多的可控性,并且对于具有许多类的数据集具有合理的高质量产量。在几个具有挑战性的数据集上进行的实验证明了GroupDNet在执行SMIS任务方面的优越性。我们还表明,GroupDNet能够执行广泛的有趣的合成应用程序。
这个时候大家会发现关键词就出现了,SMIS。这篇论文就提出了一种模型架构更好的实现这个任务。因此接下来我带着大家继续阅读什么叫做SMIS任务。
只是想象一下一个来自人类解析映射的内容创建场景。在语义到图像的转换模型的帮助下,解析映射(就是语义分割信息)可以转换为每个真实的图片。一般来说看起来不错,但生成的衣服上身不适合你的口味。然后问题就出现了,要么这些模型不支持多模态合成,要么当这些模型改变了上身时,其他部分也会随之变化。这些都不能满足你的意图。总之,这个用户可控的内容创建场景可以被解释为执行一个任务,在语义级别上产生多模态结果,而其他语义部分没有被触及。 我们将这个任务总结为:语义多模态图像合成(SMIS)。对于每个语义,我们都有它特定的控制器。通过调整特定类的控制器,只有相应的区域被相应地改变。 这里论文举了一个小小的例子,见figure 1。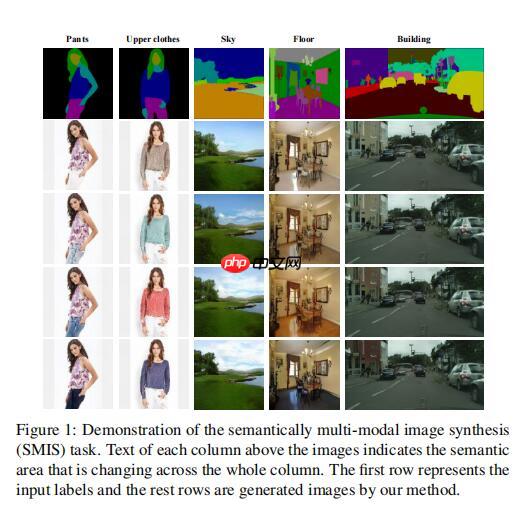
设M表示一个语义分割掩码。假设在数据集中有C个语义类。H和W分别表示图像的高度和宽度。作为一个非常明了的方式去引导label-to-image模型变换。 生成器G需要M作为条件输入来生成图像。然而,为了支持多模态生成,我们需要另一个输入源来控制生成的多样性。通常,我们使用一个编码器来提取一个潜在代码Z作为控制器。在接收到这两个输入后,可以通过O=G(Z,M)产生图像输出O。然而,在语义多模态图像合成(SMIS)任务中,我们的目标是通过干扰特定类的潜在代码来产生语义不同的图像,该代码独立地控制相应类的多样性。
对于SMIS任务的挑战,关键是将潜在代码划分为一系列特定于类的潜在代码,每个潜在代码只控制一个特定的语义类的生成。传统的卷积编码器并不是一个最优的选择,因为所有类的特征表示都是内部纠缠在潜在的代码中。即使我们有特定于类的潜在代码,如何使用这些代码仍然存在问题。正如我们将在实验部分所说明的,简单地用特定于类的代码替换spade[38]中的原始潜在代码,处理SMIS任务的能力有限。这一现象促使我们需要在编码器和解码器中进行一些架构修改,以更有效地完成任务。
好了,此刻我已经把任务给描述清楚了,那么这个时候面对这个任务,我们的解决思路是什么,首先是剖析这个问题,SMIS和一般的语义生成任务有什么不同?它要求更细腻的语义控制。我认为有特征解耦的那个味道,像素级特征控制(那个英特尔的editgan,论文地址为(https://arxiv.org/pdf/2111.03186.pdf).
1. 如果这个语义生成具体任务有100类那就需要100个子网络,就是这个子网络数量会随着类别数量增加而增加,参数增加的很快,相应训练方面也会有很多问题,训练时长,资源等,这种类型的方法很快就会面临性能的下降,训练时间的增加和计算资源消耗的线性增加。 2. 各个语义信息部分的互动性较差。
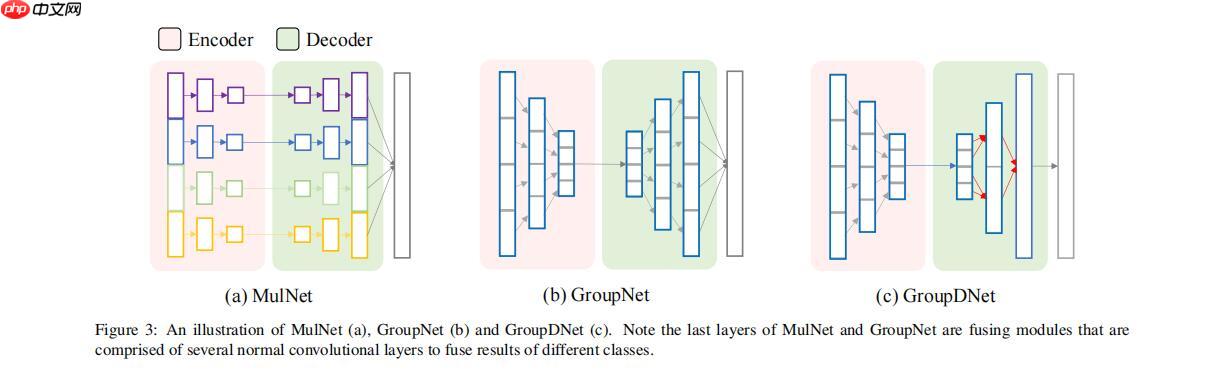
此刻相信大家已经初具想法了,就是在SPADE基础上结合groupdnet的思路,用group conv替代普通的conv,好,放图,这就是这篇论文的主要架构。
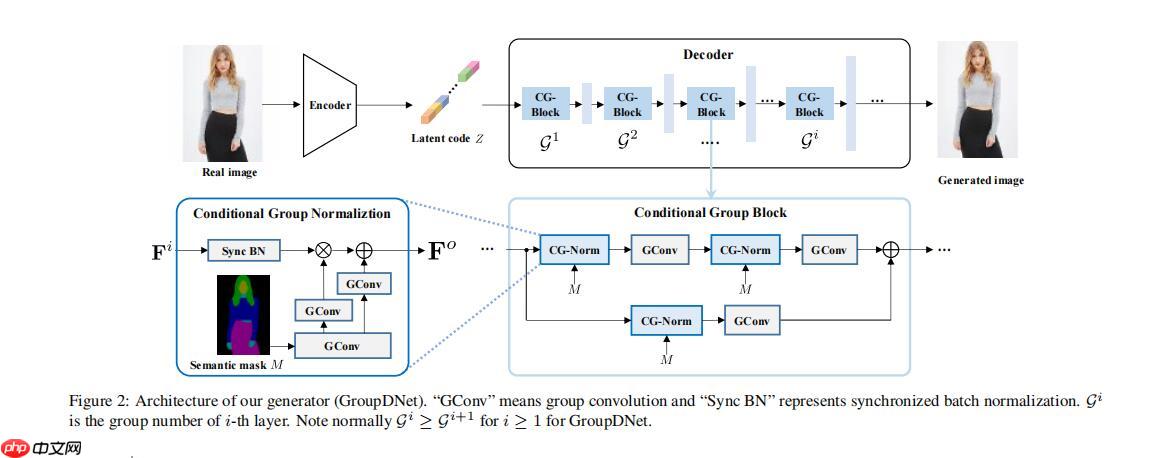
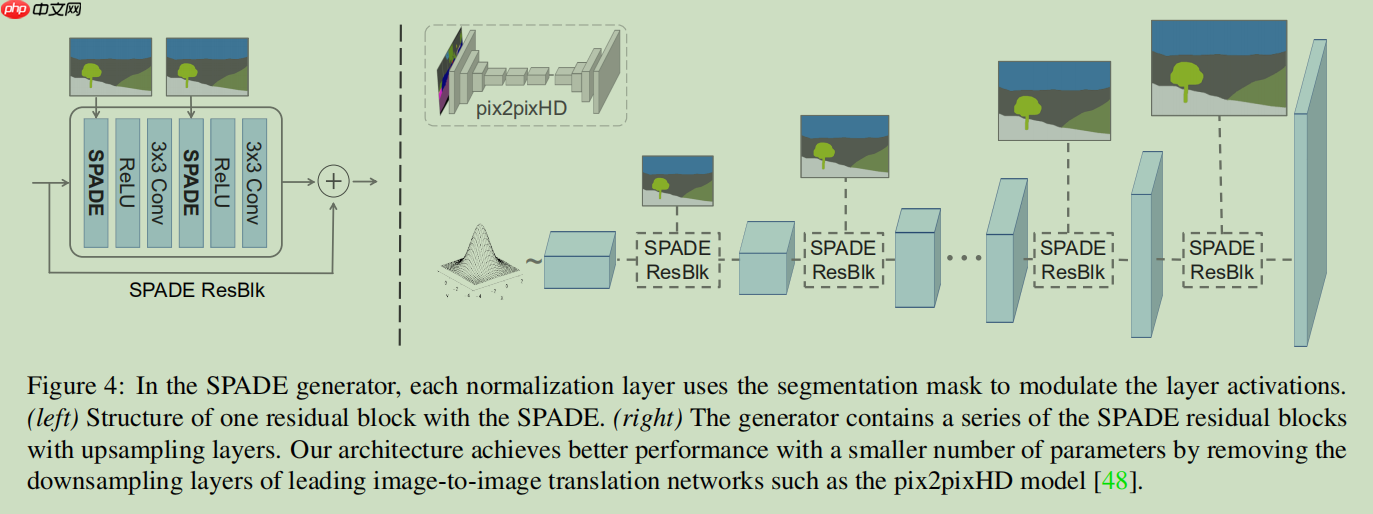
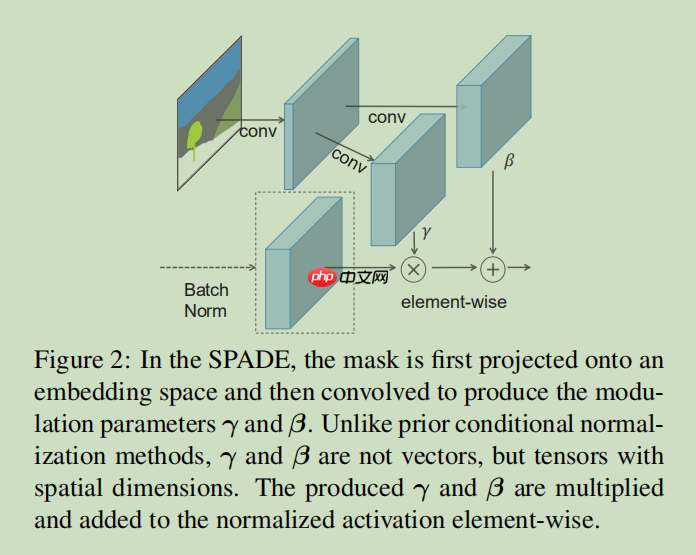
给大家对照解释一下,CG-Normal就是SPADE,CG-Block就是Spade-resblock. 给大家回顾一下SPADE模型图。
从本论文架构图可以看出,GroupDNet包含一个编码器和一个解码器。受VAE[26]和spade[38]思想的启发,编码器E产生了一个潜在的编码Z,该编码在训练过程中应该遵循一个高斯分布N(0,1)。在测试时,编码器E被丢弃。从高斯分布中随机抽样的编码代替z。为了实现这一点,我们使用重新参数化技巧[26]在训练过程中启用可微损失函数。具体来说,编码器通过两个全连接的层来预测一个平均向量和一个方差向量来表示编码的分布。编码z分布和高斯分布之间的差距可以通过施加kl-散度损失来最小化。
Encoder:原文是这样的:

我在这里给大家总结几个点:
images = Nonefor i in range(b):
image = None
for j in range(class_num):
one = X[i] * Mc[i][j] #[3,h,w]
one = one.unsqueeze([0])#[1,3,h,w]
if image ==None:
image =one else:
image = concat([image,one],axis = 1)
#image.shape = [1,3*class_num,h,w]
if images ==None:
images =image else:
images = concat([images,image],axis = 0)
# images.shape = [b,3*class_num,h,w]好了这个就是输入encoder的input,这样处理数据的核心含义是什么呢?作者是这么解释的:
该操作减少了Encoder处理特征解纠缠的一部分压力,节省了对特征进行精确编码的容量。




以上就是论文解读一篇关于语义生成论文(要求控制单独语义生成)的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 317
317
























