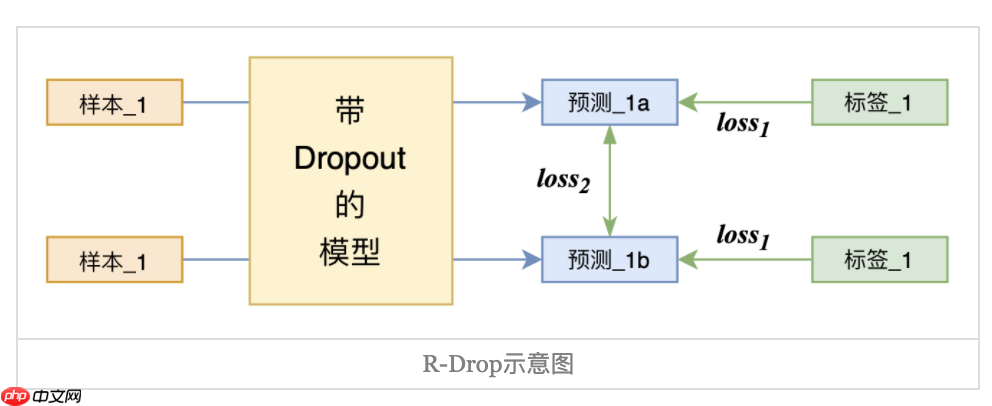
R-Drop是基于Dropout的改进正则化方法,通过对模型输出层施加约束减少过拟合。其让每个样本两次通过带Dropout的同一模型,用KL散度约束两次输出一致,总损失为交叉熵与KL散度之和。代码实现仅增KL项,实验显示能有效提升模型正确率。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

由于深度神经网络非常容易过拟合,因此 Dropout 方法采用了随机丢弃每层的部分神经元,以此来避免在训练过程中的过拟合问题。正是因为每次随机丢弃部分神经元,导致每次丢弃后产生的子模型都不一样,所以 Dropout 的操作一定程度上使得训练后的模型是一种多个子模型的组合约束。基于 Dropout 的这种特殊方式对网络带来的随机性,研究员们提出了 R-Drop 来进一步对(子模型)网络的输出预测进行了正则约束。论文通过实验得出一种改进的正则化方法R-dropout,简单来说,它通过使用若干次(论文中使用了两次)dropout,定义新的损失函数。实验结果表明,尽管结构非常简单,但是却能很好的防止模型过拟合,进一步提高模型的正确率。模型主体如下图所示。
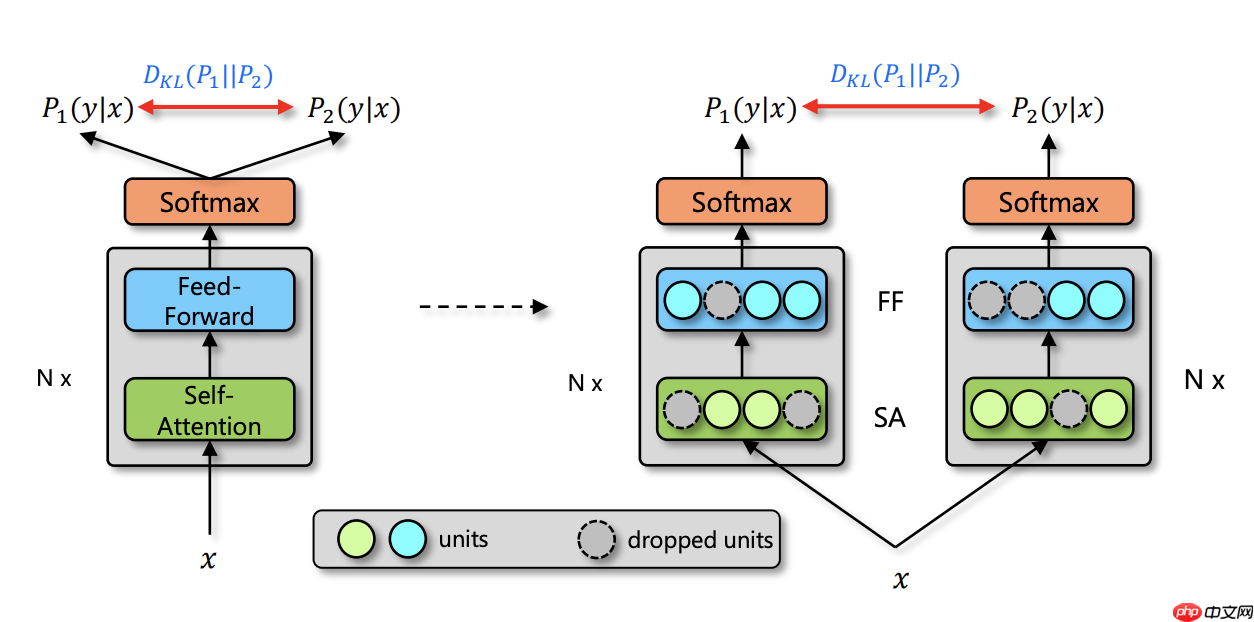
由于深度神经网络非常容易过拟合,因此 Dropout 方法采用了随机丢弃每层的部分神经元,以此来避免在训练过程中的过拟合问题。正是因为每次随机丢弃部分神经元,导致每次丢弃后产生的子模型都不一样,所以 Dropout 的操作一定程度上使得训练后的模型是一种多个子模型的组合约束。基于 Dropout 的这种特殊方式对网络带来的随机性,研究员们提出了 R-Drop 来进一步对(子模型)网络的输出预测进行了正则约束。
与传统作用于神经元(Dropout)或者模型参数(DropConnect)上的约束方法不同,R-Drop 作用于模型的输出层,弥补了 Dropout 在训练和测试时的不一致性。简单来说就是在每个 mini-batch 中,每个数据样本过两次带有 Dropout 的同一个模型,R-Drop 再使用 KL-divergence 约束两次的输出一致。既约束了由于 Dropout 带来的两个随机子模型的输出一致性。
模型的训练目标包含两个部分,一个是两次输出之间的KL散度,如下:
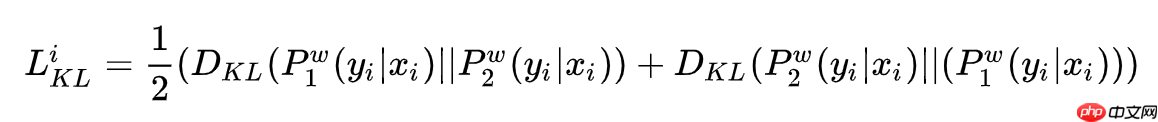
另一个是模型自有的损失函数交叉熵,如下:

部分功能简介:商品收藏夹功能热门商品最新商品分级价格功能自选风格打印结算页面内部短信箱商品评论增加上一商品,下一商品功能增强商家提示功能友情链接用户在线统计用户来访统计用户来访信息用户积分功能广告设置用户组分类邮件系统后台实现更新用户数据系统图片设置模板管理CSS风格管理申诉内容过滤功能用户注册过滤特征字符IP库管理及来访限制及管理压缩,恢复,备份数据库功能上传文件管理商品类别管理商品添加/修改/
 0
0

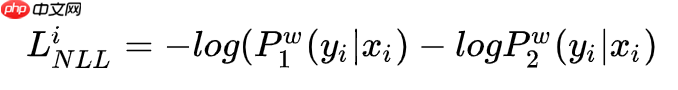
总损失函数为:
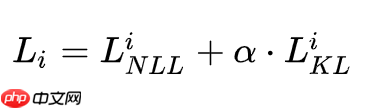
与传统的训练方法相比,R- Drop 只是简单增加了一个 KL-divergence 损失函数项,并没有其他任何改动。其PaddlePaddle版本对应的代码实现如下所示。
交叉熵=熵+相对熵(KL散度) 其与交叉熵的关系如下:
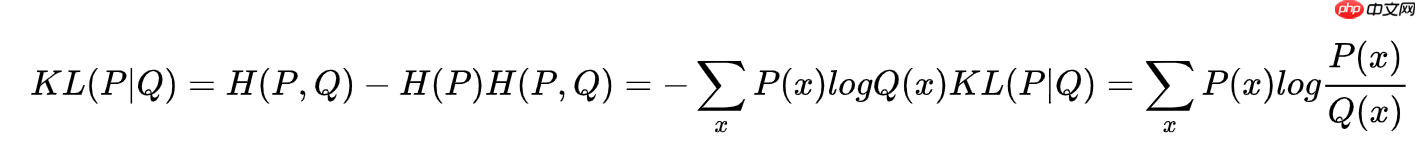
import paddle.nn.functional as F
# define your task model, which outputs the classifier logits
model = TaskModel()def compute_kl_loss(self, p, q, pad_mask=None):
p_loss = F.kl_div(F.log_softmax(p, axis=-1), F.softmax(q, axis=-1), reduction='none')
q_loss = F.kl_div(F.log_softmax(q, axis=-1), F.softmax(p, axis=-1), reduction='none')
# pad_mask is for seq-level tasks if pad_mask is not None:
p_loss.masked_fill_(pad_mask, 0.)
q_loss.masked_fill_(pad_mask, 0.)
# You can choose whether to use function "sum" and "mean" depending on your task
p_loss = p_loss.sum()
q_loss = q_loss.sum()
loss = (p_loss + q_loss) / 2
return loss
# keep dropout and forward twice
logits = model(x)
logits2 = model(x)
# cross entropy loss for classifier
ce_loss = 0.5 * (cross_entropy_loss(logits, label) + cross_entropy_loss(logits2, label))
kl_loss = compute_kl_loss(logits, logits2)# 论文中对于CV任务的超参数
α = 0.6# carefully choose hyper-parameters
loss = ce_loss + α * kl_loss本次实验以白菜生长的四个周期为例,进行生长情况识别实验。数据来自于讯飞的比赛。数据展示如下:发芽期、幼苗期、莲座期、结球期。




!cd 'data/data107306' && unzip -q img.zip!cd 'data/data106868' && unzip -q pdweights.zip
# 导入所需要的库from sklearn.utils import shuffleimport osimport pandas as pdimport numpy as npfrom PIL import Imageimport paddleimport paddle.nn as nnfrom paddle.io import Datasetimport paddle.vision.transforms as Timport paddle.nn.functional as Ffrom paddle.metric import Accuracyimport warnings
warnings.filterwarnings("ignore")# 读取数据train_images = pd.read_csv('data/data107306/img/df_all.csv')
train_images = shuffle(train_images)# 划分训练集和校验集all_size = len(train_images)# print(all_size)train_size = int(all_size * 0.9)
train_image_list = train_images[:train_size]
val_image_list = train_images[train_size:]
train_image_path_list = train_image_list['image'].values
label_list = train_image_list['label'].values
train_label_list = paddle.to_tensor(label_list, dtype='int64')
val_image_path_list = val_image_list['image'].values
val_label_list1 = val_image_list['label'].values
val_label_list = paddle.to_tensor(val_label_list1, dtype='int64')# 定义数据预处理data_transforms = T.Compose([
T.Resize(size=(256, 256)),
T.Transpose(), # HWC -> CHW
T.Normalize(
mean = [0, 0, 0],
std = [255, 255, 255],
to_rgb=True)
])# 构建Datasetclass MyDataset(paddle.io.Dataset):
"""
步骤一:继承paddle.io.Dataset类
"""
def __init__(self, train_img_list, val_img_list,train_label_list,val_label_list, mode='train'):
"""
步骤二:实现构造函数,定义数据读取方式,划分训练和测试数据集
"""
super(MyDataset, self).__init__()
self.img = []
self.label = []
self.valimg = []
self.vallabel = [] # 借助pandas读csv的库
self.train_images = train_img_list
self.test_images = val_img_list
self.train_label = train_label_list
self.test_label = val_label_list # self.mode = mode
if mode == 'train': # 读train_images的数据
for img,la in zip(self.train_images, self.train_label):
self.img.append('data/data107306/img/imgV/'+img)
self.label.append(la) else : # 读test_images的数据
for img,la in zip(self.test_images, self.test_label):
self.img.append('data/data107306/img/imgV/'+img)
self.label.append(la) def load_img(self, image_path):
# 实际使用时使用Pillow相关库进行图片读取即可,这里我们对数据先做个模拟
image = Image.open(image_path).convert('RGB')
image = np.array(image).astype('float32') return image def __getitem__(self, index):
"""
步骤三:实现__getitem__方法,定义指定index时如何获取数据,并返回单条数据(训练数据,对应的标签)
"""
image = self.load_img(self.img[index])
label = self.label[index]
return data_transforms(image), label def __len__(self):
"""
步骤四:实现__len__方法,返回数据集总数目
"""
return len(self.img)#train_loadertrain_dataset = MyDataset(train_img_list=train_image_path_list, val_img_list=val_image_path_list, train_label_list=train_label_list, val_label_list=val_label_list, mode='train') train_loader = paddle.io.DataLoader(train_dataset, places=paddle.CPUPlace(), batch_size=8, shuffle=True, num_workers=0)#val_loaderval_dataset = MyDataset(train_img_list=train_image_path_list, val_img_list=val_image_path_list, train_label_list=train_label_list, val_label_list=val_label_list, mode='test') val_loader = paddle.io.DataLoader(val_dataset, places=paddle.CPUPlace(), batch_size=8, shuffle=True, num_workers=0)
from work.senet154 import SE_ResNeXt50_vd_32x4dfrom work.res2net import Res2Net50_vd_26w_4sfrom work.se_resnet import SE_ResNet50_vd# 模型封装# model_re2 = SE_ResNeXt50_vd_32x4d(class_num=4)model_re2 = Res2Net50_vd_26w_4s(class_dim=4) model_ss = SE_ResNet50_vd(class_num=4) model_ss.train() model_re2.train() epochs = 2optim1 = paddle.optimizer.Adam(learning_rate=3e-4, parameters=model_re2.parameters()) optim2 = paddle.optimizer.Adam(learning_rate=3e-4, parameters=model_ss.parameters())
import paddle.nn.functional as Fdef compute_kl_loss(p, q, pad_mask=None):
p_loss = F.kl_div(F.log_softmax(p, axis=-1), F.softmax(q, axis=-1), reduction='none')
q_loss = F.kl_div(F.log_softmax(q, axis=-1), F.softmax(p, axis=-1), reduction='none')
# pad_mask is for seq-level tasks
if pad_mask is not None:
p_loss.masked_fill_(pad_mask, 0.)
q_loss.masked_fill_(pad_mask, 0.) # You can choose whether to use function "sum" and "mean" depending on your task
p_loss = p_loss.sum()
q_loss = q_loss.sum()
loss = (p_loss + q_loss) / 2
return loss# 用Adam作为优化函数for epoch in range(epochs): for batch_id, data in enumerate(train_loader()):
x_data = data[0]
y_data = data[1]
predicts1 = model_re2(x_data)
predicts2 = model_ss(x_data)
loss1 = F.cross_entropy(predicts1, y_data, soft_label=False)
loss2 = F.cross_entropy(predicts2, y_data, soft_label=False)
# cross entropy loss for classifier
ce_loss = 0.5 * (loss1 + loss2)
kl_loss = compute_kl_loss(predicts1, predicts2) # 论文中对于CV任务的超参数
α = 0.6
# carefully choose hyper-parameters
loss = ce_loss + α * kl_loss # 计算损失
acc1 = paddle.metric.accuracy(predicts1, y_data)
acc2 = paddle.metric.accuracy(predicts2, y_data)
loss.backward() if batch_id % 50 == 0: print("epoch: {}, batch_id: {}, loss1 is: {}".format(epoch, batch_id, loss.numpy()))
optim1.step()
optim1.clear_grad()
optim2.step()
optim2.clear_grad()以上就是R-Drop论文复现的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号





 317
317
























