该项目为涉案人员物品保管制度下的子项目,利用目标检测识别登记常见嫌疑人物品以加快事件处理。其使用3900+张不同条件拍摄的qian包等5类物品数据,按VOC格式标注,经处理后用PaddleX训练YOLOv3模型,导出后部署至服务器,前端Vue、后端Flask,可进行物品检测预测。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

在我国的涉案人员物品保管制度 中明确规定:对涉案人员物品进行登记保存、扣押时,需经单位负责人批准,依法填写涉案人员物品登记保存、扣押决定书和涉案人员物品清单后,方可执行。那么,利用目标检测对于常见的嫌疑人物品进行识别登记,是不是可以加快事件处理速度呢,因此该项目发展成为这一整个项目的子项目,并将此子项目部署开源出来。
项目已部署至服务器,可以进行访问:http://ai.sqdxwz.com/
部分时候过载严重,如果无法返回结果请刷新重试或者换个时间使用~

所有数据均为使用不同型号,不同像素,不同角度,不同环境进行拍摄的数据图。数据拍摄包括单个物品,多个物品混合拍摄
立即学习“前端免费学习笔记(深入)”;

Easily find JSON paths within JSON objects using our intuitive Json Path Finder
 193
193

!pip install paddlex==2.0rc -q
本项目使用的静物检测据集已经按VOC格式进行标注,数据集按照如下方式进行组织:
Dataset/ # 目标检测数据集根目录 |--Annotations/ # 标注文件所在目录 | |--PartA_00000.xml | |--PartB_00000.xml | |--... | |--... |--JPEGImages/ # 原图文件所在目录 | |--PartA_00000.jpg | |--PartB_00000.jpg | |--... | |--... |
# 解压数据集文件夹中!unzip -d ./ data/data96807/DatasetId_190936_1624526988.zip
# 清理一下jpeg和xml不匹配问题import os,shutil
jpeg = 'MyDataset/JPEGImages'jpeg_list = os.listdir(jpeg)
anno = 'MyDataset/Annotations'anno_list = os.listdir(anno)for pic in jpeg_list:
name = pic.split('.')[0]
anno_name = name + '.xml'
#print(anno_name)
if anno_name not in anno_list:
os.remove(os.path.join(jpeg,pic))# 划分数据集!paddlex --split_dataset --format VOC --dataset_dir MyDataset --val_value 0.2 --test_value 0.1
2021-10-25 21:02:25 [INFO] Dataset split starts... 2021-10-25 21:02:25 [INFO] Dataset split done. 2021-10-25 21:02:25 [INFO] Train samples: 714 2021-10-25 21:02:25 [INFO] Eval samples: 204 2021-10-25 21:02:25 [INFO] Test samples: 102 2021-10-25 21:02:25 [INFO] Split files saved in MyDataset
使用paddlex命令即可将数据集随机划分成70%训练集,20%验证集和10%测试集:
划分好的数据集会额外生成labels.txt, train_list.txt, val_list.txt, test_list.txt四个文件,之后可直接进行训练。
import paddlex as pdxfrom paddlex import transforms
train_transforms = transforms.Compose([
transforms.RandomCrop(crop_size=224),
transforms.RandomHorizontalFlip(),
transforms.Normalize()
])
eval_transforms = transforms.Compose([
transforms.ResizeByShort(short_size=256),
transforms.CenterCrop(crop_size=224),
transforms.Normalize()
])# 定义训练和验证所用的数据集# API说明:https://github.com/PaddlePaddle/PaddleX/blob/release/2.0-rc/paddlex/cv/datasets/voc.py#L29train_dataset = pdx.datasets.VOCDetection(
data_dir='MyDataset',
file_list='MyDataset/train_list.txt',
label_list='MyDataset/labels.txt',
transforms=train_transforms,
shuffle=True)
eval_dataset = pdx.datasets.VOCDetection(
data_dir='MyDataset',
file_list='MyDataset/val_list.txt',
label_list='MyDataset/labels.txt',
transforms=eval_transforms,
shuffle=False)2021-10-25 21:07:21 [INFO] Starting to read file list from dataset... 2021-10-25 21:07:22 [INFO] 714 samples in file MyDataset/train_list.txt creating index... index created! 2021-10-25 21:07:22 [INFO] Starting to read file list from dataset... 2021-10-25 21:07:22 [INFO] 204 samples in file MyDataset/val_list.txt creating index... index created!
# 初始化模型,并进行训练# 可使用VisualDL查看训练指标,参考https://github.com/PaddlePaddle/PaddleX/tree/release/2.0-rc/tutorials/train#visualdl可视化训练指标num_classes = len(train_dataset.labels) model = pdx.models.YOLOv3(num_classes=num_classes, backbone='MobileNetV3_ssld')
# API说明:https://github.com/PaddlePaddle/PaddleX/blob/release/2.0-rc/paddlex/cv/models/detector.py#L155# 各参数介绍与调整说明:https://paddlex.readthedocs.io/zh_CN/develop/appendix/parameters.htmlmodel.train(
num_epochs=300,
train_dataset=train_dataset,
train_batch_size=8,
eval_dataset=eval_dataset,
learning_rate=0.001 / 8,
warmup_steps=1000,
warmup_start_lr=0.0,
save_interval_epochs=20,
lr_decay_epochs=[216, 243, 275],
save_dir='output/yolov3_mobilenet')模型训练后保存在output文件夹,如果要使用PaddleInference进行部署需要导出成静态图的模型,运行如下命令,会自动在output文件夹下创建一个inference_model的文件夹,用来存放导出后的模型。
!paddlex --export_inference --model_dir=output/yolov3_mobilenet/best_model --save_dir=output/inference_model
import globimport numpy as npimport threadingimport timeimport randomimport osimport base64import cv2import jsonimport paddlex as pdx# 可以修改为自己图片路径image_name = 'MyDataset/JPEGImages/PartB_00234.jpg' model = pdx.load_model('output/yolov3_mobilenet/best_model')
img = cv2.imread(image_name)
result = model.predict(img)
keep_results = []
areas = []
f = open('result.txt','a')
count = 0for dt in np.array(result):
cname, bbox, score = dt['category'], dt['bbox'], dt['score'] if score < 0.5: continue
keep_results.append(dt)
count+=1
f.write(str(dt)+'\n')
f.write('\n')
areas.append(bbox[2] * bbox[3])
areas = np.asarray(areas)
sorted_idxs = np.argsort(-areas).tolist()
keep_results = [keep_results[k] for k in sorted_idxs] if len(keep_results) > 0 else []print(keep_results)print(count)
f.write("the total number is :"+str(int(count)))
f.close()pdx.visualize_detection(image_name, result, threshold=0.5, save_dir='./output/yolov3_mobilenet')
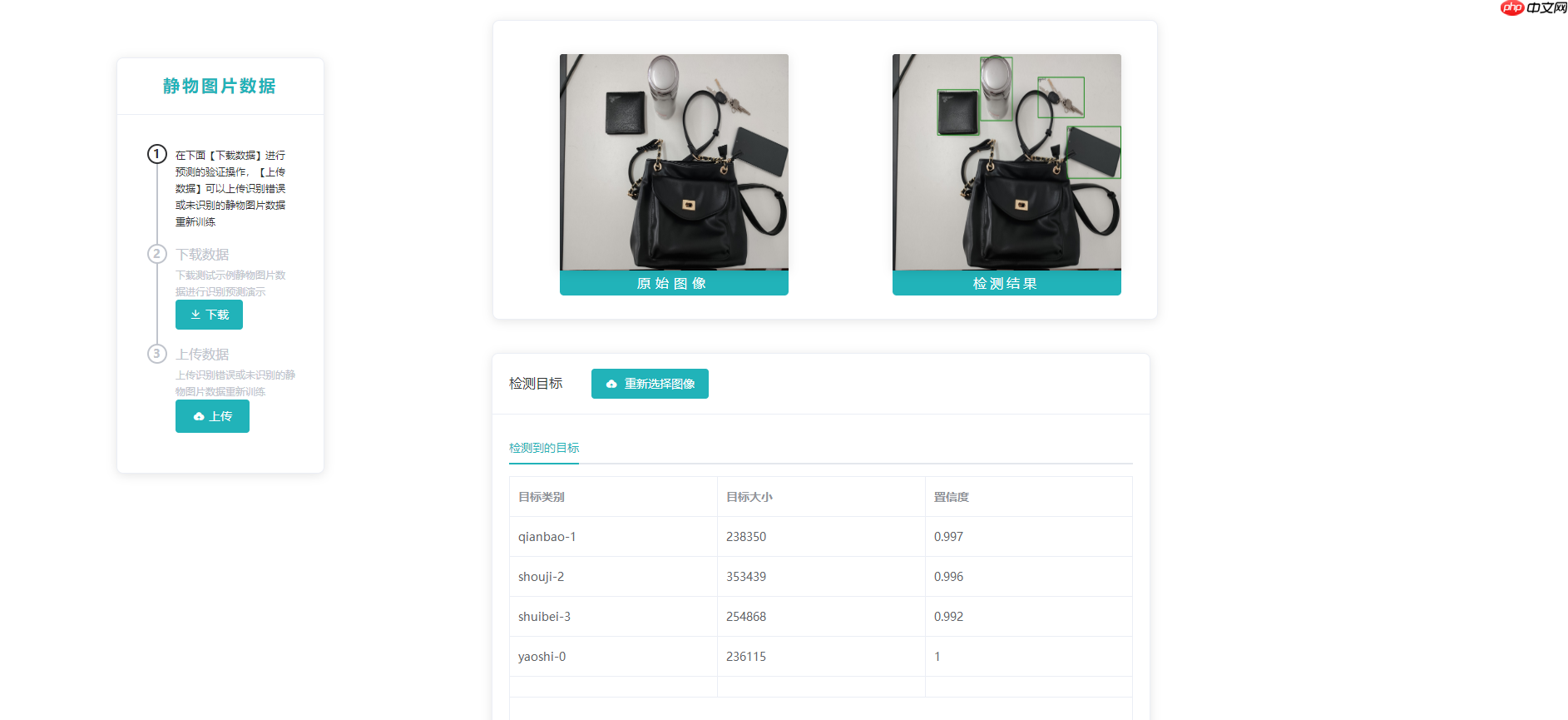

以上就是【已部署】利用PaddleX静物物品智能识别并使用Vue前端部署的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号





 582
582





















