INADE基于SPADE改进,是一种条件归一化方法,旨在提升语义图像生成多样性。它结合语义分割(提供普遍性)与实例分割(提供特殊性),通过统一噪声采样协调各归一化层,避免不一致。编码器生成相关噪声辅助训练,解决了现有方法中同语义实例风格趋同的问题,实现语义级和实例级多样性。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

首先这篇论文也是主要基于一个SPADE的论文,这里还是强推FutureSI项目的spade讲解,但是呢这个SPADE被它改成了INADE,同样是一个conditional normal,之所以这么改,原作者目的是提高一个图像生成的多样性。后面会具体讲解
这里描述一下它对于语义生成任务的看法:
这里就是说SPADE很好用
这里认为对于模型只输入一个语义分割信息,明显不够,靠只输入这玩意要求模型有太好的效果多样性,几乎不可能
这里说明GroupNet是不行的,这里这个改进方案GroupDNet我在我的项目论文解读一篇关于语义生成论文(要求控制单独语义生成)提到,这是另一篇论文啊。
与第二点有点呼应的味道
这个时候它讲了一下这个INADE添加实例分割的想法来源:
这里我认为就是普遍性与特殊性的合理结合,语义分割提供普遍性,实例分割提供特殊性。就比如两只比翼双飞的鸟,都是鸟(普遍性),但是2个不同个体(特殊性)。如果没有实例分割输入,那就退化输入语义分割。
考虑到生成网络包含多个条件归一化层,一个统一的采样解决方案仍然是协调所有这些层的关键。一种直接的方法,即对每个归一化层进行独立的随机抽样,可能会引入不一致性,并导致多样性被严重中和。因此,在本文中,我们提出了一种实例自适应调制采样方法,该方法可以在channel不相等的多个归一化层上实现一致的实例采样。
说白了就是在INADE输入一个贯穿deocder的noise,强调了一下这个noise这个融合的idea很牛逼,需要吹一下
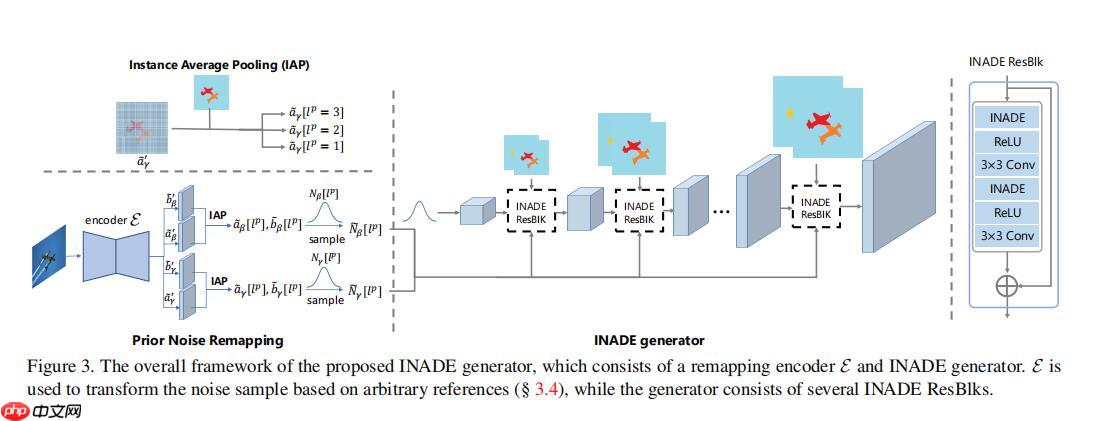
首先这个INADE它为了提高这个多样性主要想法是什么呢,它比起SPADE多了一个实例分割的输入,见这张图。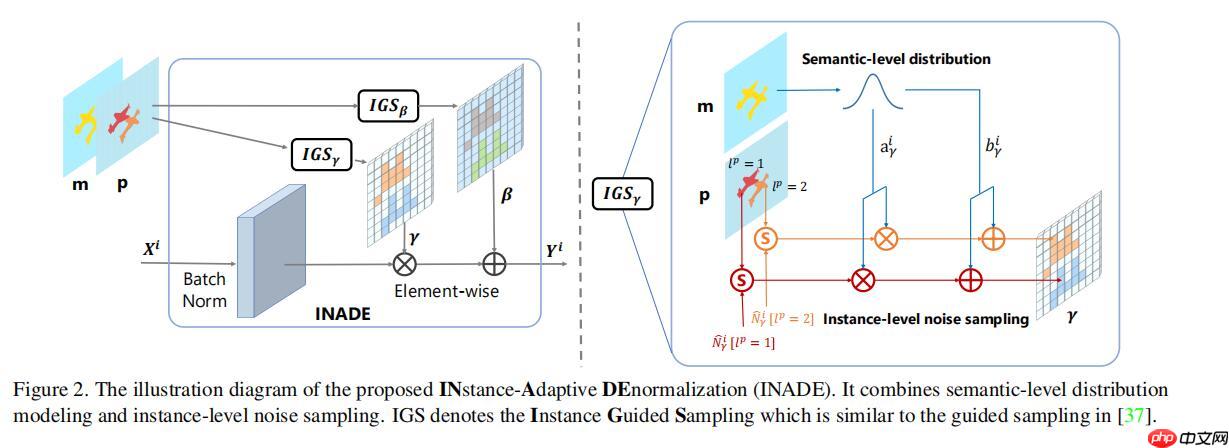
m就是语义分割输入,p是实例分割输入,这应该是一张照片上的两个鸟,语义分割把它们用同一标识,但是实例分割进行了区分。
INADE数学公式表示
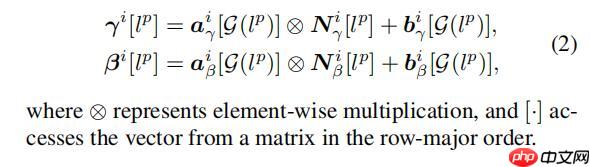

这是INADE,实际pytorch代码:
class ILADE(nn.Module):
def __init__(self, config_text, norm_nc, label_nc, noise_nc):
super().__init__()
self.norm_nc = norm_nc assert config_text.startswith('spade')
parsed = re.search('spade(\D+)(\d)x\d', config_text)
param_free_norm_type = str(parsed.group(1)) if param_free_norm_type == 'instance':
self.param_free_norm = nn.InstanceNorm2d(norm_nc, affine=False) elif param_free_norm_type == 'syncbatch':
self.param_free_norm = SynchronizedBatchNorm2d(norm_nc, affine=False) elif param_free_norm_type == 'batch':
self.param_free_norm = nn.BatchNorm2d(norm_nc, affine=False) else: raise ValueError('%s is not a recognized param-free norm type in SPADE'
% param_free_norm_type) # wights and bias for each class
self.weight = nn.Parameter(torch.Tensor(label_nc, norm_nc,2))
self.bias = nn.Parameter(torch.Tensor(label_nc, norm_nc,2))
self.reset_parameters()
self.fc_noise = nn.Linear(noise_nc, norm_nc) def reset_parameters(self):
nn.init.uniform_(self.weight)
nn.init.zeros_(self.bias) def forward(self, x, segmap, input_instances=None, noise=None):
# Part 1. generate parameter-free normalized activations
# noise is [B, inst_nc, 2, noise_nc], 2 is for scale and bias
normalized = self.param_free_norm(x) # Part 2. scale the segmentation mask and instance mask
segmap = F.interpolate(segmap, size=x.size()[2:], mode='nearest')
input_instances = F.interpolate(input_instances, size=x.size()[2:], mode='nearest') # the segmap is concate with instance map
inst_map = torch.unsqueeze(segmap[:,-1,:,:],1)
segmap = segmap[:,:-1,:,:] # Part 3. class affine with noise
noise_size = noise.size() # [B,inst_nc,2,noise_nc]
noise_reshape = noise.view(-1, noise_size[-1]) # reshape to [B*inst_nc*2,noise_nc]
noise_fc = self.fc_noise(noise_reshape) # [B*inst_nc*2, norm_nc]
noise_fc = noise_fc.view(noise_size[0],noise_size[1],noise_size[2],-1) # create weigthed instance noise for scale
class_weight = torch.einsum('ic,nihw->nchw', self.weight[...,0], segmap)
class_bias = torch.einsum('ic,nihw->nchw', self.bias[...,0], segmap) # init_noise = torch.randn([x.size()[0], input_instances.size()[1], self.norm_nc], device=x.get_device())
instance_noise = torch.einsum('nic,nihw->nchw', noise_fc[:,:,0,:], input_instances)
scale_instance_noise = class_weight*instance_noise+class_bias # create weighted instance noise for bias
class_weight = torch.einsum('ic,nihw->nchw', self.weight[..., 1], segmap)
class_bias = torch.einsum('ic,nihw->nchw', self.bias[..., 1], segmap) # init_noise = torch.randn([x.size()[0], input_instances.size()[1], self.norm_nc], device=x.get_device())
instance_noise = torch.einsum('nic,nihw->nchw', noise_fc[:,:,1,:], input_instances)
bias_instance_noise = class_weight * instance_noise + class_bias
out = scale_instance_noise * normalized + bias_instance_noise return out下面是我写的paddle版本
import paddleimport paddle.nn as nnimport paddle.nn.functional as F'''
在这里有一个einsum相信大家也不用一般,至少我不用啊,哈哈
在这里的用法,我举例一下
instance_noise = paddle.einsum('nic,nihw->nchw', noise_fc[:,:,0,:], input_instances)#[B,instance_nc,norm_nc] [B,instance_nc,h,w] ->[B,norm_nc,h,w]
noise_fc[:,:,0,:],input_instances这两个tensor.shape分别为[B,instance_nc,norm_nc] [B,instance_nc,h,w]
经过了上述的这里einsum操作,就得到shape为[B,norm_nc,h,w]的tensor,那这里很明显就是相当于在nn.linear放在第1维进行的那种感觉无bias,矩阵乘法
'''class INADE(nn.Layer):
def __init__(self, norm_nc = 64, label_nc = 46, noise_nc = 108):
super().__init__()
self.param_free_norm = nn.InstanceNorm2D(norm_nc,weight_attr=False, bias_attr=False) # wights and bias for each class
weight = self.create_parameter([label_nc,norm_nc,2], default_initializer = paddle.nn.initializer.Uniform())#随机均匀分布初始化函数
self.add_parameter("weight", weight)
bias = self.create_parameter([label_nc,norm_nc,2],default_initializer = paddle.nn.initializer.Constant())
self.add_parameter("bias", bias)
self.fc_noise = nn.Linear(noise_nc, norm_nc) def forward(self, x, segmap, input_instances=None, noise=None):
# Part 1. generate parameter-free normalized activations
# noise is [B, inst_nc, 2, noise_nc], 2 is for scale and bias
normalized = self.param_free_norm(x) # Part 2. scale the segmentation mask and instance mask
segmap = F.interpolate(segmap, size=x.shape[2:], mode='nearest')
input_instances = F.interpolate(input_instances, size=x.shape[2:], mode='nearest') # the segmap is concate with instance map
inst_map = paddle.unsqueeze(segmap[:,-1,:,:],1)# 后面就不用了
segmap = segmap[:,:-1,:,:] # Part 3. class affine with noise
noise_size = noise.shape # [B,inst_nc,2,noise_nc]
noise_reshape = noise.reshape([-1, noise_size[-1]]) # reshape to [B*inst_nc*2,noise_nc]
noise_fc = self.fc_noise(noise_reshape) # [B*inst_nc*2, norm_nc]
noise_fc = noise_fc.reshape([noise_size[0],noise_size[1],noise_size[2],-1])#[B,instance_nc,2,norm_nc]
print("noise_fc",noise_fc.shape) # create weigthed instance noise for scale
class_weight = paddle.einsum('ic,nihw->nchw', self.weight[...,0], segmap)#[label_nc, norm_nc] [b,label_nc,h,w] ->#[B,norm_nc,h,w]
print("class_weight",class_weight.shape)
class_bias = paddle.einsum('ic,nihw->nchw', self.bias[...,0], segmap)#[label_nc, norm_nc] [b,label_nc,h,w] ->#[B,norm_nc,h,w]
# init_noise = torch.randn([x.size()[0], input_instances.size()[1], self.norm_nc], device=x.get_device())
instance_noise = paddle.einsum('nic,nihw->nchw', noise_fc[:,:,0,:], input_instances)#[B,instance_nc,norm_nc] [B,instance_nc,h,w] ->[B,norm_nc,h,w]
scale_instance_noise = class_weight*instance_noise+class_bias # create weighted instance noise for bias
class_weight = paddle.einsum('ic,nihw->nchw', self.weight[..., 1], segmap)
class_bias = paddle.einsum('ic,nihw->nchw', self.bias[..., 1], segmap) # init_noise = torch.randn([x.size()[0], input_instances.size()[1], self.norm_nc], device=x.get_device())
instance_noise = paddle.einsum('nic,nihw->nchw', noise_fc[:,:,1,:], input_instances)#[B,instance_nc,norm_nc] #[B,instance_nc,h,w]
bias_instance_noise = class_weight * instance_noise + class_bias
out = scale_instance_noise * normalized + bias_instance_noise return out
x = paddle.randn([3,64,50,50])
segmap = paddle.randn([3,47,66,66])
inst = paddle.randn([3,72,50,50])
noise = paddle.randn([3,72,2,108])
INADE()(x,segmap,inst,noise).shapeW0222 11:03:38.883304 183 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1 W0222 11:03:38.890153 183 device_context.cc:465] device: 0, cuDNN Version: 7.6.
noise_fc [3, 72, 2, 64] class_weight [3, 64, 50, 50]
[3, 64, 50, 50]
这里还有一个细节就是,这个noise要和这个输入的图片信息有关系,相当于这个z是包含信息的。这样方便训练,嗯。 这里代码实现很复杂,实在有兴趣自己看原项目,因为这里我不能用到我的项目上我就没有太关心。加油.
开个玩笑啊,其实这里这个noise的设计具体落实到代码里面其实是很重要的,因为其中第一点是可以通过noise来进行模型生成多样性的增加和控制,然后另外就是这个noise开始训练的时候必须要和原图信息有关联,这样好训练,不然如果这个Noise直接初始化就很难训练。
接下来我就直接从代码的角度去分析实际pytorch代码中的主体实践。

import paddleimport paddle.nn as nn x = paddle.randn((100,3,224,224)) unfold = nn.Unfold(kernel_sizes=[3, 3]) result = unfold(x) #result.shape = [100,3*3*3,(224-3+1)*(224-3+1)]print(result.shape)

'''
该代码块是重新构造一个encoder里面用到的卷积封装,这个encoder就是为了训练时候构造这个noise用的
'''import paddleimport paddle.nn.functional as Fimport paddle.nn as nnclass InstanceAwareConv2d(nn.Layer):
def __init__(self, fin = 64, fout = 128, kw = 3, stride=1, padding=1):
super().__init__()
self.kw = kw
self.stride = stride
self.padding = padding
self.fin = fin
self.fout = fout
self.unfold = nn.Unfold(kw, strides = stride, paddings = padding)
weight = self.create_parameter([fout, fin, kw, kw], default_initializer = paddle.nn.initializer.Uniform())#随机均匀分布初始化函数
self.add_parameter("weight", weight)
bias = self.create_parameter([fout],default_initializer = paddle.nn.initializer.Constant())
self.add_parameter("bias", bias) def forward(self, x, instances, check=False):
N,C,H,W = x.shape # cal the binary mask from instance map
instances = F.interpolate(instances, x.shape[2:], mode='nearest') # [n,1,h,w]
inst_unf = self.unfold(instances) # print("inst_unf",inst_unf.shape)
# substract the center pixel
center = paddle.unsqueeze(inst_unf[:, self.kw * self.kw // 2, :], axis=1)#因为instance的channel为1,所以这个channel的center 为 self.kw * self.kw // 2
# print("center",center.shape)
mask_unf = inst_unf - center # clip the absolute value to 0~1
mask_unf = paddle.abs(mask_unf)
mask_unf = paddle.clip(mask_unf, 0, 1)
mask_unf = 1.0 - mask_unf # [n,k*k,L]
# print("mask_unf",mask_unf.shape)#mask_unf [4, 9, 65536]
# # multiply mask_unf and x
x_unf = self.unfold(x) # [n,c*k*k,L]
# print("x_unf",x_unf.shape) #x_unf [4, 64*9, 65536]
x_unf = x_unf.reshape([N, C, -1, x_unf.shape[-1]]) # [n,c,k*k,L]
# print("x_unf",x_unf.shape) #[4, 64, 9, 65536]
mask = paddle.unsqueeze(mask_unf,1) # [n,1,k*k,L]
mask_x = mask * x_unf # [n,c,k*k,L]
mask_x = mask_x.reshape([N,-1,mask_x.shape[-1]]) # [n,c*k*k,L]
# # conv operation
weight = self.weight.reshape([self.fout,-1]) # [fout, c*k*k]
out = paddle.einsum('cm,nml->ncl', weight, mask_x) # print("out",out.shape)#[4, 128, 65536]
# # x_unf = torch.unsqueeze(x_unf, 1) # [n,1,c*k*k,L]
# # out = torch.mul(masked_weight, x_unf).sum(dim=2, keepdim=False) # [n,fout,L]
bias = paddle.unsqueeze(paddle.unsqueeze(self.bias,0),-1) # [1,fout,1]
out = out + bias # print("out",out.shape)#[4, 128, 65536]
out = out.reshape([N,self.fout,H//self.stride,W//self.stride]) # # print('weight:',self.weight[0,0,...])
# # print('bias:',self.bias)
if check:
out2 = nn.functional.conv2d(x, self.weight, self.bias, stride=self.stride, padding=self.padding) print((out-out2).abs().max()) return out
x = paddle.randn([4,64,256,256])
y = paddle.randn([4,1,256,256])
InstanceAwareConv2d()(x,y).shapeW0222 16:13:26.634137 145 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1 W0222 16:13:26.638576 145 device_context.cc:465] device: 0, cuDNN Version: 7.6.
[4, 128, 256, 256]
# Encoder构造import paddle
import paddle.nn as nnimport numpy as npclass Encoder_OPT:
def __init__(self):
super().__init__()
self.ngf = 64
self.semantic_nc = 46
self.no_instance = True
self.noise_nc = 108opt = Encoder_OPT()class instanceAdaptiveEncoder(nn.Layer):
def __init__(self, opt):
super().__init__()
self.opt = opt
kw = 3
pw = int(np.ceil((kw - 1.0) / 2))
ndf = opt.ngf
conv_layer = InstanceAwareConv2d
self.layer1 = conv_layer(3, ndf, kw, stride=2, padding=pw)
self.norm1 = nn.InstanceNorm2D(ndf)
self.layer2 = conv_layer(ndf * 1, ndf * 2, kw, stride=2, padding=pw)
self.norm2 = nn.InstanceNorm2D(ndf * 2)
self.layer3 = conv_layer(ndf * 2, ndf * 4, kw, stride=2, padding=pw)
self.norm3 = nn.InstanceNorm2D(ndf * 4)
self.layer4 = conv_layer(ndf * 4, ndf * 8, kw, stride=2, padding=pw)
self.norm4 = nn.InstanceNorm2D(ndf * 8)
self.middle = conv_layer(ndf * 8, ndf * 4, kw, stride=1, padding=pw)
self.norm_middle = nn.InstanceNorm2D(ndf * 4)
self.up1 = conv_layer(ndf * 8, ndf * 2, kw, stride=1, padding=pw)
self.norm_up1 = nn.InstanceNorm2D(ndf * 2)
self.up2 = conv_layer(ndf * 4, ndf * 1, kw, stride=1, padding=pw)
self.norm_up2 = nn.InstanceNorm2D(ndf)
self.up3 = conv_layer(ndf * 2, ndf, kw, stride=1, padding=pw)
self.norm_up3 = nn.InstanceNorm2D(ndf)
self.up = nn.Upsample(scale_factor=2, mode='bilinear')
self.class_nc = opt.semantic_nc if opt.no_instance else opt.semantic_nc-1
self.scale_conv_mu = conv_layer(ndf, opt.noise_nc, kw, stride=1, padding=pw)
self.scale_conv_var = conv_layer(ndf, opt.noise_nc, kw, stride=1, padding=pw)
self.bias_conv_mu = conv_layer(ndf, opt.noise_nc, kw, stride=1, padding=pw)
self.bias_conv_var = conv_layer(ndf, opt.noise_nc, kw, stride=1, padding=pw)
self.actvn = nn.LeakyReLU(0.2, False)
self.opt = opt def instAvgPooling(self, x, instances):
inst_num = instances.shape[1] for i in range(inst_num):
inst_mask = paddle.unsqueeze(instances[:,i,:,:], 1) # [n,1,h,w]
pixel_num = paddle.sum(paddle.sum(inst_mask, axis=2, keepdim = True), axis=3, keepdim=True)
pixel_num[pixel_num == 0] = 1 #防止某一个instance的label 某一行或某一列没有,防止后续步骤中作为除数报错
feat = x * inst_mask#只需要该label的x信息,inst_mask为0或1.
feat = paddle.sum(paddle.sum(feat, axis =2, keepdim=True), axis=3, keepdim=True) / pixel_num if i == 0:
out = paddle.unsqueeze(feat[:,:,0,0],1) # [n,1,c]
else:
out = paddle.concat([out,paddle.unsqueeze(feat[:,:,0,0],1)],1) # inst_pool_feats.append(feat[:,:,0,0]) # [n, 64]
return out #shape = [n,inst_num,c]
def forward(self, x, input_instances):
# instances [n,1,h,w], input_instances [n,inst_nc,h,w] 注意一下这个shape
instances = paddle.argmax(input_instances, 1, keepdim=True).astype("float32") print("instance",instances.shape)
x1 = self.actvn(self.norm1(self.layer1(x,instances)))
x2 = self.actvn(self.norm2(self.layer2(x1,instances)))
x3 = self.actvn(self.norm3(self.layer3(x2,instances)))
x4 = self.actvn(self.norm4(self.layer4(x3,instances))) print("x1",x1.shape,"x2",x2.shape,"x3",x3.shape,"x4",x4.shape) #x1 [4, 64, 128, 128] x2 [4, 128, 64, 64] x3 [4, 256, 32, 32] x4 [4, 512, 16, 16]
y = self.up(self.actvn(self.norm_middle(self.middle(x4,instances))))
y1 = self.up(self.actvn(self.norm_up1(self.up1(paddle.concat([y,x3],1),instances))))
y2 = self.up(self.actvn(self.norm_up2(self.up2(paddle.concat([y1, x2], 1),instances))))
y3 = self.up(self.actvn(self.norm_up3(self.up3(paddle.concat([y2, x1], 1),instances)))) print("y",y.shape,"y1",y1.shape,"y2",y2.shape,"y3",y3.shape)# y [4, 256, 32, 32] y1 [4, 128, 64, 64] y2 [4, 64, 128, 128] y3 [4, 64, 256, 256]
scale_mu = self.scale_conv_mu(y3,instances)
scale_var = self.scale_conv_var(y3,instances)
bias_mu = self.bias_conv_mu(y3,instances)
bias_var = self.bias_conv_var(y3,instances)
scale_mus = self.instAvgPooling(scale_mu,input_instances)
scale_vars = self.instAvgPooling(scale_var,input_instances)
bias_mus = self.instAvgPooling(bias_mu,input_instances)
bias_vars = self.instAvgPooling(bias_var,input_instances) return scale_mus, scale_vars, bias_mus, bias_vars #shape都为[batch_size,instance_nc,noise_num]encoder = instanceAdaptiveEncoder(opt)
x = paddle.randn([4,3,256,256])
input_instances = paddle.randn([4,72,256,256])
encoder(x,input_instances)class Encoder_OPT:
def __init__(self):
super().__init__()
self.ngf = 64
self.semantic_nc = 2
self.no_instance = True
self.noise_nc = 108opt = Encoder_OPT()def instance_encode_z(real_image, input_instances):
s_mus, s_logvars, b_mus, b_logvars = instanceAdaptiveEncoder(opt)(real_image,input_instances)
z = [s_mus,paddle.exp(0.5 * s_logvars),b_mus,paddle.exp(0.5 * b_logvars)] return z, s_mus, s_logvars, b_mus, b_logvars
instance_nc = 2real_image = paddle.randn([4,3,256,256])
input_instances = paddle.randn([4,instance_nc,256,256])
z, s_mus, s_logvars, b_mus, b_logvars = instance_encode_z(real_image,input_instances)#s_mus, s_logvars, b_mus, b_logvars这四个return是为了计算KLDLOSSinstance [4, 1, 256, 256] x1 [4, 64, 128, 128] x2 [4, 128, 64, 64] x3 [4, 256, 32, 32] x4 [4, 512, 16, 16] y [4, 256, 32, 32] y1 [4, 128, 64, 64] y2 [4, 64, 128, 128] y3 [4, 64, 256, 256]
# KLD_loss = (KLDLoss(s_mus, s_logvars)+KLDLoss(b_mus, b_logvars)) * .opt.lambda_kld / 2instance_nc = 2noise_nc = 108noise = paddle.randn([x.shape[0], instance_nc, 2,noise_nc])def pre_process_noise( noise, z):
'''
noise: [n,inst_nc,2,noise_nc], z_i [n,inst_nc,noise_nc]
z: [s_mus,torch.exp(0.5 * s_logvars),b_mus,torch.exp(0.5 * b_logvars)]
'''
s_noise = paddle.unsqueeze(noise[:,:,0,:].multiply(z[1])+z[0],2)
b_noise = paddle.unsqueeze(noise[:,:,1,:].multiply(z[3])+z[2],2) return paddle.concat([s_noise,b_noise],2)
noise = pre_process_noise(noise,z)#这个时候得到的noise才是贯穿decoder,其中INADE的一个输入的noiseprint(noise.shape) #[4,instance_nc,2,noise][4, 2, 2, 108]
那么train的时候这个noise可以得到了,但是decoder是基于一个很小的特征图逐渐上采样的,那么这个特征图作者采取得到的方法是直接randn加linear再reshape,初始化完全是没有任何信息的。这样的方法我看来是不错的,因为实际测试的时候decoder输入的就是标准正太分布,这样就防止了训练和测试的时候输入不一致的问题,防止模型依靠这个初始特征图的结构信息.(这个特征图的处理我正在实验,好像不太好训练)
batch_size = 4z = paddle.randn(batch_size, z_dim,
dtype=torch.float32, device=input.get_device())
x = nn.Linear(opt.z_dim, 16 * 64 * sw * sh)(z)
x = x.reshape(-1, 16 * 64, self.sh, self.sw)以上就是INADE个人讲解和理解的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 518
518
























