本文是PaddleSeg代码解读第二篇,先解读数据增强代码,介绍了transforms中Compose等多个预处理与增强类的实现,它们通过__call__方法运作。再解读模型与Backbone代码,以FCN网络为例,介绍其结构及HRNet主干网络的构成模块与运作方式。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

本篇文章是PaddleSeg代码解读的第二篇,主要解读以下内容:
1.数据增强代码解读:这里主要讲解了数据处理与增强的一些常用算法。
2.模型与Backbone代码解读:这里主要讲解常用的模型以及backbone的网络与算法。
本部分主要介绍一下数据增强部分,PaddleSeg套件里把数据增强部分都定义在transforms里面,与Pytorch比较类似,这样就把一些基本的图像处理方法(缩放、归一化等)和数据增强(随机裁剪、翻转、颜色抖动)统一了,自己新增的数据增强方法也可以添加在这里。
数据增强的代码入口与Dataset一样来自Config类,在访问config对象的transfroms成员时,会根据yaml文件创建对应的对象。
比如yaml文件配置如下:
transforms:
#根据Config类部分的代码解读,我们已经了解到type的值代表了具体的类名,
#所以再找个transforms中会创建ResizeStepScaling、RandomPaddingCrop、
#RandomHorizontalFlip、RandomDistort和Normalize这个几个类。
#type后面的键值对则是构建这几个类时需要传递的参数。
- type: ResizeStepScaling
min_scale_factor: 0.5
max_scale_factor: 2.0
scale_step_size: 0.25
- type: RandomPaddingCrop
crop_size: [1024, 512] - type: RandomHorizontalFlip
- type: RandomDistort
brightness_range: 0.4
contrast_range: 0.4
saturation_range: 0.4
- type: Normalize下面我们详细介绍一下transform中具有代表性的几个预处理与数据增强的类的实现,其他的类后续可能会再补充代码解读。 相关的类都在paddleseg/transforms/transforms.py文件中定义。
首先是Compose类,它主要是多种类的集合,它保存了换一个列表用于存储图像处理与增强的方法,通过__call__方法来顺序调用,下面是具体实现。 首先是Compose的构造方法代码:
def __init__(self, transforms, to_rgb=True):
#传递进来的transforms参数需要是一个列表,列表包含了一个或者多个图像处理或者增强的方法。
if not isinstance(transforms, list): raise TypeError('The transforms must be a list!') if len(transforms) < 1: raise ValueError('The length of transforms ' + \ 'must be equal or larger than 1!')
self.transforms = transforms #记录是否需要将图片转换为RGB
self.to_rgb = to_rgb当一个类中定义了__call__方法则可以通过对象名直接执行该方法。比如P类的对象p,当执行p(parm)时,则会调用P类中的__call__方法。 transform则采取了这种方法,在所有数据预处理和增强的类中都实现了__call__方法,可以看做为匿名协议。 Compose类中的__call__方法代码如下:
def __call__(self, im, label=None):
#首先通过Opencv读取样本图片数据,保存在im中类型为float32,im是一个ndarray类型变量。
if isinstance(im, str):
im = cv2.imread(im).astype('float32') if isinstance(label, str): #通过pillow打开标签文件,这里使用的pillow原因是因为标注文件有可能是伪彩色标注,使用调色板模式,通过pillow打开
#则可以直接获取标注文件每一个像素点值为调色板中的索引,这样就可以直接定义为类别号。这样同时兼容灰度标注与伪彩色标注。
label = np.asarray(Image.open(label)) if im is None: raise ValueError('Can\'t read The image file {}!'.format(im)) #因为opencv打开的图片,像素点排序默认是BGR,这里如果需要可以转换成RGB。
if self.to_rgb:
im = cv2.cvtColor(im, cv2.COLOR_BGR2RGB) #遍历transforms列表,执行数据预处理与增强。
for op in self.transforms:
outputs = op(im, im_info, label)
im = outputs[0] if len(outputs) == 2:
label = outputs[1] #这里将图像数据的矩阵进行转置,将通道放在高度和宽度之前。
#比如一张图片为高度为480,宽度为640,通道数为3代表RGB图像。它的矩阵形状为[480, 640, 3]
#经过下面代码的转置操作则变为[3, 480, 640]
im = np.transpose(im, (2, 0, 1)) return (im, label)下面开始介绍图像预处理和增强的代码,首先是RandomHorizontalFlip类:
#通过类名可以知道,该类对图像进行随机的水平翻转。class RandomHorizontalFlip:
"""
Flip an image horizontally with a certain probability.
Args:
prob (float, optional): A probability of horizontally flipping. Default: 0.5.
"""
#构造时传入prob参数,代表概率,当随机数小于这个概率时则翻转图像。
#有prob的概率翻转图像。
def __init__(self, prob=0.5):
self.prob = prob def __call__(self, im, label=None):
if random.random() < self.prob: #进行图像翻转
im = functional.horizontal_flip(im) #如果同时传入了标签图像则都需要翻转。一般是在训练时会传入标签图像。
if label is not None:
label = functional.horizontal_flip(label) if label is None: return (im,) else: return (im, label)RandomVerticalFlip类与上一个类类似,它是对图片进行随机的垂直方向翻转。参数与RandomHorizontalFlip类一致。
class RandomVerticalFlip:
def __init__(self, prob=0.1):
self.prob = prob def __call__(self, im, label=None):
if random.random() < self.prob:
im = functional.vertical_flip(im) if label is not None:
label = functional.vertical_flip(label) if label is None: return (im,) else: return (im, label)Resize是图像处理中最常用的方法,它对样本图像和标签图像进行缩放。下面对代码进行解读。
class Resize:
# The interpolation mode
#插值方法,这里代表了不同的插值算法。
interp_dict = { 'NEAREST': cv2.INTER_NEAREST, 'LINEAR': cv2.INTER_LINEAR, 'CUBIC': cv2.INTER_CUBIC, 'AREA': cv2.INTER_AREA, 'LANCZOS4': cv2.INTER_LANCZOS4
} def __init__(self, target_size=(512, 512), interp='LINEAR'):
#验证插值方法参数是否正确,如果interp不在interp_dict字典里,同时interp的值还不是RANDOM则抛出异常。
self.interp = interp if not (interp == "RANDOM" or interp in self.interp_dict): raise ValueError("`interp` should be one of {}".format(
self.interp_dict.keys())) #验证target_size参数是否正确,只能包含两个元素,分别代码了图像的高与宽。
#如果不正确则抛出异常。
if isinstance(target_size, list) or isinstance(target_size, tuple): if len(target_size) != 2: raise ValueError( '`target_size` should include 2 elements, but it is {}'. format(target_size)) else: raise TypeError( "Type of `target_size` is invalid. It should be list or tuple, but it is {}"
.format(type(target_size))) #保存target_size为成员变量
self.target_size = target_size def __call__(self, im, label=None):
#需要保证图像的类型为ndarray,通过Opencv读取的默认是该类型,如果是标签图片通过PIL读取
#则需要通过asarray等方法转换。
if not isinstance(im, np.ndarray): raise TypeError("Resize: image type is not numpy.") #图片需要是3阶矩阵,标签图片需要新建一个维度。
if len(im.shape) != 3: raise ValueError('Resize: image is not 3-dimensional.') #如果interp为RANDOM则随机选取一种插值算法。否则使用指定的插值算法。
if self.interp == "RANDOM":
interp = random.choice(list(self.interp_dict.keys())) else:
interp = self.interp #对图像进行插值缩放。
im = functional.resize(im, self.target_size, self.interp_dict[interp]) #如果传入了标签图片数据,也需要进行缩放,这里注意的是标签图片数据只能使用INTER_NEAREST方法,否则
#会影响标签数据的准确性。
if label is not None:
label = functional.resize(label, self.target_size,
cv2.INTER_NEAREST) #返回数据。
if label is None: return (im,) else: return (im, label)下面介绍ResizeByLong类,与Resize类似,只不过在ResizeByLong中只需要制定长边的长度,然后 按比例对图像进行缩放。
class ResizeByLong:
def __init__(self, long_size):
#保存长边长度为成员变量。
self.long_size = long_size def __call__(self, im, label=None):
if im_info is None:
im_info = list()
im_info.append(('resize', im.shape[:2])) #对图片进行缩放。
im = functional.resize_long(im, self.long_size) #这里同样对标签图片缩放需要使用INTER_NEAREST算法,保证准确率。
if label is not None:
label = functional.resize_long(label, self.long_size,
cv2.INTER_NEAREST) if label is None: return (im,) else: return (im, label)ResizeStepScaling也是一个比较常用的缩放方法,前面的提到YAML配置中就是使用的该方法对样本进行数据增强, 它有三个参数min_scale_factor、max_scale_factor和scale_step_size,也是在YAML配置文件体现的,下面 具体对该类的代码进行解读。
class ResizeStepScaling:
def __init__(self,
min_scale_factor=0.75,
max_scale_factor=1.25,
scale_step_size=0.25):
#在构造方法中,主要判断一下参数的合法性,然后将参数保存为成员变量。
if min_scale_factor > max_scale_factor: raise ValueError( 'min_scale_factor must be less than max_scale_factor, '
'but they are {} and {}.'.format(min_scale_factor,
max_scale_factor))
self.min_scale_factor = min_scale_factor
self.max_scale_factor = max_scale_factor
self.scale_step_size = scale_step_size def __call__(self, im, label=None):
#如果最小的缩放因子和最大的缩放因子相等,则本次缩放的因子则会它们的值。
if self.min_scale_factor == self.max_scale_factor:
scale_factor = self.min_scale_factor #如果缩放的随机步长为0,则在最小和最大的缩放因子之间随机选择一个数。
elif self.scale_step_size == 0:
scale_factor = np.random.uniform(self.min_scale_factor,
self.max_scale_factor) #如果步长不为0,则需要计算在最大值和最小值之间包含多少个步长。
#然后将最小值和最大值之间,通过根据步长的个数,分割出数值,
#对这些数值进行随机,选择第一个元素作为本次的缩放因子。
else:
num_steps = int((self.max_scale_factor - self.min_scale_factor) /
self.scale_step_size + 1)
scale_factors = np.linspace(self.min_scale_factor,
self.max_scale_factor,
num_steps).tolist()
np.random.shuffle(scale_factors)
scale_factor = scale_factors[0] #分别将缩放因子乘以高和宽,得到新的高宽。
w = int(round(scale_factor * im.shape[1]))
h = int(round(scale_factor * im.shape[0])) #用新的高宽对图像进行缩放处理。
im = functional.resize(im, (w, h), cv2.INTER_LINEAR) #同样如果传递了标签图片数据,要使用INTER_NEAREST方法进行插值缩放保证数据准确性。
if label is not None:
label = functional.resize(label, (w, h), cv2.INTER_NEAREST) if label is None: return (im,) else: return (im, label)RandomPaddingCrop也是在前面YAML配置文件中使用的图像增强方法,下面解读一下其代码。
class RandomPaddingCrop:
def __init__(self,
crop_size=(512, 512),
im_padding_value=(127.5, 127.5, 127.5),
label_padding_value=255):
#检测构造时传入的参数正确性,并保存为成员变量。
if isinstance(crop_size, list) or isinstance(crop_size, tuple): if len(crop_size) != 2: raise ValueError( 'Type of `crop_size` is list or tuple. It should include 2 elements, but it is {}'
.format(crop_size)) else: raise TypeError( "The type of `crop_size` is invalid. It should be list or tuple, but it is {}"
.format(type(crop_size)))
self.crop_size = crop_size
self.im_padding_value = im_padding_value
self.label_padding_value = label_padding_value def __call__(self, im, label=None):
#如果传入的crop_size为整型,则需要裁减宽高都为crop_size。
if isinstance(self.crop_size, int):
crop_width = self.crop_size
crop_height = self.crop_size #如果传入的是列表或元组则分别对宽高进行赋值。
else:
crop_width = self.crop_size[0]
crop_height = self.crop_size[1]
img_height = im.shape[0]
img_width = im.shape[1] #如果图像原始宽高与需要裁减的宽高一致,则直接返回图像,不做任何处理。
if img_height == crop_height and img_width == crop_width: if label is None: return (im,) else: return (im, label) else: #计算高和宽分别需要填充的长度。
pad_height = max(crop_height - img_height, 0)
pad_width = max(crop_width - img_width, 0) #如果裁减尺寸大于图像尺寸,则对图像进行填充扩展。
if (pad_height > 0 or pad_width > 0):
im = cv2.copyMakeBorder(
im, 0,
pad_height, 0,
pad_width,
cv2.BORDER_CONSTANT,
value=self.im_padding_value) #同样对应的标签图片也需要填充。
if label is not None:
label = cv2.copyMakeBorder(
label, 0,
pad_height, 0,
pad_width,
cv2.BORDER_CONSTANT,
value=self.label_padding_value) #获得填充后的图像尺寸。
img_height = im.shape[0]
img_width = im.shape[1] #如果需要裁剪的尺寸大于0,则在img_height和crop_height的差值之间随机一个整数,作为高度裁剪的起点,
#宽度同理。
if crop_height > 0 and crop_width > 0:
h_off = np.random.randint(img_height - crop_height + 1)
w_off = np.random.randint(img_width - crop_width + 1) #以crop_height为高度、crop_width为宽度,h_off和w_off分别作为起点对图片进行裁剪。
im = im[h_off:(crop_height + h_off), w_off:(
w_off + crop_width), :] #同样,如果传递了标签图片,也需要进行裁剪,与样本图片保持一致。
if label is not None:
label = label[h_off:(crop_height + h_off), w_off:(
w_off + crop_width)] if label is None: return (im,) else: return (im, label)图像标准化是图像预处理常用的一种方法,在训练、验证和测试阶段都会使用。 使用该方法处理后会加快模型的收敛,提高模型的准确率。
下面解读该方法的代码。
class Normalize:
#构造方法需要传入RGB三个像素点的平均值和标准差,一般通过统计数据集中的像素点的值获得。
def __init__(self, mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)):
#这里保存均值和标准差,同时需要验证参数合法性。
self.mean = mean
self.std = std if not (isinstance(self.mean, (list, tuple)) and isinstance(self.std, (list, tuple))): raise ValueError( "{}: input type is invalid. It should be list or tuple".format(
self)) from functools import reduce if reduce(lambda x, y: x * y, self.std) == 0: raise ValueError('{}: std is invalid!'.format(self)) def __call__(self, im, label=None):
#对均值和标准差的维度进行变换,方便与图形进行计算,变换后的维度为[1,1,3]
mean = np.array(self.mean)[np.newaxis, np.newaxis, :]
std = np.array(self.std)[np.newaxis, np.newaxis, :] #对图像进行标准化处理。
im = functional.normalize(im, mean, std) if label is None: return (im,) else: return (im, label)以上就是对常用的图像预处理与增强部分的代码解读。
相信随着PaddleSeg套件的代码不断完善,处理和增强的方法会逐渐增多,以后也会将新增的方法的代码解读添加到本章节中。
本章节将介绍PaddleSeg的核心部分,分割模型和主干网络部分,在yaml配置文件中有以下定义:
#模型信息model:
#模型的类型FCN
type: FCN
#使用的主干网络为HRNet
backbone:
type: HRNet_W18
#主干网络的预训练模型的下载地址。
pretrained: https://bj.bcebos.com/paddleseg/dygraph/hrnet_w18_ssld.tar.gz
#模型支持的类别为19种。
num_classes: 19
#模型的预训练地址,这里为空
pretrained: Null
#这个是创建模型时需要传入的参数,该参数指定FCN使用backbone返回的哪个特征图。backbone可以根据不同的块返回不同尺度的特征图。
backbone_indices: [-1]以上配置文件定义了一个最基本的FCN网络。首先我们来介绍一下FCN网络。 FCN网络全称为Fully Convolutional Networks,按字面意思就是全部都是卷积的网络,没有全连接层。FCN是在论文《Fully convolutional networks for semantic segmentation》提出的。 FCN之所以可以对图像进行分割,是因为实现了像素级分类。试想一下,在一张图片里每一个像素点就被分为某一个类别,这样整张图像自然就被分割成不同的区域了。 下面贴一张论文中FCN结构图:

FCN网络的输入是RGB三通道的图像数据,例如形状为[224,224,3]的图像数据,输出的是每一个像素点类别,数据形状可以是[n_classes, 224, 224]。 在图像分类任务中,网络的最顶层是一个全连接网络,代表了图像的类别。而在图像分割任务中,最后需要输出的是一个与输入图像尺寸相同的分割图像。要实现这个目的我们需要做以下两方面的处理:
下面介绍一下这三种方法具体实现方法。
1.双线性插值。
将一个小图像变成为一个大图像,一般都是在像素点之间插入一些点来扩充图像,但是插入的点的像素值如何确定是一个问题,在采样算法中,有多种插值的算法,这里我们介绍一种常用的双线性插值方法。这种方法不但计算比较简单,同时效果也不错。 假如有以下4个点Q11、Q12、Q21和Q22。想在坐标为(x,y)的位置插入一个P点。那如何确定P点的像素值呢?
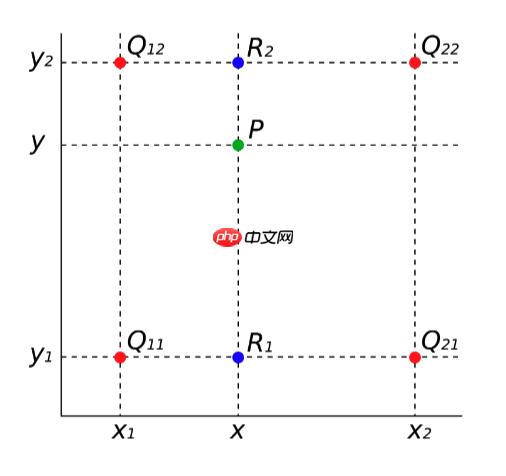
首先我们做第一次插值,x方向插值计算出图中R1和R2的像素值。 以计算R1的值为例,可以从图中观察到,点R1在X方向上,位于Q11和Q21之间,可以认为R1的值同时受Q11和Q21影响,R1距离Q11稍微近一些,那R1的像素值就受Q11影响比较大,受Q21的影响就比较少,所以根据R1距两点的距离可以得出以下公式:
v(R1)=x2−x1x2−xv(Q11)+x2−x1x−x1v(Q21)
同理计算R2的值的公公式如下:
v(R2)=x2−x1x2−xv(Q12)+x2−x1x−x1v(Q22)
然后我们在做第二次线性插值得出P点的像素值,与之前计算R1和R2的值类似,只不过这是在Y方向上进行计算,公式如下:
v(P)=y2−y1y2−yv(R1)+y2−y1y−y1v(R2)
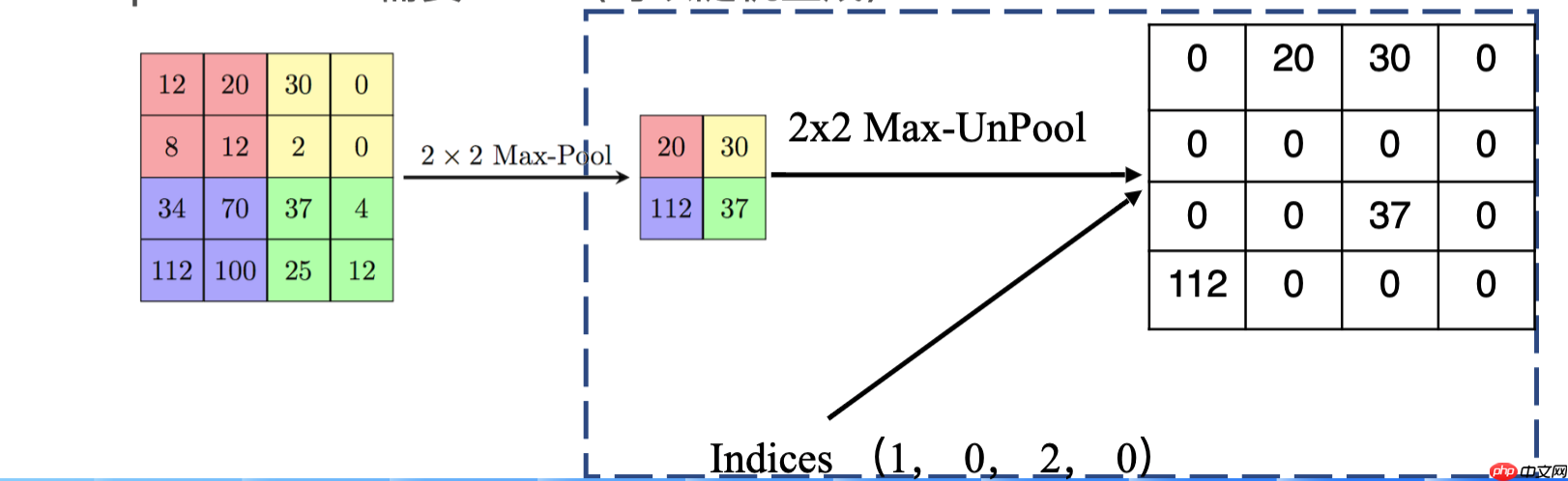
2.反池化 这个一般用的比较少,因为需要记录池化时的索引号,如果没有记录也可以随机生成索引号。这个实现比较简单,过程如下图:
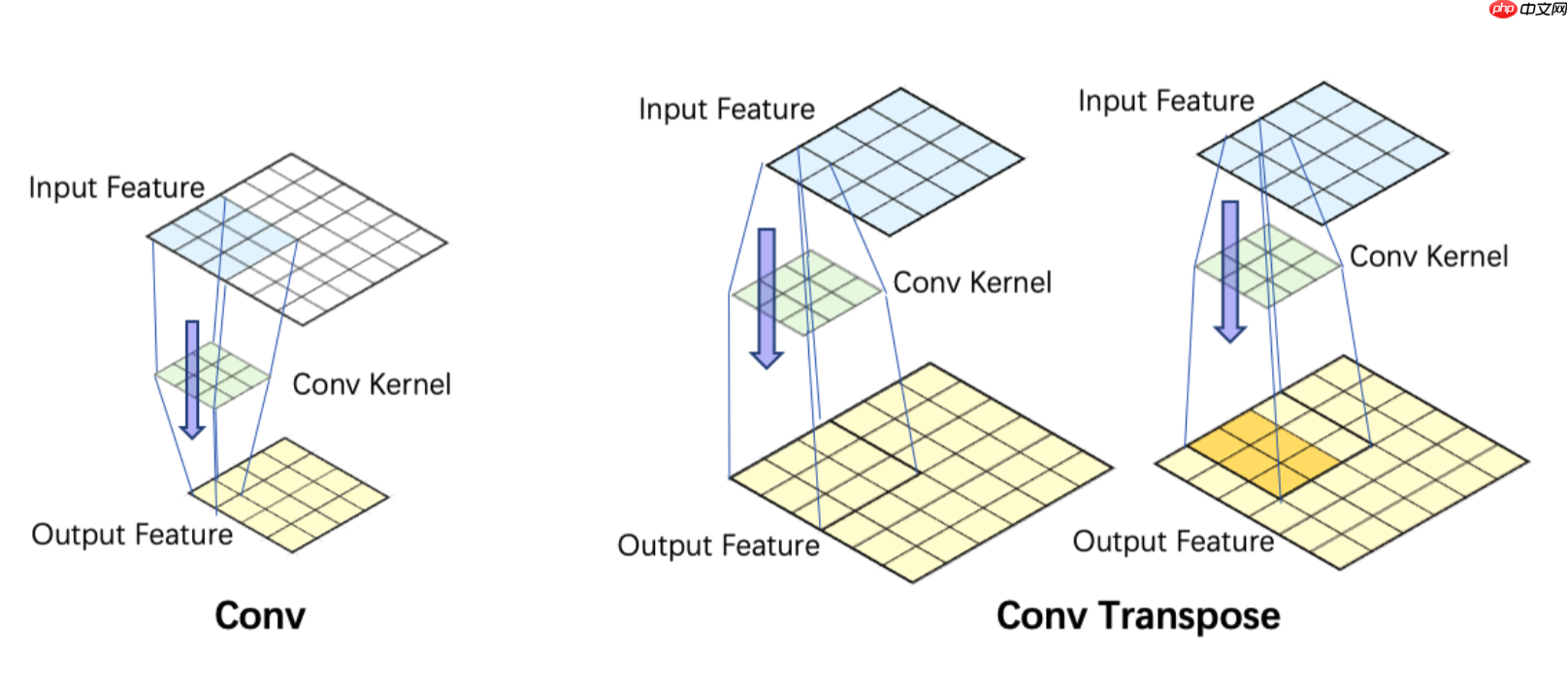
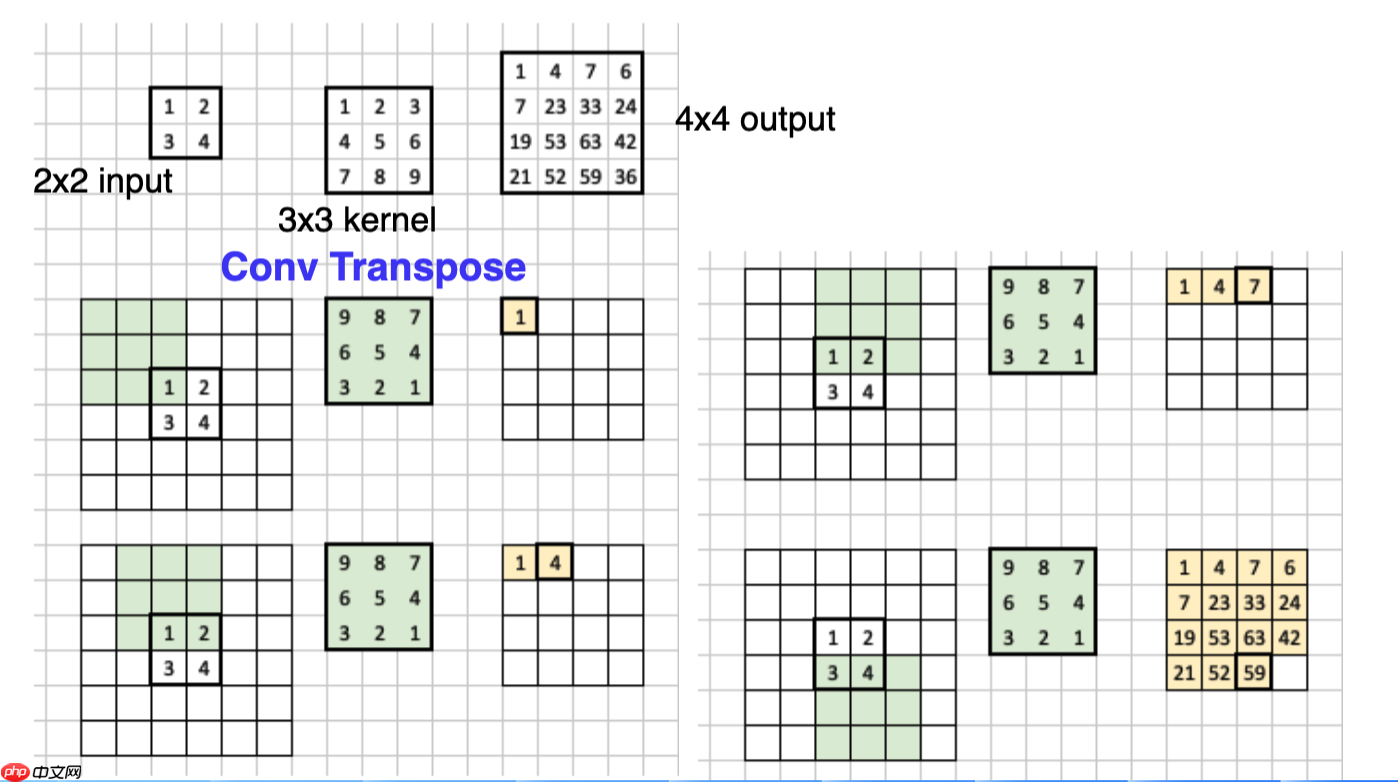
3.转置卷积(也叫反卷积) 正常的卷积操作,是将图像越卷越小,而转置卷积则是将卷积核进行选择180度,然后对图像进行padding之后进行卷积操作,最后得到一个大尺寸的特征图,具体操作如下。
paddleseg套件中的FCN网络架构如下:
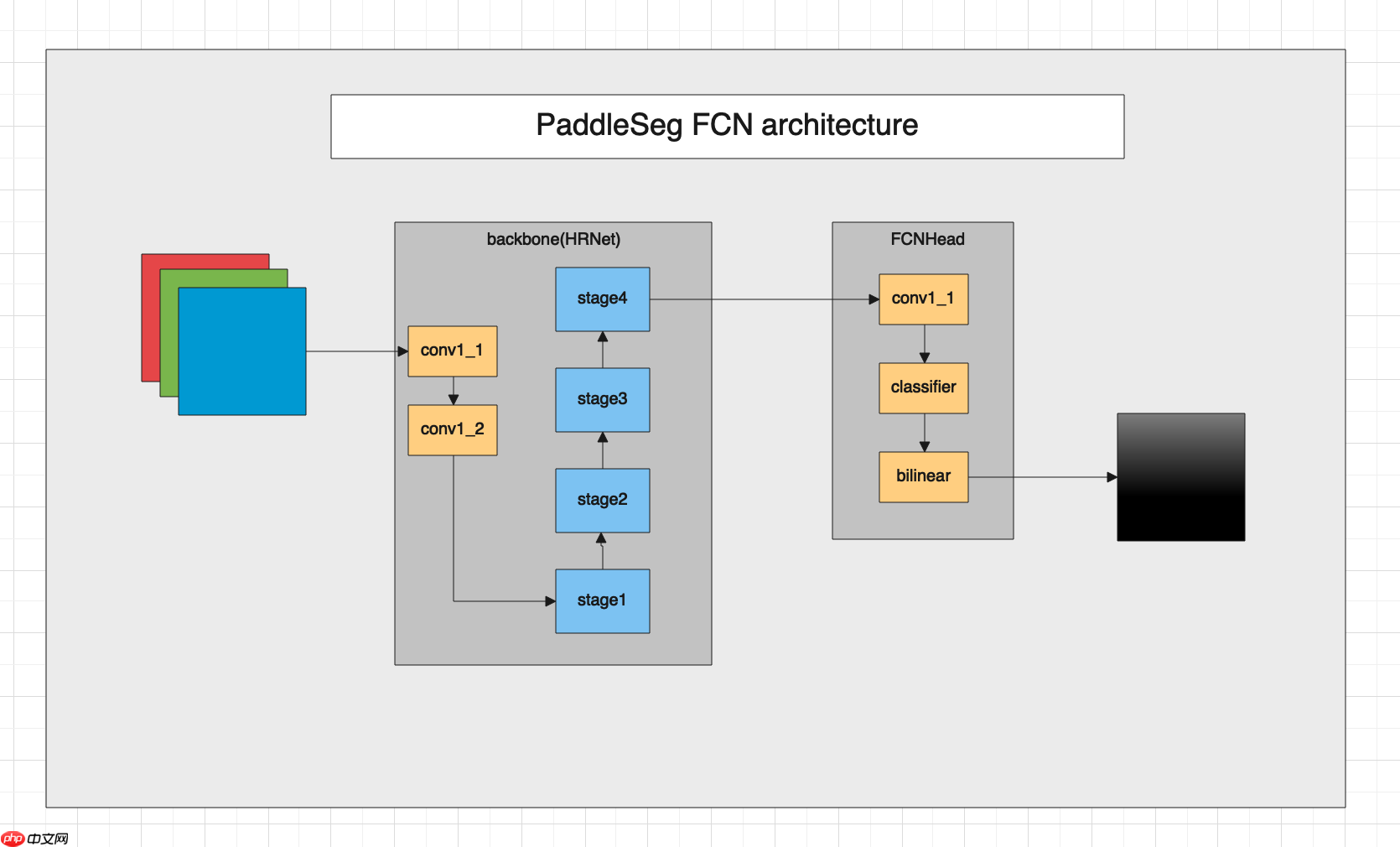
下面我们来看下FCN的代码,FCN定义在paddleseg/models/fcn.py文件中。
在FCN文件中有个FCNHead的类,它是FCN网络的最终输出模块,首先我们先看看它的实现代码以及解读。
class FCNHead(nn.Layer):
def __init__(self,
num_classes,
backbone_indices=(-1, ),
backbone_channels=(270, ),
channels=None):
super(FCNHead, self).__init__() #类别数
self.num_classes = num_classes #使用backbone返回特征列表的索引号,backbone可以将不同block的特征图组成一个列表返回。
self.backbone_indices = backbone_indices #backbone返回特征图的通道数
if channels is None:
channels = backbone_channels[0] #定义一个卷积核为1x1,带有BN层,激活函数为Relu的卷积层。
self.conv_1 = layers.ConvBNReLU(
in_channels=backbone_channels[0],
out_channels=channels,
kernel_size=1,
padding='same',
stride=1) #定义一个卷积核为1x1的卷积层,输出通道为分类数,作为分类器。
self.cls = nn.Conv2D(
in_channels=channels,
out_channels=self.num_classes,
kernel_size=1,
stride=1,
padding=0)
self.init_weight() #正向传播函数,在动态图模型中,重写该函数,将前向运算过程写在这里面。
def forward(self, feat_list):
logit_list = [] #使用backbone_inices中的索引号,取出backbone返回的特征图
x = feat_list[self.backbone_indices[0]] #进行1x1卷积运算
x = self.conv_1(x) #经过分类器,得到通道数为分类数量的特征图。
logit = self.cls(x) #为了兼容返回多个特征图的backbone,这里即使只有一个logit也放在一个列表当中返回。
logit_list.append(logit) return logit_list #初始化参数
def init_weight(self):
for layer in self.sublayers(): if isinstance(layer, nn.Conv2D):
param_init.normal_init(layer.weight, std=0.001) elif isinstance(layer, (nn.BatchNorm, nn.SyncBatchNorm)):
param_init.constant_init(layer.weight, value=1.0)
param_init.constant_init(layer.bias, value=0.0)下面来看一下FCN的模型,代码如下:
class FCN(nn.Layer):
def __init__(self,
num_classes, #类别数目
backbone, #主干网络对象
backbone_indices=(-1, ), #主干网络输出特征图的id
channels=None, #通道数
align_corners=False, #对特征图进行缩放的参数
pretrained=None): #预训练模型的url或者路径
super(FCN, self).__init__() #保存backbone模型
self.backbone = backbone #根据backbone的索引号,获取backbone中的特征图的通道数。
backbone_channels = [
backbone.feat_channels[i] for i in backbone_indices
] #定义一个head.
self.head = FCNHead(num_classes, backbone_indices, backbone_channels,
channels) #保存上采样参数。
self.align_corners = align_corners
self.pretrained = pretrained #初始化参数
self.init_weight() def forward(self, x):
#将输入图片送backbone运算,得到特征图列表,在FCN中,只有一个特征图。
feat_list = self.backbone(x) #将特征图送入head进行运算得到通道数为类别数的特征图。
logit_list = self.head(feat_list) #对特征图进行上采样,得到与输入图像尺寸一致的分割图,这里每一个像素都自己的分类,通道数与分类数一致。
return [
F.interpolate(
logit,
x.shape[2:],
mode='bilinear',
align_corners=self.align_corners) for logit in logit_list
] #初始化参数
def init_weight(self):
if self.pretrained is not None:
utils.load_entire_model(self, self.pretrained)下面我们介绍一下主干网络HRNet的结构,HRNet可以分为4个部分,首先我们看一下第一部分的结架构图。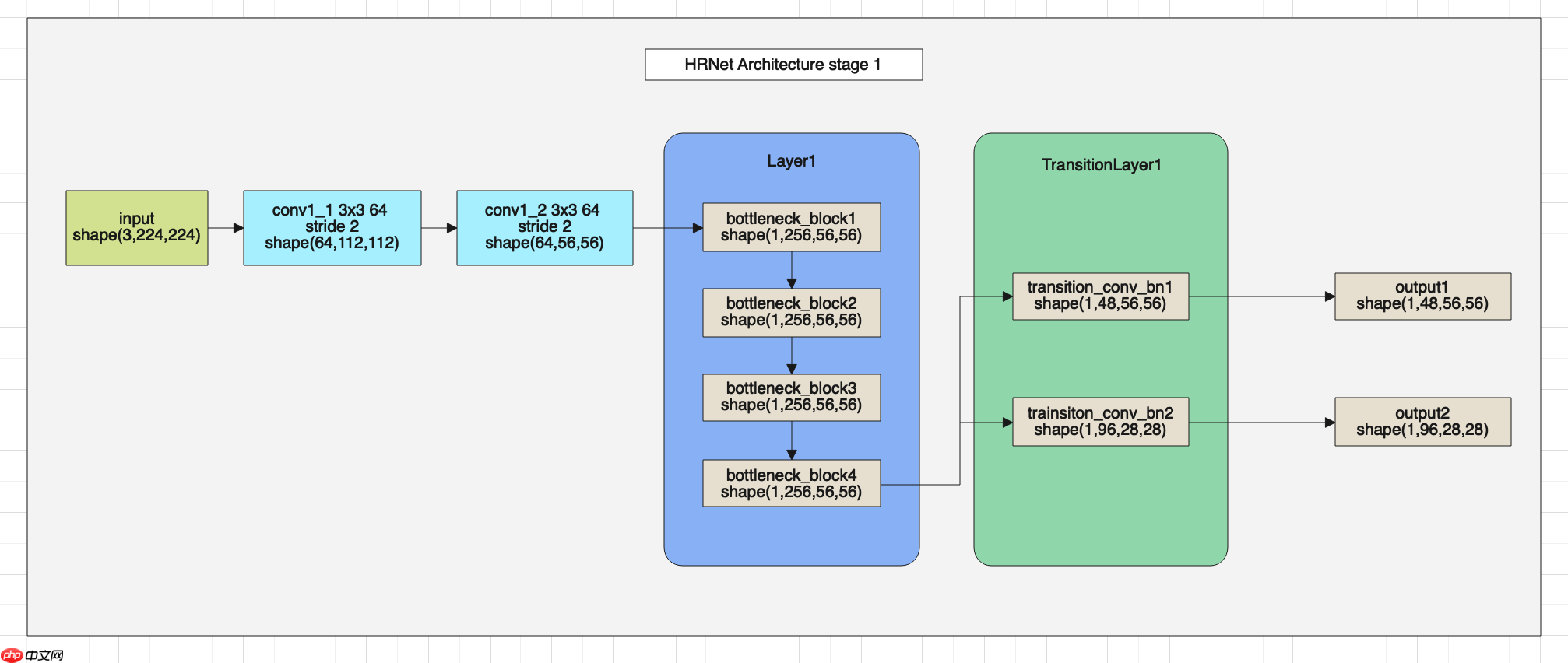
HRNet网络的第二部分架构图如下。
HRNet网络的第三部分架构图如下。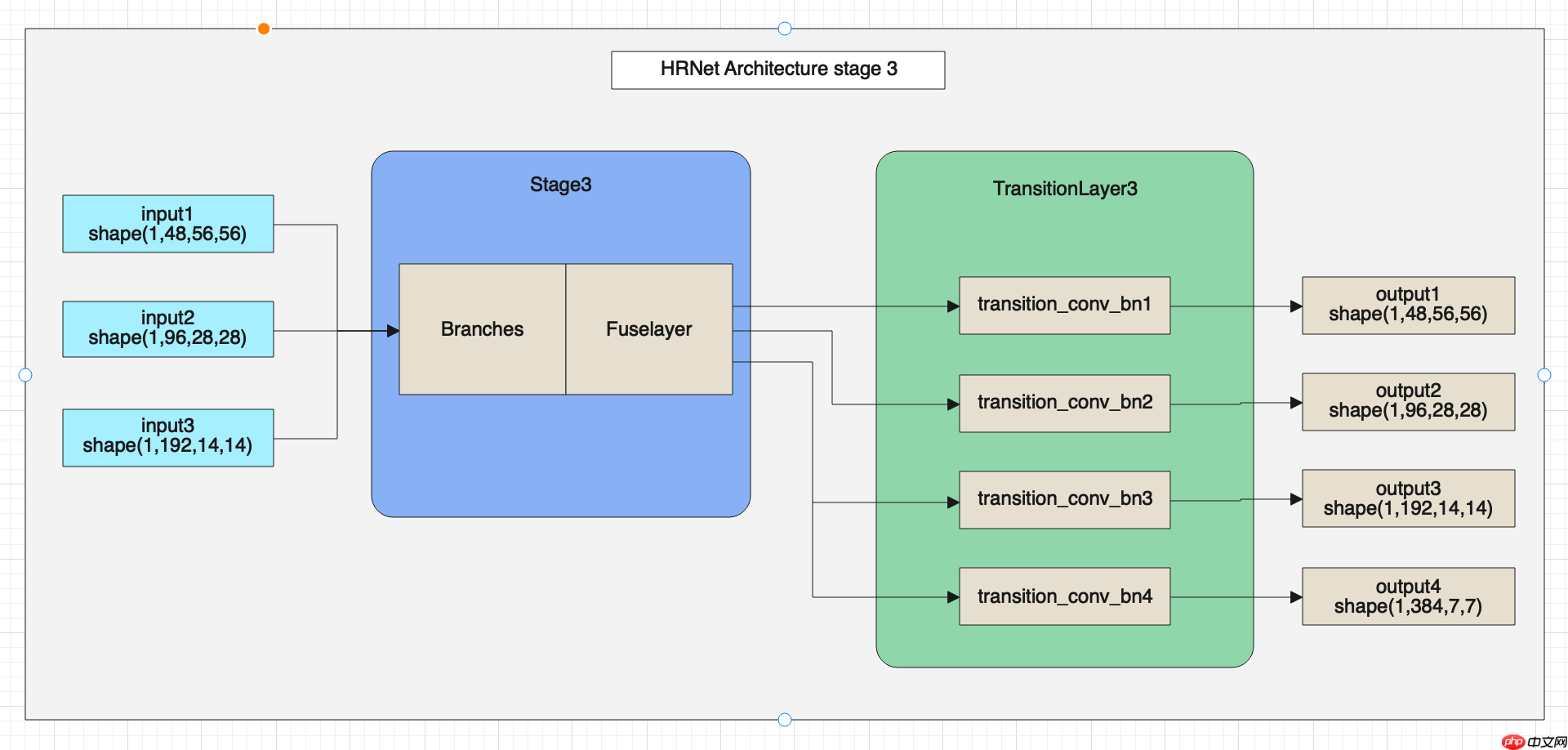
HRNet网络的第四部分架构图如下。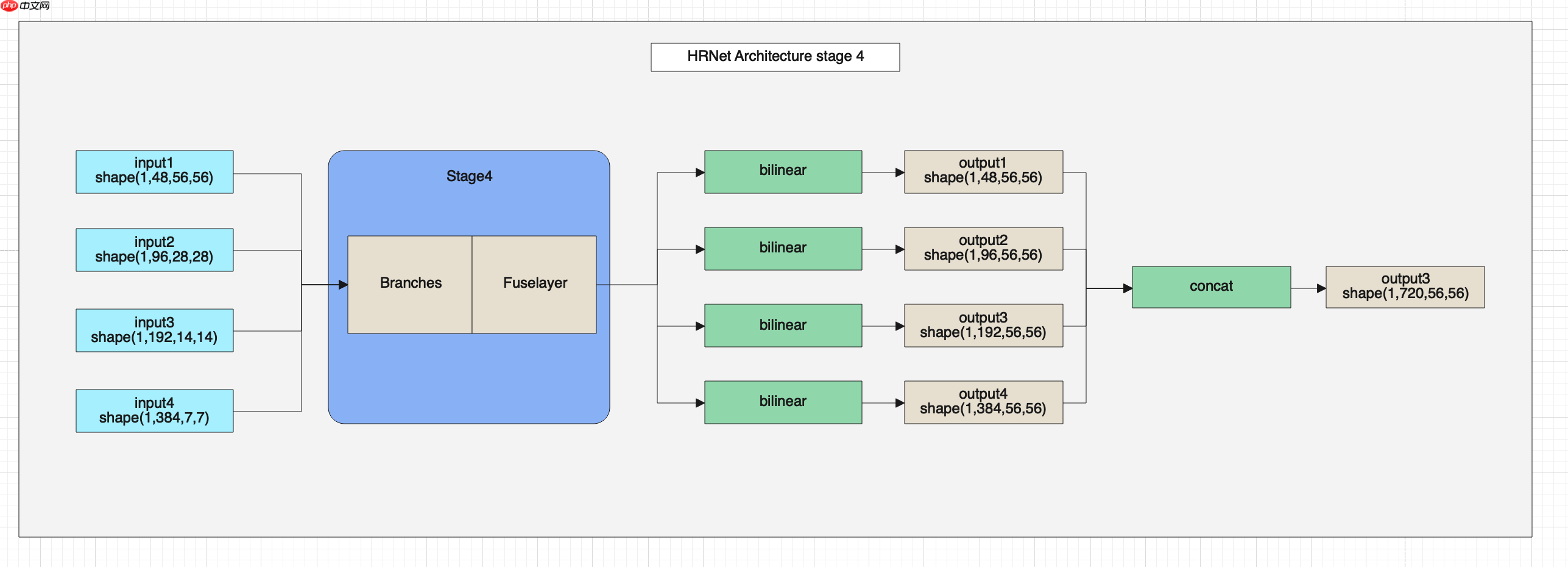
HRNet的网络整体架构如上图所示,在图中可以看出HRNet由BottleneckBlock、Branches和FuseLayer构成,下面我们详细介绍一下这三个模块的架构与代码。 首先我们看一下BottlenneckBlock的架构图:
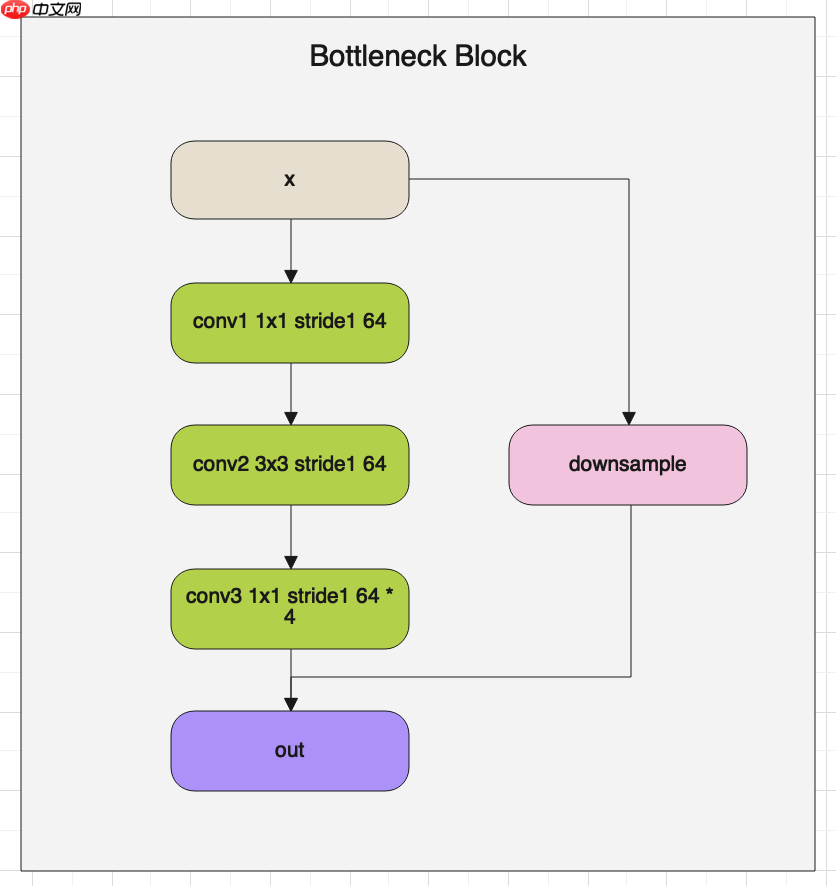
BottlenneckBlock就像名字一样,将特征图通道数固定到某一个值后,然后在放大,使通道数像一个瓶颈一样,上面细下面宽。 下面解读一下BottlenneckBlock的源代码:
class BottleneckBlock(nn.Layer):
def __init__(self,
num_channels,#输入通道数
num_filters, #卷积核数量
has_se, #是否使用SELayer stride=1, #卷积核步长 downsample=False, #是否开启下采样 name=None): #参数名称
super(BottleneckBlock, self).__init__()
self.has_se = has_se
self.downsample = downsample
#定义卷积,将特征图的通道数设置为num_filters
self.conv1 = layers.ConvBNReLU( in_channels=num_channels, out_channels=num_filters, kernel_size=1, padding='same', bias_attr=False)
#定义第二层卷积,将特征图的通道数设置为num_filters,这里kernel_size不同。
self.conv2 = layers.ConvBNReLU( in_channels=num_filters, out_channels=num_filters, kernel_size=3, stride=stride, padding='same', bias_attr=False)
#定义1x1卷积,放大特征图的通道数量
self.conv3 = layers.ConvBN( in_channels=num_filters, out_channels=num_filters * 4, kernel_size=1, padding='same', bias_attr=False)
#一般第一个bottleneck Block需要做一个下采样。 if self.downsample:
self.conv_down = layers.ConvBN( in_channels=num_channels, out_channels=num_filters * 4, kernel_size=1, padding='same', bias_attr=False)
if self.has_se:
self.se = SELayer( num_channels=num_filters * 4, num_filters=num_filters * 4, reduction_ratio=16, name=name + '_fc')
def forward(self, x):
#按顺序进行前向计算
residual = x
conv1 = self.conv1(x)
conv2 = self.conv2(conv1)
conv3 = self.conv3(conv2) if self.downsample:
residual = self.conv_down(x) if self.has_se:
conv3 = self.se(conv3)
#与残差相加
y = conv3 + residual
y = F.relu(y)
return y在每个stage之前都有个TransitionLayer,该层主要是从输入的特征图列表中,取出尺寸最小的特征图进行下采样,增加一个特征图分支。 TransitionLayer架构图可参考HRNet的总体架构图。
TransitionLayer层的代码解读如下:
class TransitionLayer(nn.Layer):
def __init__(self, in_channels, out_channels, name=None):
super(TransitionLayer, self).__init__() #由于经过TransitionLayer会多出一路分支,所以一般num_out比num_in要大
num_in = len(in_channels)
num_out = len(out_channels)
self.conv_bn_func_list = [] #需要num_out个特征图作为输出,使用循环创建num_out个输出。
for i in range(num_out):
residual = None
#在i小于等于输入的特征图数量时,可以直接做一个3x3的卷积作为输出。
if i < num_in: if in_channels[i] != out_channels[i]:
residual = self.add_sublayer( "transition_{}_layer_{}".format(name, i + 1),
layers.ConvBNReLU(
in_channels=in_channels[i],
out_channels=out_channels[i],
kernel_size=3,
padding='same',
bias_attr=False)) #在i大于输入特征图数量时,需要新创建一个特征图,这里使用stride=2的卷积下采样一个特征图作为输出。
else:
residual = self.add_sublayer( "transition_{}_layer_{}".format(name, i + 1),
layers.ConvBNReLU(
in_channels=in_channels[-1],
out_channels=out_channels[i],
kernel_size=3,
stride=2,
padding='same',
bias_attr=False))
self.conv_bn_func_list.append(residual) def forward(self, x):
outs = [] #对输入的特征图进行卷积运算。
for idx, conv_bn_func in enumerate(self.conv_bn_func_list): if conv_bn_func is None:
outs.append(x[idx]) else: if idx < len(x): #对原有的输入特征图进行卷积操作,并加入输出列表。
outs.append(conv_bn_func(x[idx])) else: #新建一个特征图,使用输入特征图中尺寸最小,使用卷积进行下采样生成新的特征图,加入到输出列表中。
outs.append(conv_bn_func(x[-1])) return outs在Stage层中会用到两个层一个是Branches,另外一个是FuseLayers。
首先我们先来看一下Branches,它的架构图如下:
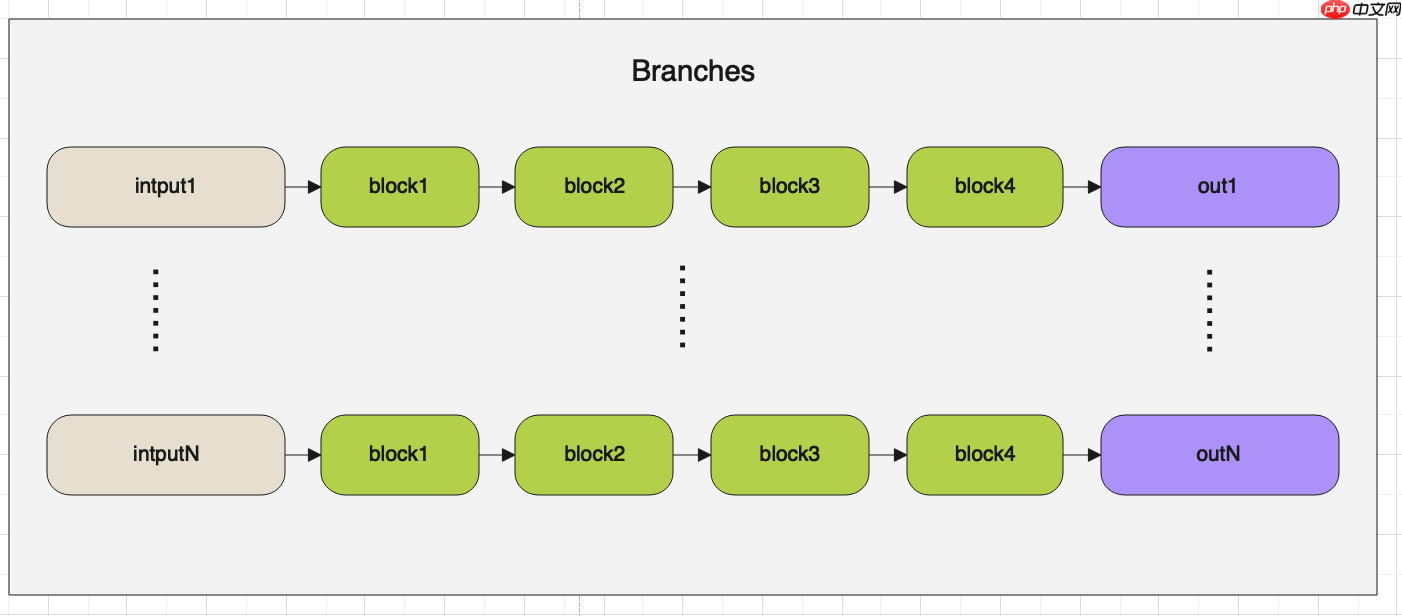
Branches的代码如下:
class Branches(nn.Layer):
def __init__(self,
num_blocks, #block数量
in_channels, #输入通道数
out_channels, #输出通道数
has_se=False,
name=None):
super(Branches, self).__init__()
self.basic_block_list = [] #经过TransitionLayer后,会被分成不同分辨率和通道数的多路特征图,这里根据特征的路数,分别进行卷积操作。
#每一路都有自己的block list。
for i in range(len(out_channels)):
self.basic_block_list.append([]) for j in range(num_blocks[i]):
in_ch = in_channels[i] if j == 0 else out_channels[i]
basic_block_func = self.add_sublayer( "bb_{}_branch_layer_{}_{}".format(name, i + 1, j + 1),
BasicBlock(
num_channels=in_ch,
num_filters=out_channels[i],
has_se=has_se,
name=name + '_branch_layer_' + str(i + 1) + '_' + str(j + 1)))
self.basic_block_list[i].append(basic_block_func) def forward(self, x):
outs = [] #遍历输入的多路特征图,执行每一路各自的卷积运算。
for idx, input in enumerate(x):
conv = input
for basic_block_func in self.basic_block_list[idx]:
conv = basic_block_func(conv)
outs.append(conv) return outs经过Branches模块卷积运算后,就进入了FuseLayers。FuseLayers的主要作用是将不同尺度的特征图进行融合。按顺序从特征图列表中取出一个特征图, 然后与其他特征图比较,遇到尺寸比自己小的特征图,则将小特征图进行上采样,然后与自己相加。遇到尺寸比自己大的特征图,则使用stride=2的卷积对 特征图进行下采样,然后与自己相加。
FuseLayer的架构图如下:
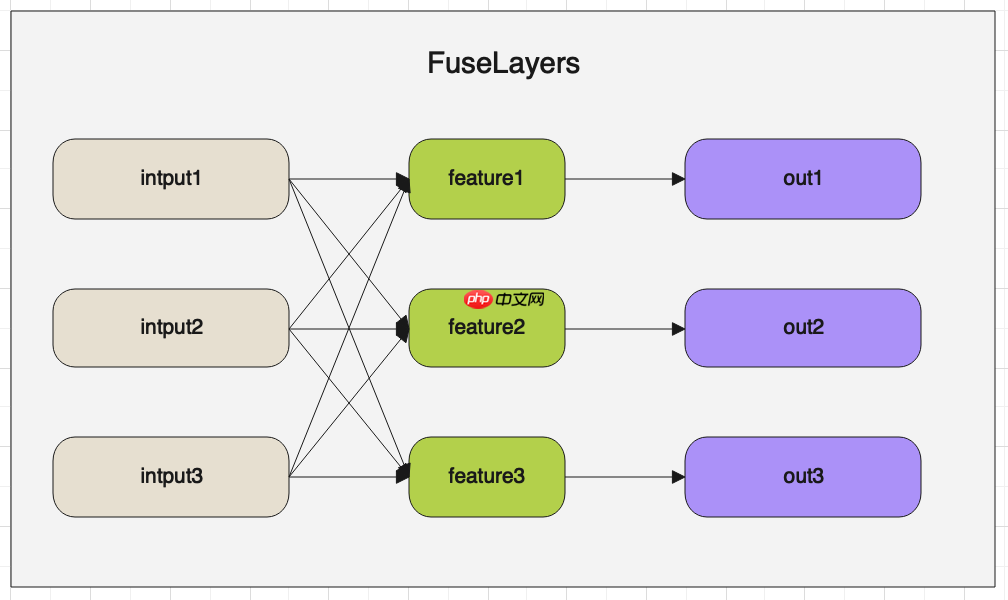
下面解读FuseLayer的代码:
class FuseLayers(nn.Layer):
def __init__(self,
in_channels,
out_channels,
multi_scale_output=True,
name=None,
align_corners=False):
super(FuseLayers, self).__init__()
self._actual_ch = len(in_channels) if multi_scale_output else 1
self._in_channels = in_channels
self.align_corners = align_corners
self.residual_func_list = [] #使用for循环遍历特征图列表
for i in range(self._actual_ch): #双重循环,进行特征图比较,下标值大的特征图的尺寸小。
for j in range(len(in_channels)): #遇到下标大的特征图,则说明特征图尺寸小,此处添加一个1x1卷积,进行通道数的统一。
if j > i:
residual_func = self.add_sublayer( "residual_{}_layer_{}_{}".format(name, i + 1, j + 1),
layers.ConvBN(
in_channels=in_channels[j],
out_channels=out_channels[i],
kernel_size=1,
padding='same',
bias_attr=False))
self.residual_func_list.append(residual_func) #遇到下标小的特征图,则说明特征图尺寸大,则需要进行创建stride=2的卷积进行1/2的下采样。
elif j < i:
pre_num_filters = in_channels[j] #因为遇到的j下标特征图可能是当前特征图的2、4、8倍,所以需要使用循环创建多个卷积进行下采样。
for k in range(i - j): if k == i - j - 1:
residual_func = self.add_sublayer( "residual_{}_layer_{}_{}_{}".format(
name, i + 1, j + 1, k + 1),
layers.ConvBN(
in_channels=pre_num_filters,
out_channels=out_channels[i],
kernel_size=3,
stride=2,
padding='same',
bias_attr=False))
pre_num_filters = out_channels[i] else:
residual_func = self.add_sublayer( "residual_{}_layer_{}_{}_{}".format(
name, i + 1, j + 1, k + 1),
layers.ConvBNReLU(
in_channels=pre_num_filters,
out_channels=out_channels[j],
kernel_size=3,
stride=2,
padding='same',
bias_attr=False))
pre_num_filters = out_channels[j]
self.residual_func_list.append(residual_func) def forward(self, x):
outs = []
residual_func_idx = 0
for i in range(self._actual_ch):
residual = x[i]
residual_shape = residual.shape[-2:] for j in range(len(self._in_channels)): if j > i: #对特征图进行上采样
y = self.residual_func_list[residual_func_idx](x[j])
residual_func_idx += 1
y = F.interpolate(
y,
residual_shape,
mode='bilinear',
align_corners=self.align_corners) #与当前i下标的特征图进行融合
residual = residual + y elif j < i:
y = x[j] #对特征图进行下采样
for k in range(i - j):
y = self.residual_func_list[residual_func_idx](y)
residual_func_idx += 1
#与当前i下标的特征图进行融合
residual = residual + y #对特征图进行relu运算
residual = F.relu(residual) #将特征图添加到输出列表。
outs.append(residual) return outs以上就是PaddleSeg代码解读-数据增强与模型结构解读的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 222
222
























